Anaconda 观点
Jan 26, 2021

客座博客由杰出工程师 Thomas Schaeck 撰写 | IBM 数据与 AI
是否可以在使用最佳开源技术的同时确保安全?
在这篇博文中,我们将简要概述 IBM Cloud Pak for Data,并解释它如何与带有 IBM 的 Anaconda 仓库集成,以满足企业对于数据科学家可控、可靠且高性能地使用最佳数据科学和机器学习软件包的要求。
从数据到预测再到使用 IBM Cloud Pak for Data 实现最佳行动
Cloud Pak for Data 涵盖数据和 AI 生命周期,提供集成功能以
上述功能通过数据虚拟化 (DV)、Watson Knowledge Catalog (WKC)、Watson Studio (WS)、Watson Machine Learning (WML) 和 Watson Open Scale (WOS) 组件提供,这些组件包含在 Cloud Pak for Data 中,涵盖了如下图所示的数据和 AI 生命周期。

可以添加决策优化来根据预测确定最佳行动,并且可以监控预测的性能和潜在的公平性问题,以便为纠正措施提供信息。
有关 Cloud Pak for Data 的更多信息,请参阅我们最近的博客文章。
使用 Cloud Pak for Data 在安全、可扩展的云原生环境中协作
为了使数据工程师、数据科学家、主题专家和其他用户能够协作,Cloud Pak for Data 提供了项目。在项目中,用户可以添加成员进行协作,使用一系列工具,例如 Auto AI、分析流、数据流,以及非常重要的 Notebooks 和 Scripts 来运行他们自己的 Python 或 R 代码。
Notebooks 和 Scripts 由 Runtime Environments 提供支持,其中 JupyterLab 允许创建和运行 Jupyter Notebooks 和 Scripts。Runtime environment 定义允许指定虚拟内核的数量、内存的千兆字节数,以及可选的运行 Notebooks 和 Scripts 环境所需的 GPU 数量。用户还可以指定软件配置,其中包含在环境启动时要加载的软件包,以及为 runtime environments 预加载的软件包。
但是,如何在企业中保护和控制所有开发者和数据科学家的环境?
通常,企业需要确保其开发者和数据科学家仅使用已批准在企业项目中使用的软件包。此外,企业可能拥有自己的专有软件包,也需要提供给数据科学家。为了确保 runtime environments 的快速启动时间以及从 Notebooks 或 Scripts 中快速可靠地加载软件包,企业通常需要缓存解决方案来加速软件包加载,使其比从互联网上的远程来源加载软件包更快。
IBM 和 Anaconda 最近宣布建立合作伙伴关系 以帮助企业实现这一目标
与 IBM Cloud Pak for Data 集成的带有 IBM 的 Anaconda 仓库解决了这些需求。如下图所示,可以定义自定义 runtime environments 以从带有 IBM 的 Anaconda 仓库提供的 conda 频道加载软件包,从而使用这些软件包运行 Notebooks 和 Scripts。或者,Notebooks 或 Scripts 中的代码可以通过 Conda 加载软件包。
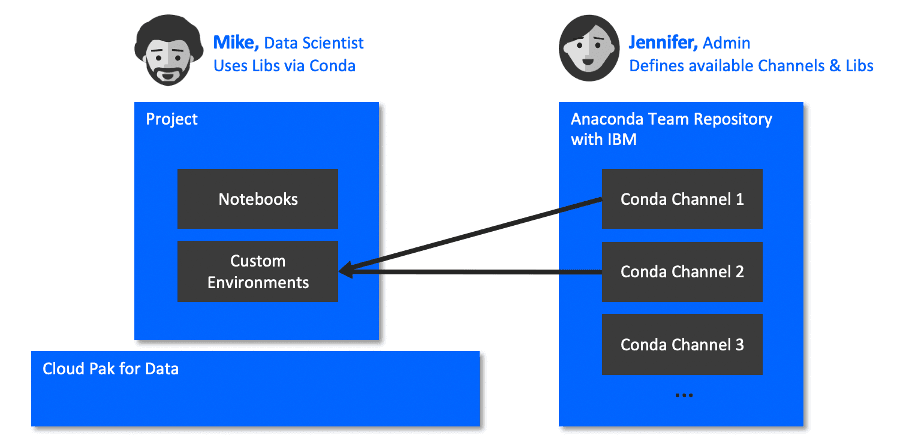
为了确保开发者和数据科学家仅使用批准的软件包,客户可以阻止从 Cloud Pak for Data 环境访问互联网上的软件包,强制所有软件包加载都通过带有 IBM 的 Anaconda 仓库进行。带有 IBM 的 Anaconda 仓库缓存来自互联网的软件包,并允许管理员上传客户自己的专有软件包,以便安全且性能一致地提供服务,此外还提供缓存的开源软件包。
配置 Cloud Pak for Data 以使用带有 IBM 的 Anaconda 仓库非常容易
首先,系统的管理员需要在 Cloud Pak for Data 系统上编辑 RC 文件,以将带有 IBM 的 Anaconda 仓库服务添加为 conda 频道的服务器,Cloud Pak for Data 然后将知道从中加载软件包。
然后,在 Cloud Pak for Data 项目中工作的数据科学家和其他用户可以创建 runtime environment 定义,并指定他们希望在 Notebooks 和 Scripts 中使用的频道和软件包,以便他们使用的软件包从带有 IBM 的 Anaconda 仓库提供的 conda 频道加载。
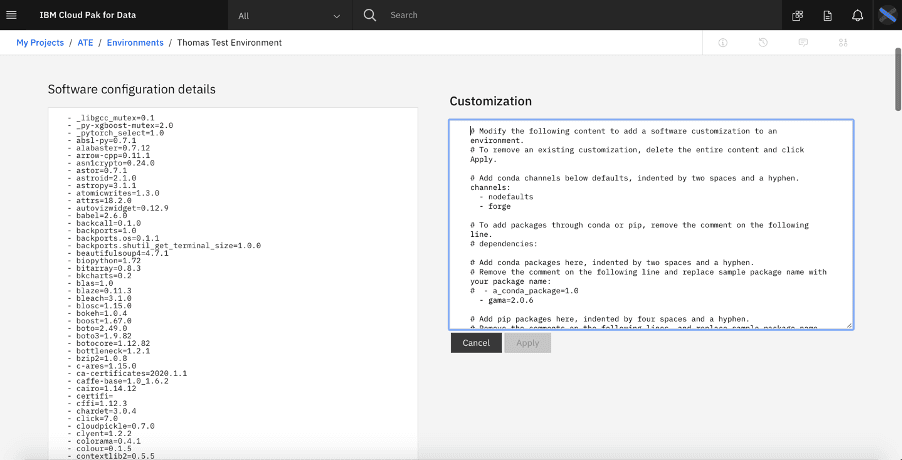
下图显示了 Cloud Pak for Data 项目中 runtime environment 的软件自定义,其中添加了一个频道和一个软件包。
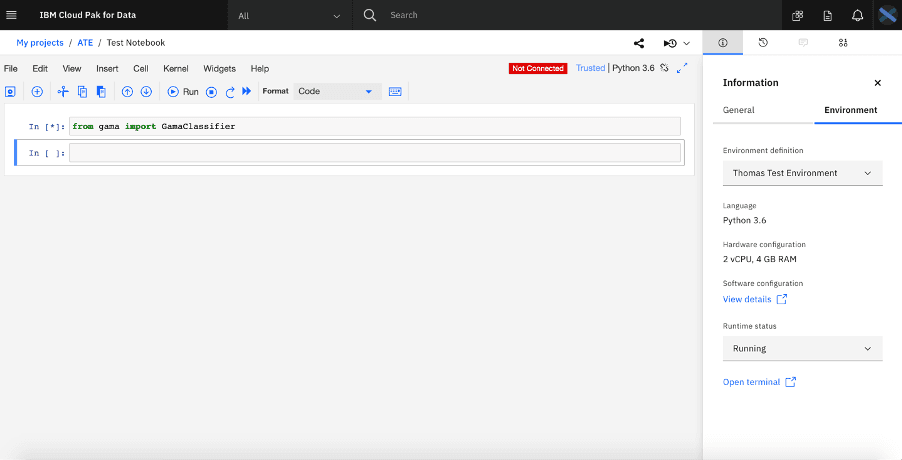
现在,数据科学家只需在他们项目中的 Notebooks 和 Scripts 中导入软件包,这将触发从带有 IBM 的 Anaconda 仓库提供的频道加载软件包。
更多信息
与我们的专家之一交流,为您的 AI 之旅找到解决方案。

