Excel 中的 Python
2024 年 10 月 9 日
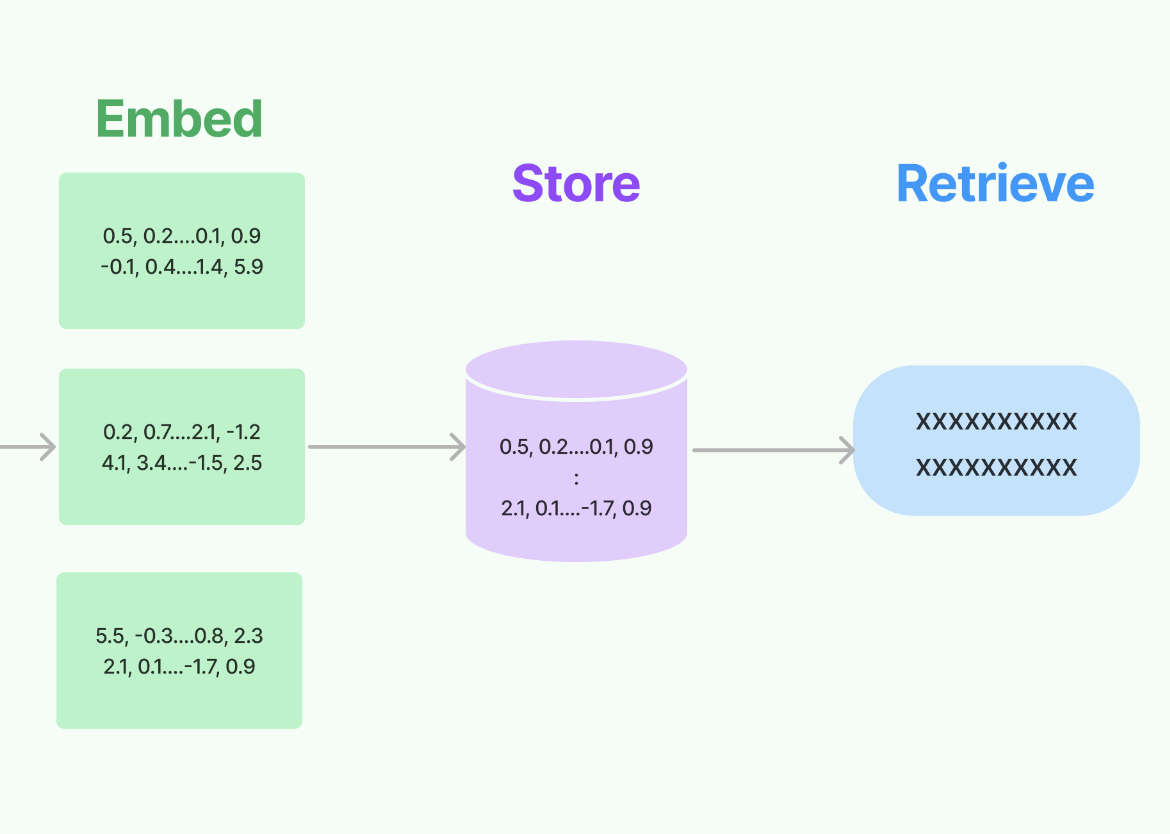
检索增强生成 (RAG) 通过允许模型访问和利用外部知识库,一直在增强对话式 AI 的能力。在这篇文章中,我们将深入探讨如何使用 LangChain 和 Panel 构建 RAG 聊天机器人。您将学习
在本博客结束时,您将能够构建像这样的 RAG 聊天机器人:

您是否有兴趣制作一个聊天机器人,可以在回答问题时利用您自己的数据集合?检索增强生成 (RAG) 是一种 AI 框架,它结合了预训练语言模型和信息检索系统的优势,以在对话式 AI 系统中生成响应,或通过利用外部知识来创建内容。它集成了从知识来源检索相关信息和基于检索到的信息生成响应的功能。
在典型的 RAG 设置中
当预训练语言模型本身可能没有必要的信息来生成准确或足够详细的响应时,RAG 特别有用,因为像 GPT-4 这样的标准语言模型无法直接访问实时或训练后外部信息。
在我们开始构建 RAG 应用程序之前,您需要安装 panel 1.3 和您可能需要的其他软件包,包括 jupyterlab、pypdf、chromadb、tiktoken、langchain 和 openai。
本博客的完整代码可以在 GitHub 中找到。
实际上,在 LangChain 中实现 RAG 有多种方法。请查看我们之前的博客文章《在 LangChain 中进行问答的 4 种方法》,了解详细信息。在本示例中,我们将使用 RetrievalQA chain。此过程包含几个步骤
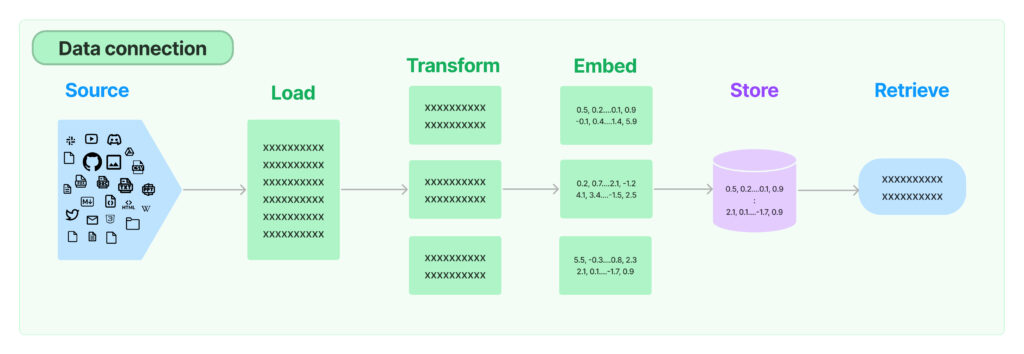
CharacterTextSplitter 根据字符进行拆分,并按字符数衡量块长度。import os
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
os.environ["OPENAI_API_KEY"] = "Type your OpenAI API key here"
# load documents
loader = PyPDFLoader("example.pdf")
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(
search_type="similarity", search_kwargs={"k": 2}
)
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="map_reduce",
retriever=retriever,
return_source_documents=True,
verbose=True,
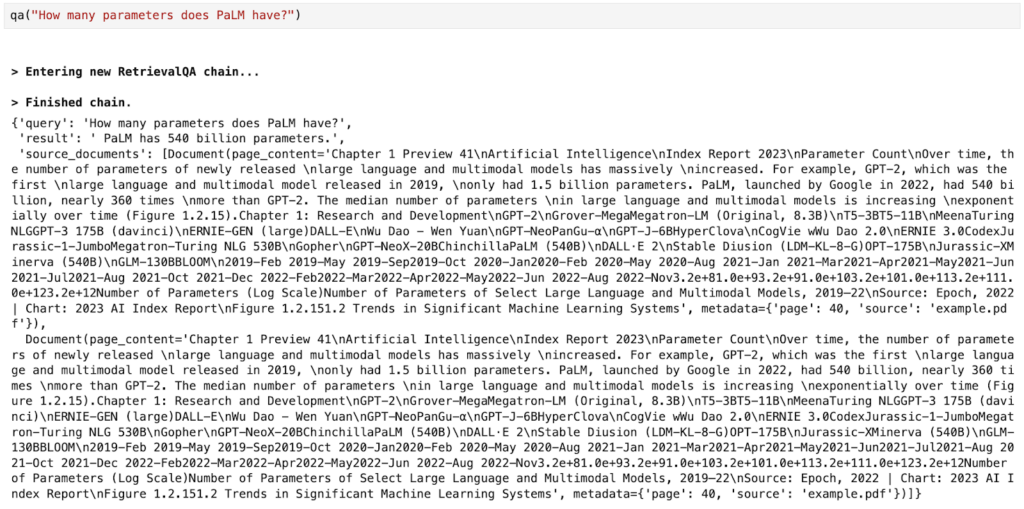
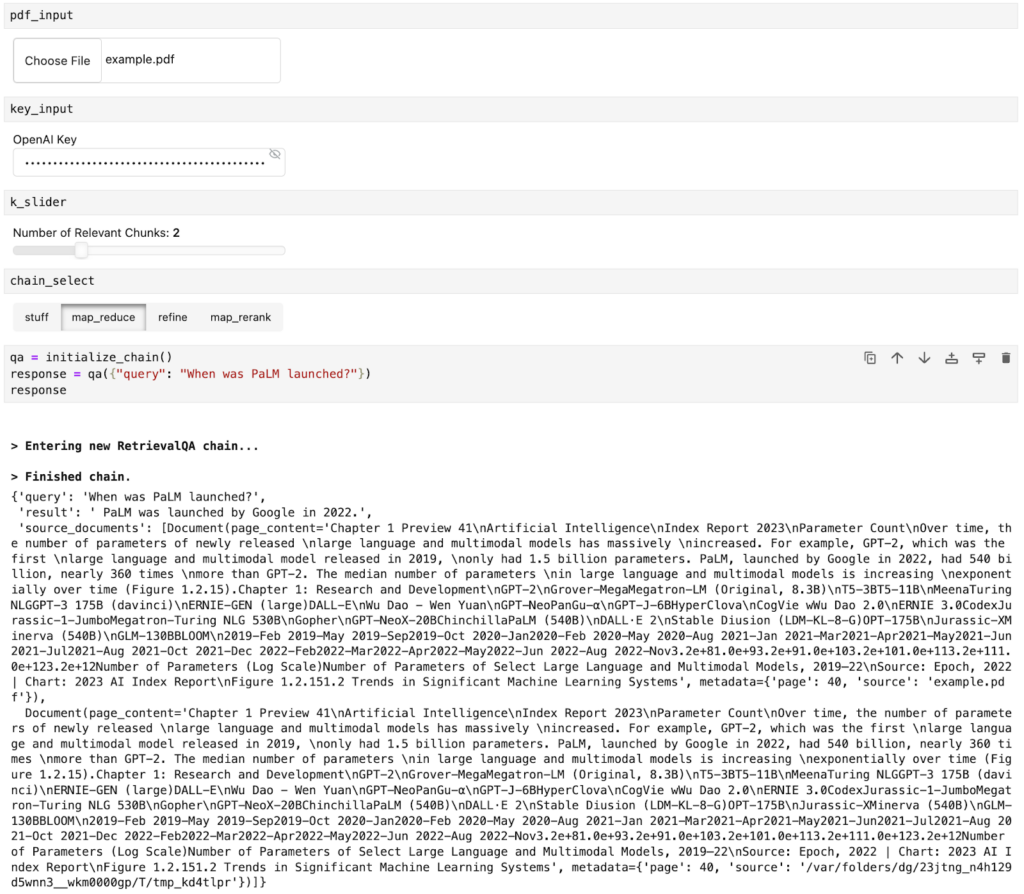
)当我们提出问题时,我们可以查看结果和两个源文档
在我们之前的博客文章中,我们介绍了 Panel 全新的聊天界面以及如何在 Panel 中构建基本 AI 聊天机器人。如果您有兴趣了解有关 Panel 和聊天界面的更多信息,我们建议您查看该博客文章。要为我们的 RAG 应用程序制作 Panel 聊天机器人,以下是四个简单步骤:
Panel 小部件是交互式组件,允许您为应用程序上传文件或选择值。
对于我们的 RAG 应用程序聊天机器人,我们定义了四个 Panel 小部件
import panel as pn
pn.extension()
pdf_input = pn.widgets.FileInput(accept=".pdf", value="", height=50)
key_input = pn.widgets.PasswordInput(
name="OpenAI Key",
placeholder="sk-...",
)
k_slider = pn.widgets.IntSlider(
name="Number of Relevant Chunks", start=1, end=5, step=1, value=2
)
chain_select = pn.widgets.RadioButtonGroup(
name="Chain Type", options=["stuff", "map_reduce", "refine", "map_rerank"]
)
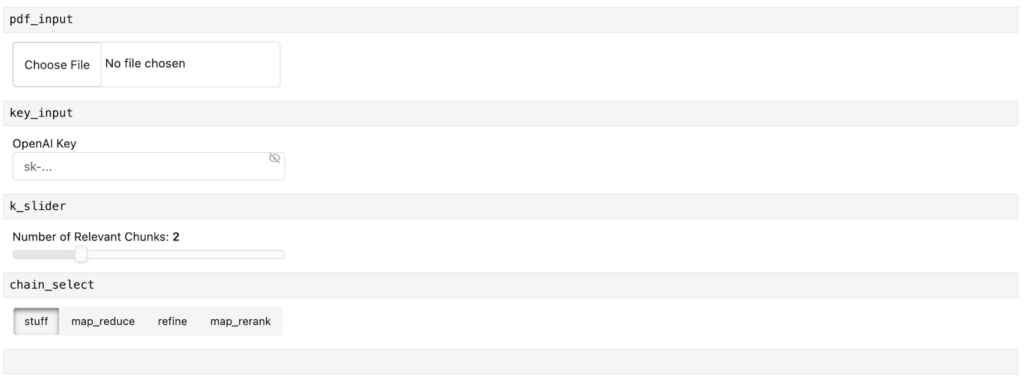
chat_input = pn.widgets.TextInput(placeholder="First, upload a PDF!")以下是小部件在 Jupyter Notebook 中的外观
接下来,让我们将上面的 LangChain 代码包装到一个函数中。这个函数对您来说应该非常熟悉。值得指出的是,我们已将一些值替换为我们刚刚定义的小部件。具体来说
key_input 小部件定义 OpenAI API 密钥search_kwargs={"k": 2} 替换为 search_kwargs={"k": k_slider.value},以便我们可以控制我们想要检索多少个相关文档chain_type="map_reduce" 替换为 chain_type=chain_select.value,以便我们可以选择四种链类型之一。def initialize_chain():
if key_input.value:
os.environ["OPENAI_API_KEY"] = key_input.value
selections = (pdf_input.value, k_slider.value, chain_select.value)
if selections in pn.state.cache:
return pn.state.cache[selections]
chat_input.placeholder = "Ask questions here!"
# load document
with tempfile.NamedTemporaryFile("wb", delete=False) as f:
f.write(pdf_input.value)
file_name = f.name
loader = PyPDFLoader(file_name)
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(
search_type="similarity", search_kwargs={"k": k_slider.value}
)
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type=chain_select.value,
retriever=retriever,
return_source_documents=True,
verbose=True,
)
return qa在我们在小部件中定义值后,我们可以调用此函数并提出有关我们在 pdf_input 小部件中上传的文档的问题
我们如何在聊天界面中与我们的文档交互并提出问题?这就是 Panel 的 ChatInterface 小部件的用武之地!
我们必须创建一个函数 respond 来定义聊天机器人如何响应。此函数接收来自步骤 2 的响应,并将其格式化为 Panel 对象 answers。我们还在此 Panel 对象中附加相关的源文档。然后我们只需在 pn.chat.ChatInterface callback 中调用该函数。
async def respond(contents, user, chat_interface):
if not pdf_input.value:
chat_interface.send(
{"user": "System", "value": "Please first upload a PDF!"}, respond=False
)
return
elif chat_interface.active == 0:
chat_interface.active = 1
chat_interface.active_widget.placeholder = "Ask questions here!"
yield {"user": "OpenAI", "value": "Let's chat about the PDF!"}
return
qa = initialize_chain()
response = qa({"query": contents})
answers = pn.Column(response["result"])
answers.append(pn.layout.Divider())
for doc in response["source_documents"][::-1]:
answers.append(f"**Page {doc.metadata['page']}**:")
answers.append(f"```\n{doc.page_content}\n```")
yield {"user": "OpenAI", "value": answers}
chat_interface = pn.chat.ChatInterface(
callback=respond, sizing_mode="stretch_width", widgets=[pdf_input, chat_input]
)
chat_interface.send(
{"user": "System", "value": "Please first upload a PDF and click send!"},
respond=False,
)最后一步是将小部件和聊天界面组合在一个应用程序中。Panel 带有多个模板,使我们能够快速轻松地创建具有更好美观性的 Web 应用程序。在这里,我们使用 BootstrapTemplate 在侧边栏中组织小部件,并在应用程序中心显示聊天界面。
template = pn.template.BootstrapTemplate(
sidebar=[key_input, k_slider, chain_select], main=[chat_interface]
)
template.servable()要服务应用程序,请运行 panel serve app.py 或 panel serve app.ipynb. 您将获得本博客文章开头显示的应用程序:

检索增强生成 (RAG) 是 AI 领域中信息检索和生成技术的迷人结合。在本博客中,我们分解了其要点,逐步介绍了如何使用 LangChain 创建 RAG 应用程序,最后集成了 Panel 用户友好的聊天界面。这为任何希望在其项目中理解或实施 RAG 的人提供了实用指南。当我们继续驾驭不断发展的科技世界时,利用像 RAG 这样的工具可能是有益的一步。我们希望您在本介绍和指南中找到了价值。祝您编程愉快!
注意:
与我们的专家之一交流,为您的 AI 之旅找到解决方案。