面向从业者
2022 年 5 月 6 日
新版本:Anaconda Distribution 现在支持 M1

随着数据科学的成熟,它正在逐渐揭开神秘面纱,这在很多方面都是一件好事。 随着越来越多的组织看到他们在数据科学能力方面的投资回报,商业领袖们对这个领域有了更现实的看法。 但是,尽管有些人可能对数据科学能做什么有了更细致的理解,但很少有人理解数据科学实际上是如何完成的。 因此,即使其实践者变得不可或缺,但对于许多人来说,这个领域仍然是一个“黑匣子”。
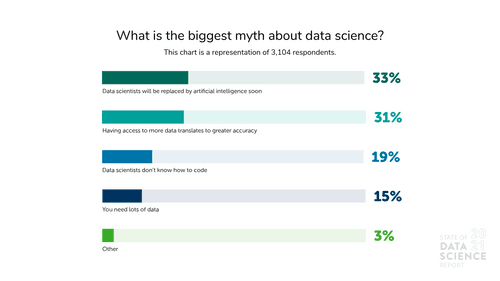
这是我们2021 年数据科学状况报告中的一项发现,在该报告中,我们要求来自 140 多个国家的 4,000 多名数据从业者说出他们认为数据科学领域最大的误解是什么。 结果表明,对于高管层和其他利益相关者而言,实践和专业有时仍然是不透明的。 为了使数据科学能够继续发挥其巨大的潜力,我们必须纠正组织领导者持有的错误假设。
在这篇文章中,我们将介绍今年数据科学状况报告中引用的最大误解,并附带解释以帮助消除这些误解。
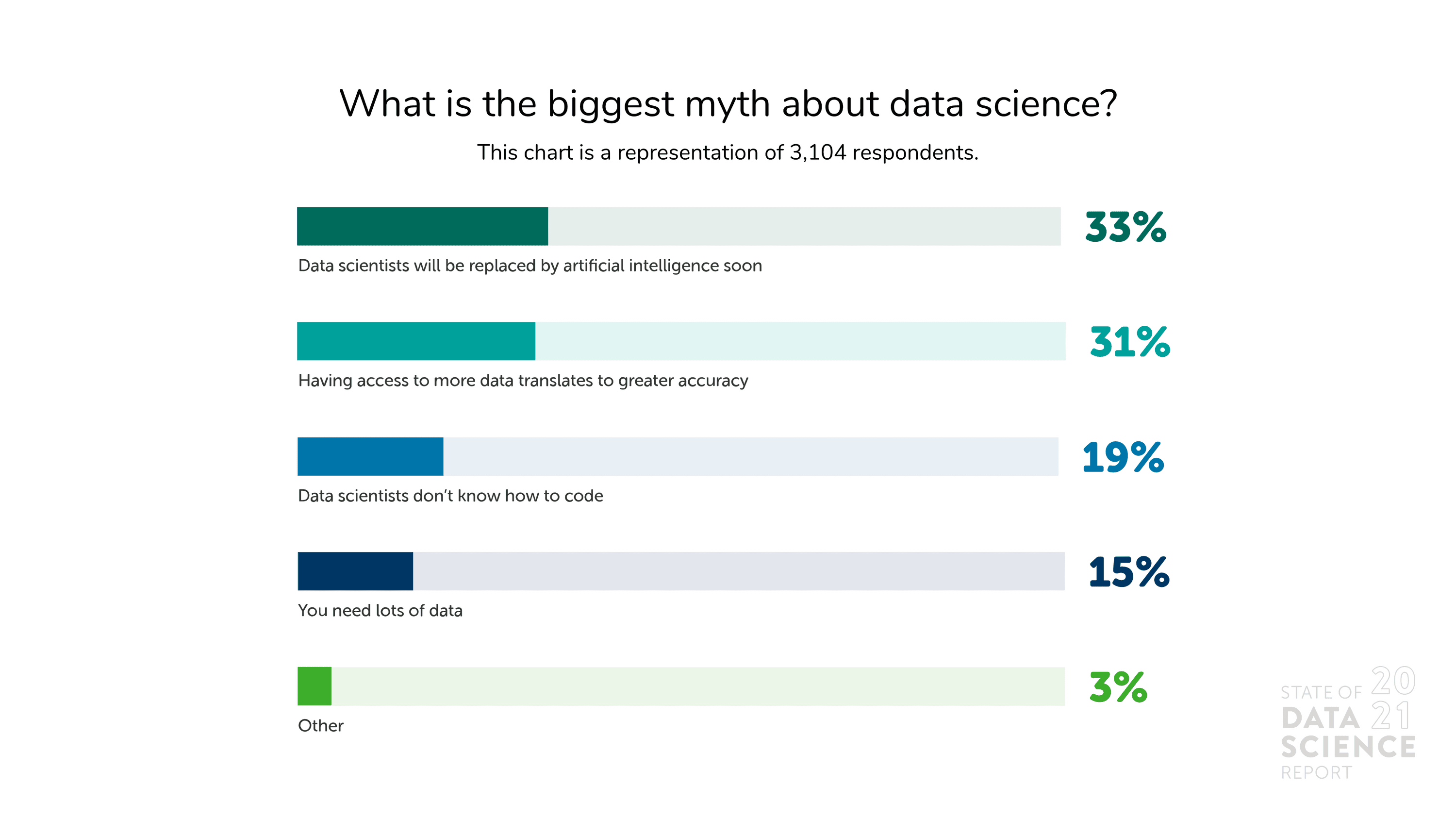
许多公司认为,在收集数据时,数量应该放在首位。 考虑到研究和调查过程通常会教导,较大的样本量将有助于得出更好的结论,这并不令人意外。 但是,随着越来越多的企业将分析应用于其决策,对更大量数据的需求正在上升。 囤积大量数据真的能提高性能吗?
从业者说不。 当被问及数据科学领域最大的误解是什么时,31% 的受访者表示,这是认为拥有更多数据可以转化为更高的准确性的观点。 另有 15% 的受访者选择“你需要大量数据”作为对数据科学的最大误解。 深入和广泛的训练数据池确实有好处,例如解决方差问题。 但是,更多的数据不一定能解决其他问题,例如偏差,也不能替代更传统的分析。 拥有最先进数据科学能力的公司已经知道这一点。
那么,企业应该将数据工作重点放在哪里呢? 正如俗话所说,质量胜于数量。 组织不应问数据是否足够,而应问他们是否为团队提供了用于建模的干净、相关且有用的数据。 事实上,正如令人失望的早期努力部署 AI 对抗 COVID-19 所表明的那样,大量低质量数据可能会导致嘈杂的结果和糟糕的见解。 如果公司优先考虑更强大的数据管理实践和更好的沟通,他们会做得更好,也会让数据科学家更快乐。
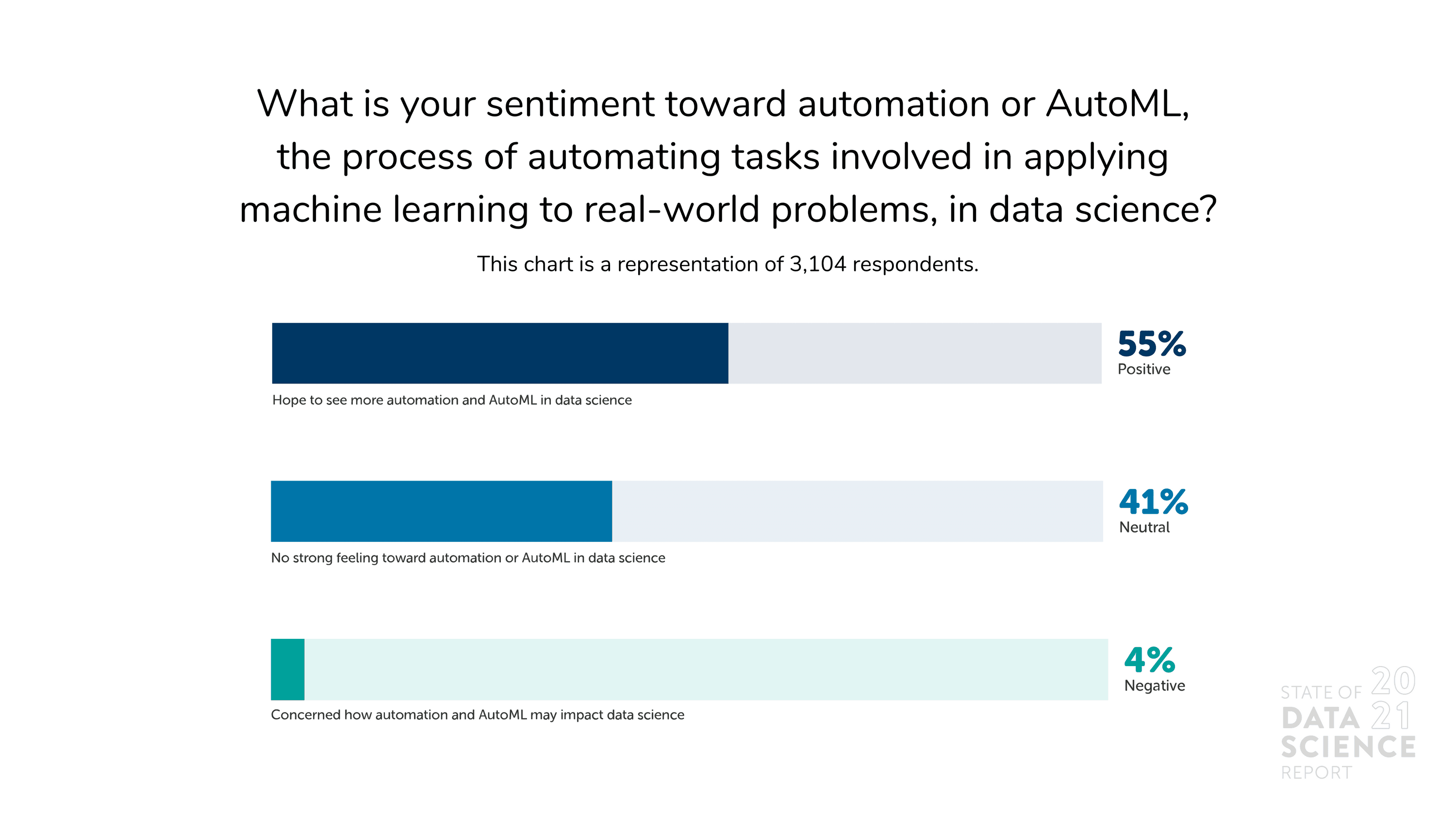
在经历了近两年因疫情中断的工厂车间和混乱的供应链之后,现在又加上紧张的劳动力市场,各行各业的高管都在转向自动化的承诺。 有些人可能会认为,数据科学是当今许多自动化的基础,是下一波 AI 驱动的颠覆的天然候选者。 但这种情况似乎不太可能:在我们调查中,33% 的受访者认为最大的误解是数据科学家很快将被 AI 取代。
似乎很少有数据科学家担心机器会取代他们。 相反,他们认为数据科学和 AI的结合为自动化提供了一个机会,可以帮助处理容易重复的任务,从而释放更多资源用于需要人工干预、解释和解决问题的工作。 简而言之,自动化将使人们能够开发更复杂的模型或算法,并减少在日常工作上花费的时间。 因此,不足为奇的是,在我们调查中,只有 4% 的受访者对 AutoML 持负面看法,而 55% 的受访者对其持积极态度。
数据科学仍然是一个新兴领域,许多组织现在才开始招聘专门的数据科学人才。 数据科学家通常与组织内的其他“技术”员工归为一类。 与软件工程师相比,人们可能会倾向于认为数据科学家不知道如何使用代码。 但请不要误会:绝大多数数据科学家也是程序员,只是类型略有不同。 在接受调查的人中,19% 的人将“数据科学家不知道如何编码”列为关于数据科学的最大误解。
数据科学家和软件工程师之间的区别在于他们编码的方式、时间和原因。 对于数据科学家来说,Python 通常是他们工具箱中的一项基本技能,用于从数据集中提取见解。 他们正在使用其数据管道和机器学习模型的代码来查询数据、设计特征以及构建和部署模型。 相比之下,软件工程师主要使用代码进行产品开发,通常侧重于基础设施、自动化、测试和维护。 即便如此,由于成为软件工程师需要掌握各种技能,因此某些技能最终会与数据科学家的技能重叠——这些群体之间的共同点比许多人意识到的要多。
随着数据科学家不断寻求更有效地与其他业务部门整合,在可行的情况下,花时间消除这些常见的误解至关重要。 提高对数据科学家工作方式的认识可以帮助改进从模型预测的准确性到招聘填补空缺职位的候选人的质量等各个方面。
您认为还有其他数据科学误解需要消除吗? 请在 Twitter 上告诉我们。
与我们的专家之一交流,为您的 AI 之旅找到解决方案。
