新闻产品更新
2023 年 7 月 12 日
新版本发布:Anaconda Distribution 2023.07、Miniconda 23.5.0 及更多!
 (12)")

在本博客中,我们将逐步介绍如何在基于 AWS-Graviton 的 Amazon EC2 实例(以下简称 AWS Graviton)上为真实世界的欺诈检测数据集用例实施完整的机器学习 (ML) 生命周期。这是一个示例,您可以使用 AWS Graviton 上的 Anaconda Distribution 来处理各种 ML 用例。阅读本博客后的要点如下
AWS Graviton 支持所有主要的机器学习框架,如 PyTorch、TensorFlow、XGBoost、scikit-learn 等,AWS Graviton 通常比同类基于 x86 的实例提供 40% 的性价比和 20% 的性能优势。此外,Graviton 通常比同类基于 x86 的实例节能约 60%,因此具有可持续性优势。
Anaconda Distribution 是 ML 生态系统中的领先平台,也是世界上最受信任的 Python 发行版。从 AI 解决方案到交互式可视化,Anaconda 为各种应用提供支持,是数值和科学计算的首选发行版,为数据科学和机器学习提供对各种必要软件包和框架的访问,包括 NumPy、pandas、scikit-learn、PyTorch 和 TensorFlow。Anaconda Distribution 还与 conda 配对,以提供简化的软件包和环境管理。Conda 环境保证了 Python 生态系统在多个平台和硬件架构之间的完全可重现性。Anaconda Distribution 对 AWS Graviton 的支持始于 2021 年,AWS Graviton 已在 Anaconda 上实现了对软件包的完全支持。
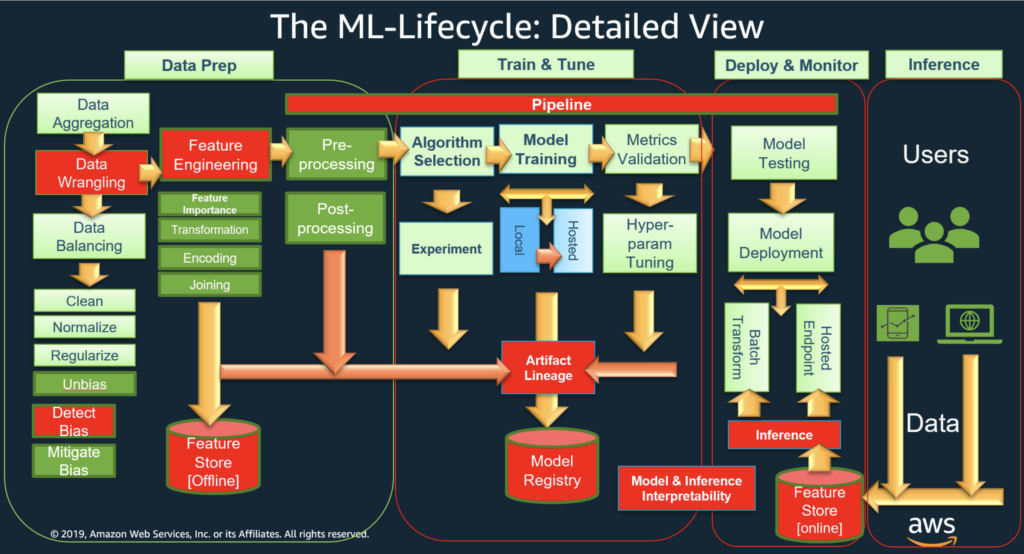
我们将展示如何在 AWS Graviton 上为信用卡欺诈检测的 ML 业务用例执行完整的 ML 生命周期。我们将演示对软件包的支持以及在 AWS Graviton 上的易用性,类似于基于 x86 的实例用于 ML 工作负载。下图 2 显示了 ML 生命周期管道的各个阶段。我们将重点关注 ML 生命周期的“数据准备”、“训练和调优”以及观察模型性能部分。AWS 完成了为基于 arm64 的 AWS Graviton 性能调优底层 ML 框架的繁重工作(例如:PyTorch 2.0 的一些优化,如“优化细节”下列出的),并从您的代码中抽象出来。正如您所看到的,ML 生命周期有很多阶段,是一种创建和部署 ML 模型的端到端方式。可以使用常用的 ML 框架和 Anaconda Distribution 在 AWS Graviton 上实施完整的 ML 软件堆栈。
我们将使用来自 Kaggle 的信用卡欺诈检测数据集来研究真实世界的场景。我们将训练一个模型,使用 scikit-learn 中的决策树软件包来检测欺诈行为。虽然数据集是欺诈检测数据集,但讨论的大多数技术都具有广泛的适用性。
选择此数据集是因为它代表了真实世界数据挑战的良好候选者,能够实施完整而广泛的数据科学和机器学习管道。
与通常的欺诈检测情况一样,手头的问题可以被认为是“异常检测”问题。换句话说,我们应该期望处理一个高度偏向于非欺诈用例的数据集。事实上,我们的数据集就是这种情况,其中 99.8% 的交易是非欺诈性的,只有 0.17% 的交易反映了欺诈行为。
我们将使用 AWS Graviton 的Anaconda Distribution,并按照官方文档中提供的说明进行操作。Anaconda Distribution 自动保证了跨多个架构的完全可重现性(在软件包和版本方面)。这对于本文的最后一节至关重要,在最后一节中,我们将比较基于 AWS-Graviton 的实例性能与基于 x86 的实例性能。根据 ML 模型部署,在 AWS 上,您可以使用 SageMaker 来部署模型,也可以使用自管理 ML。我们将展示 Graviton 上的自管理 ML。另一篇博文讨论了使用 SageMaker for Graviton。
本博客中介绍的所有软件包以及整个实验中使用的软件包都已成为 Anaconda Distribution 的一部分。为了与基于 x86 的实例进行性能比较,我们还将利用通过 Anaconda 创建的 conda 环境。conda 环境提供的关键优势是在所有 AWS 实例中软件包和 Python 解释器的完全可移植性。这使我们能够在三个 Amazon EC2 (c6i.8xlarge) 和基于 AWS-Graviton 的(c7g.8xlarge、c6g.8xlarge)实例上重现我们的环境。我们将使用运行 Amazon Linux 2 (AL2) 的三个 AWS EC2 实例进行比较。这非常适合性能比较,以确保 ML 软件堆栈在多个 AWS EC2 实例上的多个基准测试运行中保持不变。
AWS Graviton 通过 Anaconda Distribution 支持常用的数据准备技术和库,如 NumPy、pandas 和 scikit-learn。您无需学习任何用于 arm64 的新库或技术。让我们首先可视化数据集以了解数据的性质。
信用卡欺诈数据集包含 30 个特征。除了“Time”和“Amount”特征外,所有其他特征名称均已匿名化以保护隐私。数据集中共有 284, 817 个交易(行)。数据集非常干净,没有“Null”值等,并且数据描述表明,所有匿名的“Vx”特征都是主成分分析 (PCA) 转换的数值结果。根据数据集的描述,“Time”和“Amount”特征未进行转换。特征“Class”是响应变量,欺诈时取值 1,否则取值 0。根据数据集描述,某些特征(如“Time”和“Amount”)未进行缩放,因此我们使用 RobustScaler 技术对它们进行了缩放,该技术最大限度地减少了异常值。
我们将使用常见的 lPython 软件包(如 Matplotlib 和 Seaborn)(它们对于数据探索特别有用)来可视化数据。
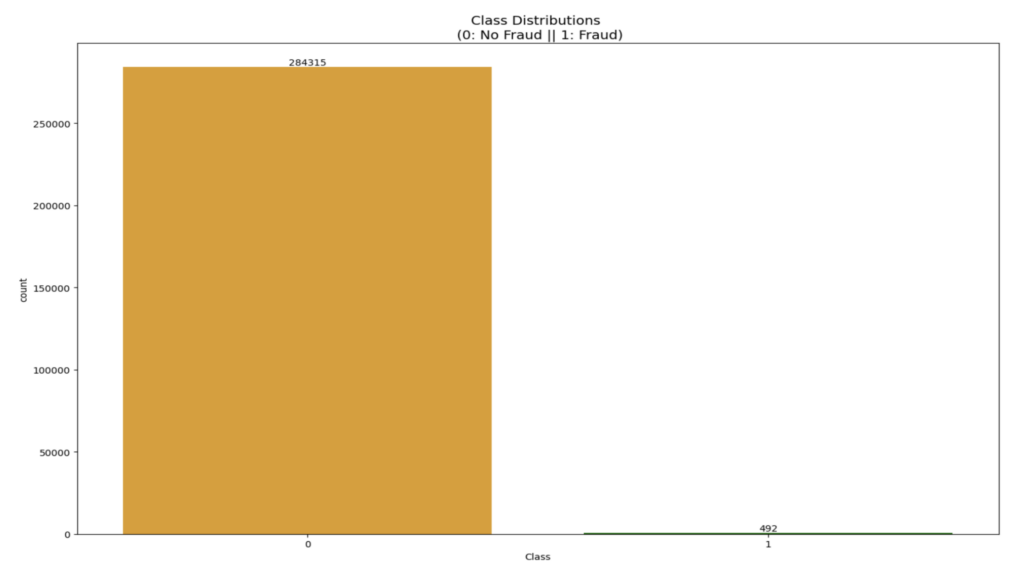
我们可以在数据集中看到,“无欺诈”类别(284,315 笔交易)占主导地位,并且数据高度倾斜,只有 0.17%(492 笔交易)是“欺诈”。重要的是减少这种倾斜,以便不会发生过度拟合,并观察类别与特征之间的真实相关性。
不平衡数据集:不平衡分类涉及在具有严重类别不平衡的分类数据集上开发预测模型。使用不平衡数据集的挑战在于,大多数机器学习技术会忽略少数类,并因此在少数类上表现不佳,尽管通常少数类上的表现最为重要。不平衡数据集的示例有很多,例如设备故障率、成功公司的客户流失率、癌症预测等。
让我们可视化数据和各种特征的分布。我们将使用 SelectKBestScores 对特征进行评级,帮助我们了解哪些特征对哪些交易是欺诈交易具有重大影响,并帮助我们了解各种参数与“欺诈”或“非欺诈”的相关性。
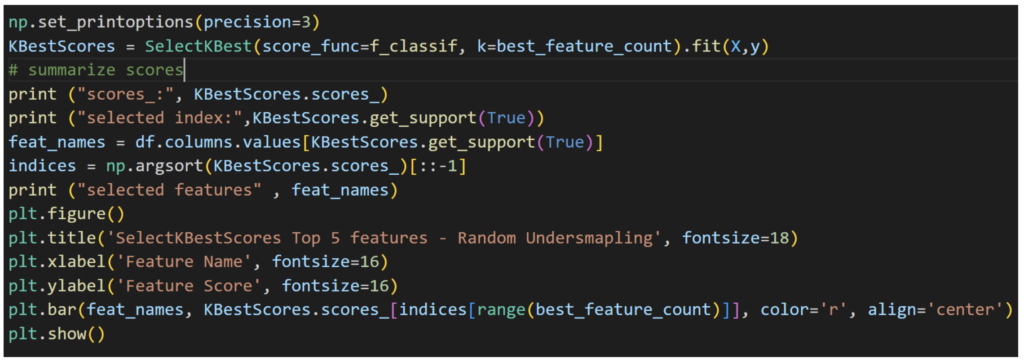
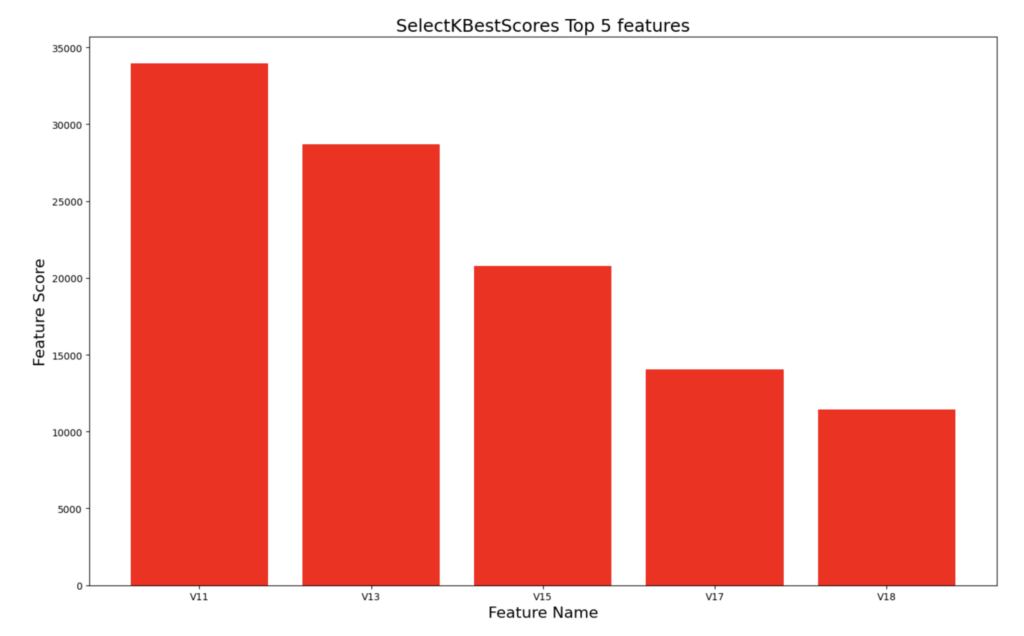
我们可以看到,特征 v11、v13、v15、v17 和 v18 是导致“欺诈”交易的前五个特征。其他技术(如相关矩阵)将产生类似的结果。
一旦我们确定了最重要的特征,我们就可以深入研究每个特征并识别极端异常值。我们使用一种称为四分位距的技术来识别落在四分位距设定的范围之外的极端异常值。
随机欠采样可用于通过选择所有“非欺诈”案例(492 笔交易)并与相等数量(492)的随机选择的“欺诈”案例连接来创建新的子样本,从而使数据更加平衡。现在,这两个类别具有相同的分布。这项技术的缺点是,由于仅从 284,315 笔“非欺诈”交易中挑选了 492 笔,因此存在信息丢失的问题,这在准确性方面并不理想。
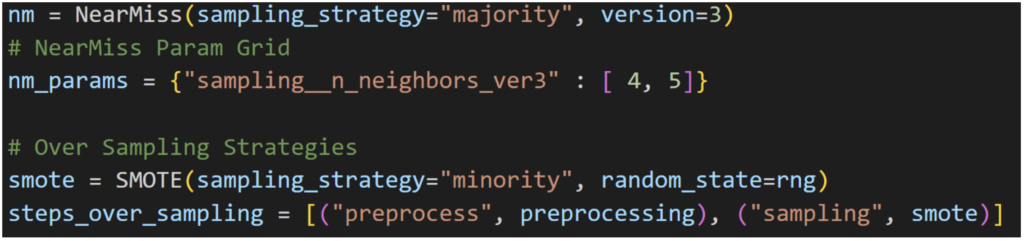
请注意,还有另一种称为 NearMiss 的欠采样技术,它有几种变体。NearMiss-3 涉及为每个最接近的少数类示例选择给定数量的多数类示例。
解决不平衡数据集的另一种方法是对少数类进行过采样。最简单的方法是复制少数类中的示例,尽管这些示例不会向模型添加任何新信息。相反,可以从现有示例中合成新示例。这是一种用于少数类的 数据增强 类型,被称为 合成少数类过采样技术,或简称 SMOTE。Imbalanced-learn (imblearn) 已经是 Anaconda Distribution 的一部分,专门用于处理不平衡数据集。特别是,imbalanced-learn 提供了测试数据集的数据增强方法。对于不平衡数据集,准确率并不那么重要,因为大部分数据都属于一个类别。重要的是 F1 分数,因为它同时考虑了精确率和召回率。
SMOTE 技术有一些缺点,尤其是在高维数据方面。当维度很高时,它会增加噪声、影响方差并增加相关性。但在我们的例子中,由于数据集中的特征数量很少(大约 30 个),因此效果很好。
根据数据集,您可以应用更多的数据准备技术,例如 降维等;我们仅关注了一些常用的技术,但您应该能够在基于 AWS-Graviton 的实例上使用 Anaconda Distribution 应用其他技术,而不会出现任何问题。
可以在此处找到用于本博客的完整代码。
数据准备完成后,数据就可以用于训练和调优了。
对于上述数据集,我们将主要使用 ML scikit-learn 框架,以及决策树和随机森林分类器,原因如下所述。 还有其他分类器,例如 LogisticRegression、KNN 等,您可以尝试,但我们将专注于决策树和随机森林。 尝试不同的分类器以查看哪一个最适合您的数据集是很好的做法。 决策树是一种经典的 ML 算法,在 CPU 上运行良好。
决策树是广泛用于监督式机器学习的算法。 它们因易于解释以及在银行业(欺诈检测、贷款审批等)、医疗保健、电子商务等领域的广泛应用而受欢迎。 它们适用于回归和分类问题。
决策树具有更强的可解释性,当决策过程可能需要向客户解释或出于合规性原因时,这一点非常重要。 CPU 非常适合运行决策树,尤其是在数据集较小时。 鉴于 CPU 本质上更易于使用且通常比 GPU 成本更低,因此 CPU 可用于训练和推理。
我们使用 GridSearchCV 来调整 DecisionTree() 和 RandomForest() 的超参数。
以下代码展示了如何使用 SMOTE 过采样策略来实例化评估管道。 类似地,可以使用 NearMiss 创建管道。
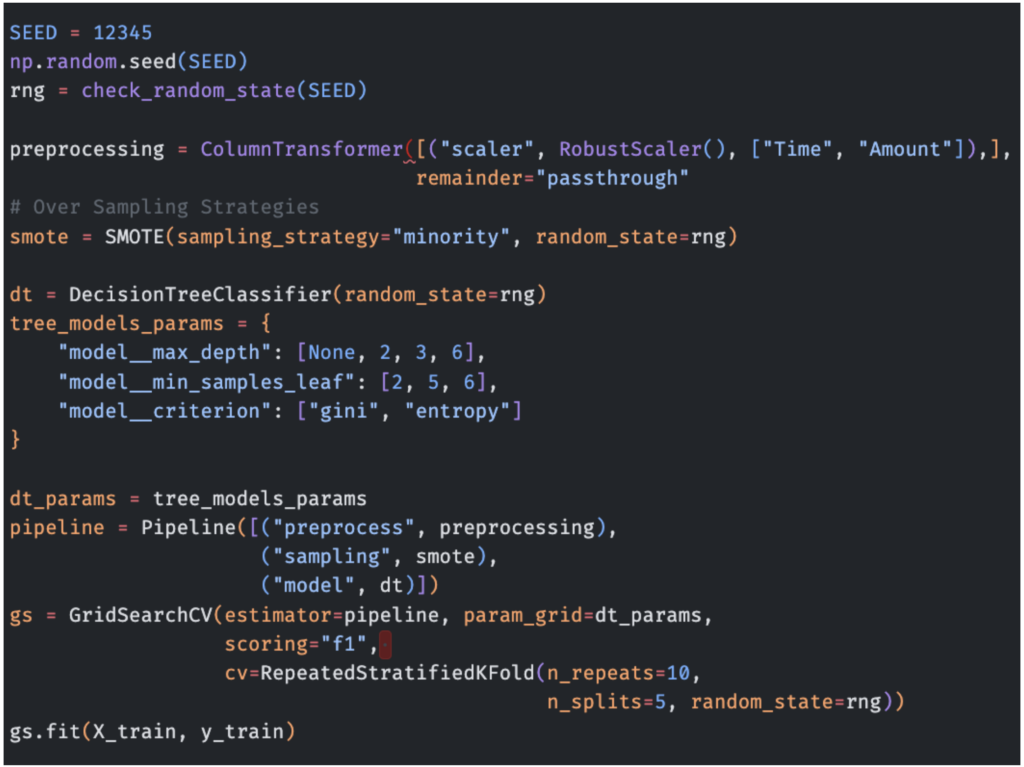
创建上述管道后,我们对其进行训练,并对预留的测试数据进行预测。
正如前面讨论的那样,对于不平衡的数据集,准确率并不重要,因为绝大多数数据都属于一个类别。 重要的是 F1 分数(越高越好),因为它同时考虑了精确率和召回率,以及 ROC 曲线下的面积 (AUC)。 因此,让我们看看这些。 我们可以看到,SMOTE 的 F1 分数往往优于 NearMiss。
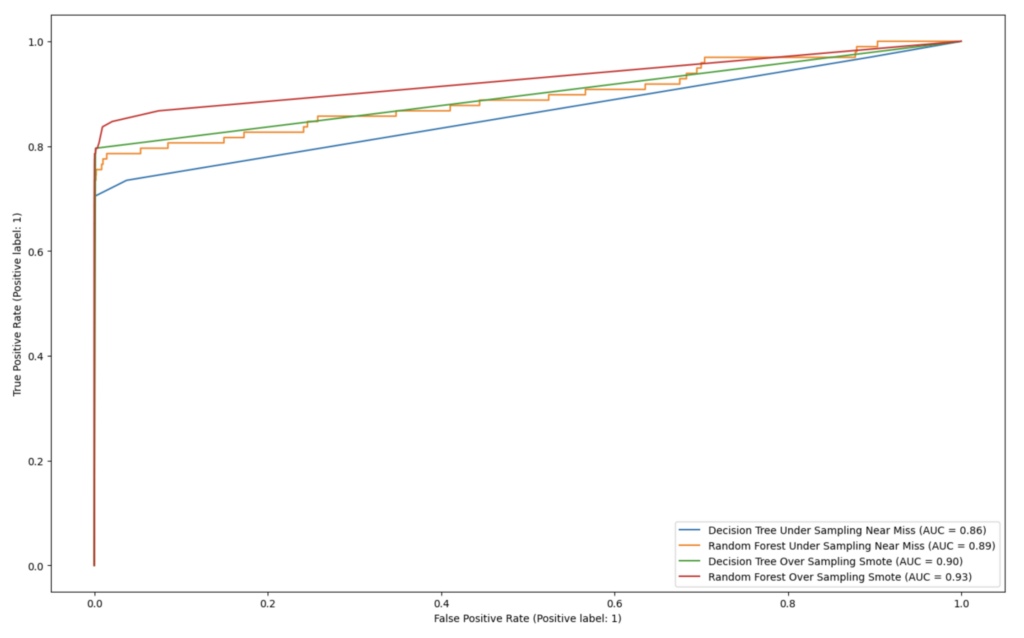
正如我们在上图中看到的,SMOTE 技术确实比 NearMiss 技术做得更好,无论使用决策树还是随机森林作为分类器。 此外,在 AUC 方面,随机森林略优于决策树。
| F1 分数(越高越好) | 决策树 (scikit-learn) 分类器 | 随机森林 (scikit-learn) 分类器 |
| NearMiss 欠采样技术 | 0.75 | 0.77 |
| SMOTE 技术 | 0.61 | 0.82 |
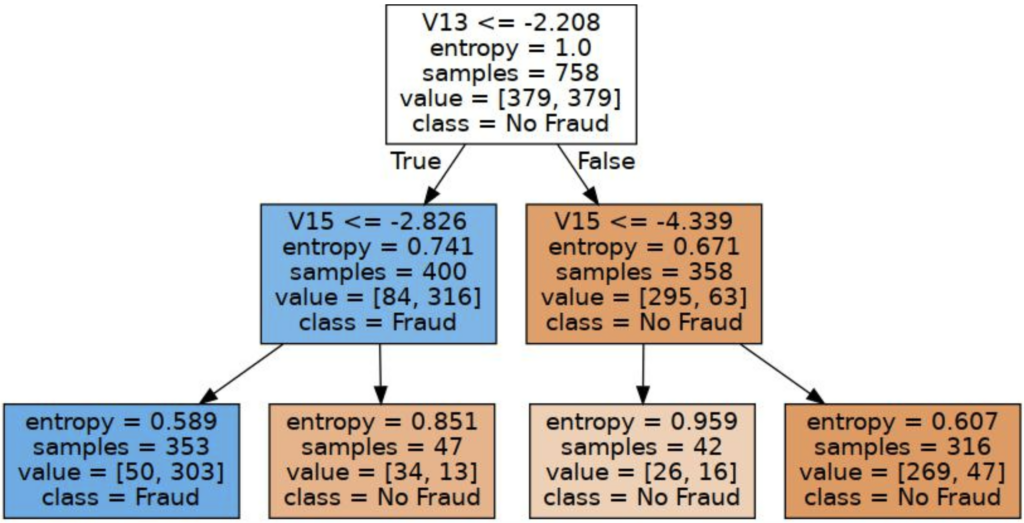
可解释性 – 决策树可视化
下面是由 graphviz 包(通过 Anaconda Distribution 提供)生成的决策树的一个子部分,它展示了决策树如何基于信用卡欺诈数据集的输入做出决策的过程。
在下面的代码中,我们利用 scikit-learn 提供的 export_graphviz 实用程序函数,以 Graphviz Dot 格式绘制树模型。 您需要安装 graphviz 和 python-graphviz 才能运行此代码,两者都可以通过 Anaconda Distribution 中的 conda install 获得。
conda install graphviz python-graphviz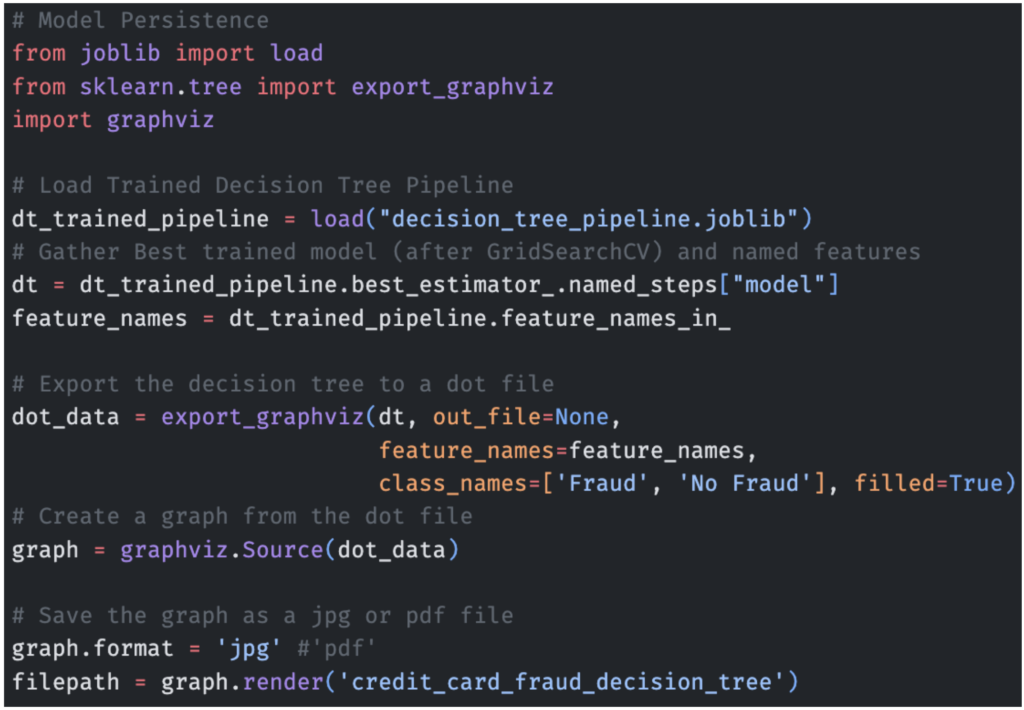
在下面的图中,我们可以看到,如果特征 v13 的值小于或等于 -2.208,则路径转到特征 v15,而特征 v15 又查看阈值 -2.826,依此类推,直到我们到达叶节点。 这就是我们确定性地知道交易如何被分类为“欺诈”或“非欺诈”的方式。
对于部署,Anaconda 提供了几个有用的软件包。 ML 容器经常用于部署 ML 模型。 Anaconda Distribution 支持 Docker、conda-pack、mamba 等。 可以构建多架构 ML 软件包,以部署到基于 x86 和 AWS-Graviton 的实例。 将模型从基于 x86 的实例迁移(或新部署)到 Graviton 实例非常简单,因为 AWS 提供了容器来托管使用 PyTorch、TensorFlow、scikit-learn 和 XGBoost 的模型,并且这些模型与架构无关。 您可以在此处了解有关构建多架构容器的更多信息。
Anaconda 协助监控和维护已部署的 ML 模型。 有一些库可用于监控模型性能、跟踪数据漂移以及在必要时重新训练模型。 此外,Anaconda 提供版本控制集成,并且可以轻松安装 Anaconda 的软件包管理更新和 ML 库的错误修复,以确保模型保持最新。
在 ML 生命周期中,模型训练、测试、部署和推理是持续进行的活动。 持续使用指标监控这些活动是一个好习惯。
模型训练时间指标
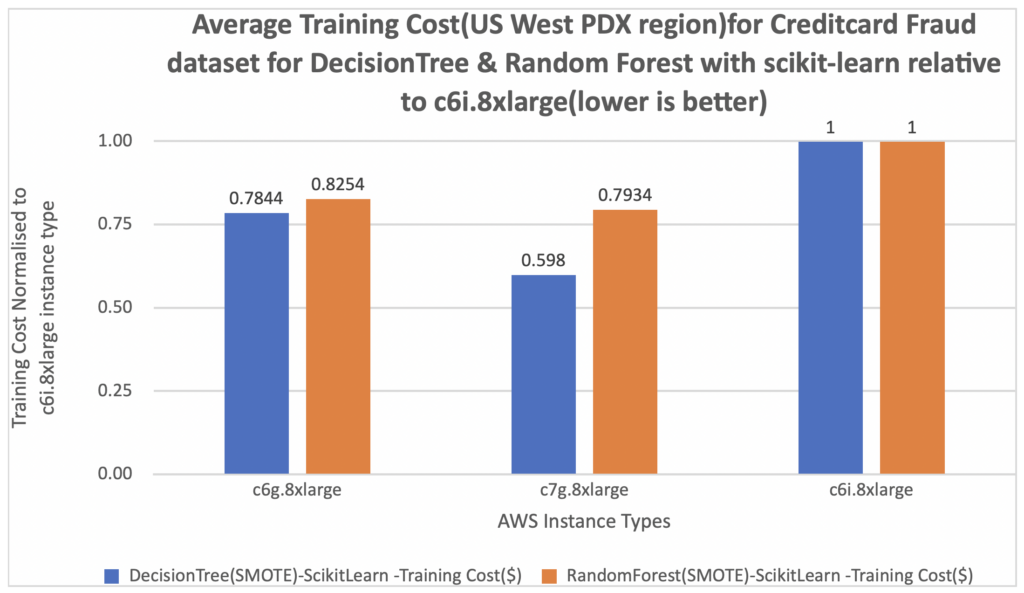
下图显示了我们的模型在基于 Graviton 的实例和基于 x86 的实例上的训练时间比较。 为了进行比较,我们使用了 3 种不同的 AWS 实例类型
在下面的图中,我们测量了训练成本。 我们进一步将每次训练结果的成本标准化为 c6i.8xlarge 实例,在图表的 Y 轴上测量为 1。 您可以看到,对于使用 scikit-learn 框架的决策树和随机森林分类器,c7g.8xlarge (AWS Graviton3) 的每次训练成本约为 c6i.8xlarge 的 20%。
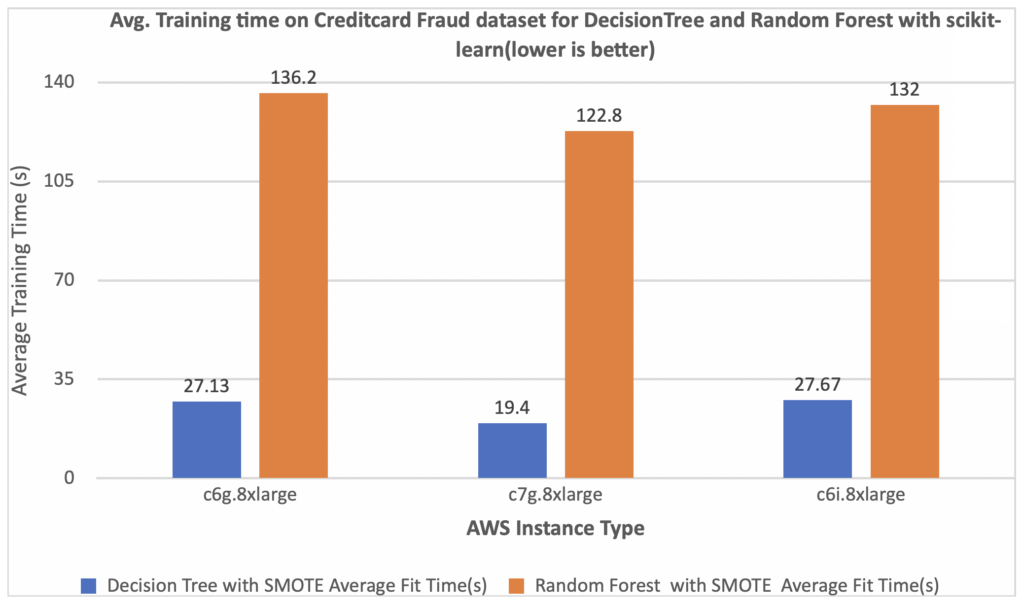
正如您在下图中看到的,基于 AWS-Graviton3 的实例 (c7g.8xlarge) 的性能优于基于 x86 的 Amazon EC2 实例 (c6i.8xlarge)。
有关使用 AWS Graviton 进行各种 ML 框架推理的价格和性能优势(推理延迟)的更多详细信息,请点击此处。
Anaconda Distribution 支持可在 AWS Graviton 上运行的所有主要 arm64 Python 软件包,从而最终在 AWS Graviton 上完成自我管理的 ML 生命周期。 在这篇博文中,我们考虑了信用卡欺诈检测的真实用例,以及如何使用 AWS Graviton 来实现完整的 ML 生命周期。 我们证明了基于 x86 的 AWS EC2 实例上通常可用的功能在 AWS Graviton 上也可用于运行 ML 工作负载。 Anaconda Distribution 实现了此过程,以保证 Python ML 堆栈在不同架构之间的完全可移植性。 在这篇文章中,我们还分析了 AWS Graviton 的性能,它在可调试性和可解释性方面都易于使用,正如我们在决策树中看到的那样,由于合规性和其他要求,这对于某些 ML 工作负载是需要的。 AWS Graviton 可用于执行某些常见经典 ML 工作负载的训练和推理。 AWS Graviton 具有价格和性价比优势,并且大多数 AI/ML 框架都支持它。
与我们的专家之一交流,为您的 AI 之旅找到解决方案。
