在不断发展的 AI 世界中,本地模型已成为焦点,尤其是在隐私和安全方面的优势。使用本地模型部署和开发聊天机器人的能力对于数据安全、隐私和成本管理尤其有价值。Mistral 和 Llama2 已成为两个性能最佳的开源本地大型语言模型 (LLM)。
Meta 今年 7 月推出的 Llama2 是最先进的 LLM 集合。它提供 70 亿、130 亿和 700 亿参数模型,所有这些模型均可免费用于研究和商业用途。Mistral AI 于 9 月发布的 Mistral 7B 被公认为同等规模下最强大的 LLM。它在所有基准测试中均优于 Llama2 13B,尽管其参数较少,因此速度更快且更易于使用。
利用这两个基础模型,以及开源项目 Panel 的聊天界面,我们将向您展示使用本地模型制作 AI 聊天机器人是多么容易。
在这篇文章中,您将学习如何:
- 使用 Mistral 7B 模型
- 添加流式补全
- 使用 Panel 聊天界面构建基于 Mistral 7B 的 AI 聊天机器人
- 构建基于 Mistral 7B 和 Llama2 的 AI 聊天机器人
- 使用 LangChain 构建基于 Mistral 7B 和 Llama2 的 AI 聊天机器人
在我们开始之前,您需要安装 panel==1.3、ctransformers 和 langchain。请注意,如果您使用的是 Nvidia GPU,请安装 ctransformers[cuda]。
现在您已准备就绪!
Mistral 入门
让我们从 Mistral 7B Instruct 的 GGUF 量化版本开始,并使用 AutoClasses `AutoModelForCausalLM` 之一来加载模型。AutoClasses 可以帮助我们根据模型路径自动检索模型。AudoModelForCausalLM 是因果语言建模的模型类之一,这正是我们的 Mistral 7B Instruct 模型所需要的。
# Source: https://hugging-face.cn/TheBloke/Mistral-7B-Instruct-v0.1-GGUF
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
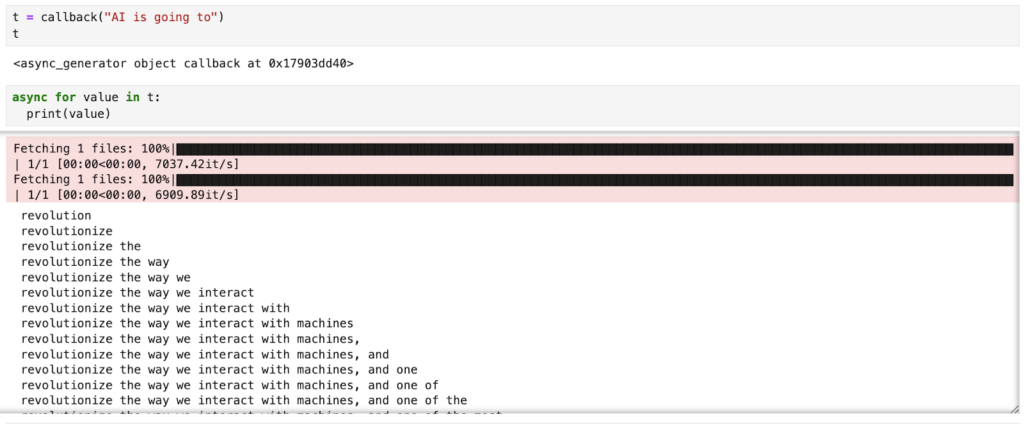
print(llm("AI is going to"))
添加流式补全
在上面的示例中,当我们运行模型推理时,它会在生成整个答案后返回单个响应。当我们需要生成长响应时,这可能会很慢。而且,当我们在聊天界面中时,看到模型一次“键入”一个单词可能更自然。这就是为什么我们有时可能希望在生成响应时“流式传输”响应。为此,我们只需在调用模型时添加 `stream=True`。
为了加快模型响应速度,我们使用 `async` 来允许 IO 任务在后台发生,以便计算机可以在等待模型响应时执行其他任务。
from ctransformers import AutoModelForCausalLM
async def callback(contents: str):
llms = {}
if "mistral" not in llms:
llms["mistral"] = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
gpu_layers=1,
)
llm = llms["mistral"]
response = llm(contents, stream=True, max_new_tokens=1000)
message = ""
for token in response:
message += token
yield message`callback` 函数的结果是一个异步生成器,它允许我们迭代异步传入的数据。如果我们打印出这些值,我们可以看到响应令牌是如何一次生成一个的。
使用 Mistral 7B 构建我们的第一个聊天机器人
我们如何将此模型包装到聊天界面中?Panel 使构建聊天机器人变得非常容易,只需五行代码!
- 我们首先定义一个 ChatInterface 小部件:chat_interface = pn.chat.ChatInterface(callback=callback, callback_user=”Mistral”)。此小部件处理我们聊天机器人的所有 UI 和逻辑。请注意,我们需要定义系统如何在 `callback` 函数中响应,这正是我们上面定义的。
- 让我们使用系统消息“发送消息以从 Mistral 获取回复!”启动聊天机器人,以便用户清楚地了解该怎么做。
- 最后,chat_interface.servable() 确保我们可以在本地或云端提供应用程序服务。要提供应用程序服务,只需将以下代码另存为独立的 Python 文件 app.py 或 Jupyter Notebook 文件 app.ipynb,然后运行 `panel serve app.py` 或 `panel serve app.ipynb`。
注意:异步回调不是必需的,但它确实可以改善用户体验。
如果您有兴趣了解如何使用 OpenAI API 和 LangChain 构建 AI 聊天机器人,请查看我们之前的博客文章。
"""
Demonstrates how to use the ChatInterface widget to create a chatbot using
Mistral thru CTransformers.
"""
import panel as pn
from ctransformers import AutoModelForCausalLM
pn.extension()
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
if "mistral" not in llms:
instance.placeholder_text = "Downloading model; please wait..."
llms["mistral"] = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
gpu_layers=1,
)
llm = llms["mistral"]
response = llm(contents, stream=True, max_new_tokens=1000)
message = ""
for token in response:
message += token
yield message
llms = {}
chat_interface = pn.chat.ChatInterface(callback=callback, callback_user="Mistral")
chat_interface.send(
"Send a message to get a reply from Mistral!", user="System", respond=False
)
chat_interface.servable()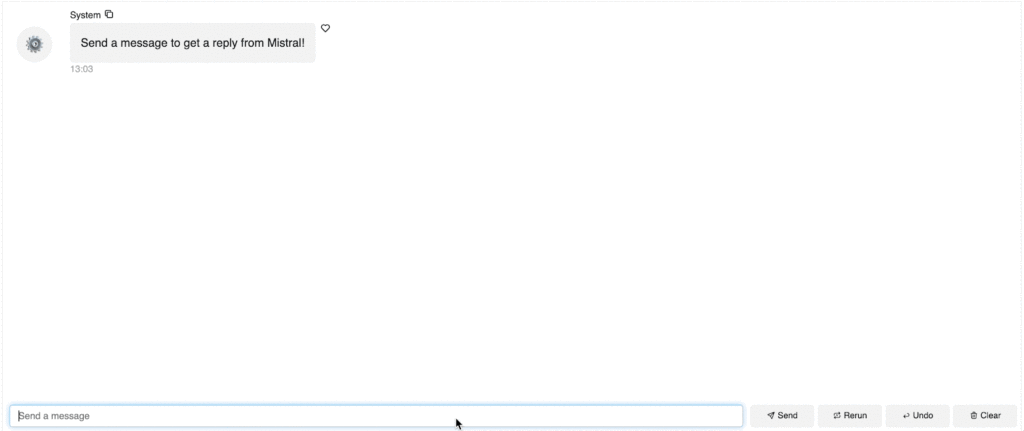
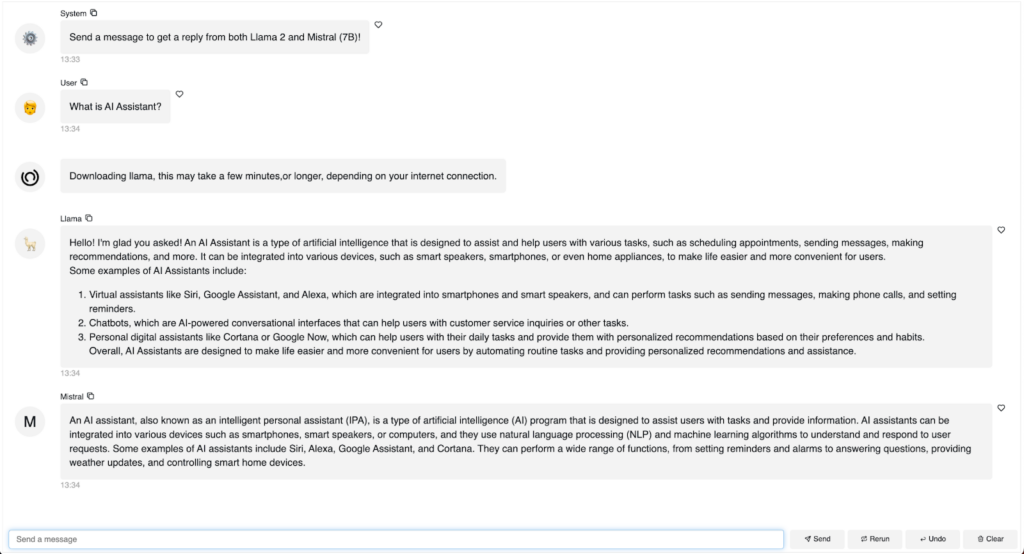
使用 Mistral 7B 和 Llama2 7B 构建我们的第二个聊天机器人
我们可以添加来自另一个模型的响应吗?我们可以比较来自不同模型的响应吗?是的,我们绝对可以!这是一个示例
- 我们在字典 MODEL_ARGUMENTS 中定义模型信息,包括模型名称、模型路径和模型文件
- 然后在 for 循环中,我们分别传入每个模型,并将每个模型的响应发送到聊天界面。
"""
Demonstrates how to use the ChatInterface widget to create a chatbot using
Llama2 and Mistral.
"""
import panel as pn
from ctransformers import AutoModelForCausalLM
pn.extension()
MODEL_ARGUMENTS = {
"llama": {
"args": ["TheBloke/Llama-2-7b-Chat-GGUF"],
"kwargs": {"model_file": "llama-2-7b-chat.Q5_K_M.gguf"},
},
"mistral": {
"args": ["TheBloke/Mistral-7B-Instruct-v0.1-GGUF"],
"kwargs": {"model_file": "mistral-7b-instruct-v0.1.Q4_K_M.gguf"},
},
}
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
for model in MODEL_ARGUMENTS:
if model not in pn.state.cache:
pn.state.cache[model] = AutoModelForCausalLM.from_pretrained(
*MODEL_ARGUMENTS[model]["args"],
**MODEL_ARGUMENTS[model]["kwargs"],
gpu_layers=1,
)
llm = pn.state.cache[model]
response = llm(contents, max_new_tokens=512, stream=True)
message = None
for chunk in response:
message = instance.stream(chunk, user=model.title(), message=message)
chat_interface = pn.chat.ChatInterface(callback=callback)
chat_interface.send(
"Send a message to get a reply from both Llama 2 and Mistral (7B)!",
user="System",
respond=False,
)
chat_interface.servable()运行 `panel serve app.py` 或 `panel serve app.ipynb` 后,您可以与 Llama2 和 Mistral 聊天,并直接比较他们的响应。
使用 LangChain 构建我们的第三个基于 Mistral 7B 和 Llama2 7B 的聊天机器人
我们可以使用 LangChain 构建相同的聊天机器人吗?是的!LangChain 是一个用于开发 LLM 应用程序的框架,许多人发现它很有用。
- LangChain 提供了一个 CTrasnformers 包装器,我们可以通过 `from langchain.llms import CTransformers` 访问它。然后我们可以使用 CTransformers 统一接口来加载我们的两个模型。
- PromptTemplate 帮助我们定义可重用的模板,用于生成发送到语言模型的提示。我们在 prompt 变量中定义我们的提示。
- 我们使用 LLMChain 将提示与语言模型链接起来。具体来说,它使用提供的输入值格式化提示模板,将格式化的提示传递给语言模型,并返回输出。
"""
Demonstrates how to use the ChatInterface widget to create a chatbot using
Llama2 and Mistral.
"""
import panel as pn
from langchain.chains import LLMChain
from langchain.llms import CTransformers
from langchain.prompts import PromptTemplate
pn.extension()
MODEL_KWARGS = {
"llama": {
"model": "TheBloke/Llama-2-7b-Chat-GGUF",
"model_file": "llama-2-7b-chat.Q5_K_M.gguf",
},
"mistral": {
"model": "TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
"model_file": "mistral-7b-instruct-v0.1.Q4_K_M.gguf",
},
}
llm_chains = {}
TEMPLATE = """<s>[INST] You are a friendly chat bot who's willing to help answer the user:
{user_input} [/INST] </s>
"""
async def callback(contents: str, user: str, instance: pn.chat.ChatInterface):
config = {"max_new_tokens": 256, "temperature": 0.5}
for model in MODEL_KWARGS:
if model not in llm_chains:
instance.placeholder_text = (
f"Downloading {model}, this may take a few minutes,"
f"or longer, depending on your internet connection."
)
llm = CTransformers(**MODEL_KWARGS[model], config=config)
prompt = PromptTemplate(template=TEMPLATE, input_variables=["user_input"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
llm_chains[model] = llm_chain
instance.send(
await llm_chains[model].apredict(user_input=contents),
user=model.title(),
respond=False,
)
chat_interface = pn.chat.ChatInterface(callback=callback, placeholder_threshold=0.1)
chat_interface.send(
"Send a message to get a reply from both Llama 2 and Mistral (7B)!",
user="System",
respond=False,
)
chat_interface.servable()运行 `panel serve app.py` 或 `panel serve app.ipynb`,我们将获得一个使用 LangChain 与 Llama2 和 Mistral 交互的聊天机器人!
结论
在这篇博客中,我们演示了如何运行 Mistral 7B instruct 模型、如何通过流式补全和异步生成器来提高性能、如何使用 Panel 的聊天界面小部件构建聊天机器人、如何构建基于 Mistral 7B 和 Llama2 7B 的聊天机器人,以及最后如何使用 LangChain 构建此聊天机器人。我们希望您在这篇博客中找到价值。祝您编码愉快!
注意:
所有这些工具都是开源的,并且每个人都可以免费使用,但是如果您想获得 Anaconda 的 AI 和 Python 应用程序专家的入门帮助,请联系 [email protected]!