Anaconda 视角
2022年8月3日
成为软件工程师没有错误的方式:第二部分


这可能就是你!点击此处提交创客博客系列摘要。
在这个时代,我们使用并接触到大量数据。大多数数据是相互关联的,并具有隐含或显式的关系,在这种情况下,我们可以依靠关系数据库进行组织。但是,可用数据的庞大数量使得生成可操作的见解变得棘手和复杂。通过使用自托管图数据库(如 Neo4j)在自己的数据中心中,或者通过使用 Google Cloud 的 AuraDB 等提供商在云端运行它们,可以在行业规模上更轻松地完成生成所述见解。然而,这导致了一些挑战,包括对计算资源的需求,这往往成为图数据库和图数据科学领域新进入者的障碍。
这篇博文旨在帮助开发人员和数据科学家在其系统本地快速创建图数据库,并与 Neo4j 及其社区提供的示例数据集进行交互。此外,这篇文章还讨论了如何使用各种开源 Python 工具来剖析数据,并应用基本的图数据科学算法进行分析和可视化。我们将逐步介绍包括示例数据集的收集、操作和存储在内的各个步骤。我处理大量关联数据,根据我的经验,图数据库有效地表示了连接,并有助于使用机器学习和数据科学算法来揭示潜在模式。
在使用图数据库和 Anaconda 提供的 数据科学工具 时,最重要的一步是拥有正确的数据。当涉及到大数据科学问题时,根据我的经验,算法的应用只是更大难题中的一小部分;最大的难题是数据增强和数据清洗。
在以下示例中,我们将使用 Neo4j 提供的 示例数据集 中的 “slack” 数据集。我们将使用 Jupyter Notebook 中的 Python API 查询数据库,使用 Cypher 查询仅读取给定数据集中的 Slack 频道和消息。
首先,我们将完成一些小的预处理步骤,以方便实施和学习。这些步骤主要与数据集中的消息有关,因为它们包含大部分文本。关于数据集中的 Slack 频道,我们只寻找与图和相关主题相关的频道。
删除所有子类型为 channel_join、channel_leave 或 channel_archive 的消息,以删除 “用户 X 加入了频道” 等噪音消息。
使用 NLTK Python 库来标记消息文本并删除停用词。NLTK 库提供了各种开源资源,可用于调整模型和处理数据。
现在我们可以使用基于 Slack 频道名称和 Slack 消息文本的节点来创建图。下图允许我们可视化 Neo4j 浏览器中指示的关系;它显示了各种消息如何连接到给定频道。在关系方面,我们可能希望专注于 IN_CHANNEL 或 MENTIONS_CHANNEL 标签。
为了限制计算范围并减轻本地系统的负担,该代码尝试限制图中存在的节点和关系的数量。
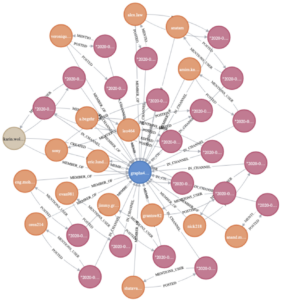
一旦数据经过预处理并转换为适当的节点和关系,我们就可以借助 pandas DataFrames(广泛用于大数据管理和数据科学问题),使用 graphdatascience Python 库来创建内存图对象。graphdatascience 库可以运行各种算法;但是,为了演示目的,我们将在此处精选两种不同的数据科学算法
1. PageRank 算法
我们将运行著名的 PageRank 算法(由 Larry Page 和 Sergey Brin 共同开发),该算法衡量给定节点在通过各种关系连接的节点图中的重要性。我们将使用 graphdatascience 库运行 PageRank 算法,并生成得分最高的节点。结果使用 seaborn 库绘制,该库广泛用于统计数据可视化和数据表示。
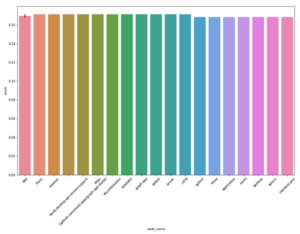
在这里,我们可以看到数据分布相当均匀。请注意,最重要的词是那些与图 API 以及通用计算和软件行业相关的词。如果系统配置可以扩展,或者在云端,则可以在各种更大的图数据集上本地运行类似的分析。
2. Louvain 社区检测
我们还将运行 Louvain 社区检测算法,该算法使用模块化优化来识别社区内部与社区外部的边密度。Louvain 算法是一种分层聚类算法,当跨多个迭代运行时,可以将社区合并到单个节点中并形成压缩图。
在小图上运行社区检测后,我们可以观察到各种节点如何分布在 11 个不同的社区中。分布可以再次使用另一个名为 Plotly 的开源 Python 库进行可视化。Plotly 广泛应用于数据科学行业和学术界,用于可视化实验和结果。
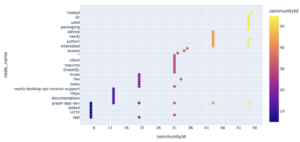
尽管数据集很小,但我们可以在上面看到社区检测如何根据开发周期中各种实用程序或系统部分对数据进行聚类。散点图显示了 “hosted”、“packaging” 等词(出现在应用程序开发生命周期末尾)如何在相似的上下文中讨论,因此位于附近的社区中。
这些是快速原型化图数据库应用程序所需的各种步骤,以及在图数据集上运行复杂数据科学算法的正确工具。点击此处访问 Jupyter notebook,其中解释并执行了上述所有不同步骤。
我希望这篇创客博文能够帮助那些刚接触 Python、数据科学或图数据科学的人了解由充满活力、积极的开发者社区维护的各种可用开源工具。请记住,有时从小处着手并学习快速原型化的技巧,然后再跳入部署和更大系统的实验,这是一个好主意。祝您原型设计愉快,感谢阅读!
Janit Anjaria 是 Aurora Innovation Inc. 的高级软件工程师,他目前致力于为自动驾驶汽车构建高清晰度 3D 地图。在加入 Aurora 之前,Janit 曾在 Uber Advanced Technology Group 的自动驾驶汽车地图团队工作。在 Uber 之前,他在马里兰大学帕克分校空间实验室工作,研究空间数据结构和机器学习。他拥有多样化的专业和学术经验,曾为印度 Flipkart Internet Pvt. Ltd. 构建位置智能平台。在专业和学术生活之外,他是一位开源爱好者,曾为 Apache Solr 和 LibreOffice 做出贡献,并且自 2011 年以来一直是 Linux 用户。
Anaconda 正在 月度博客系列 中扩大其最活跃和最受尊敬的社区成员的声音。如果您是一位创客,一直在寻找机会讲述您的故事、详细阐述您最喜欢的项目、教育您的同行并建立您的个人品牌,请考虑提交摘要。有关更多详细信息并访问丰富的教育数据科学资源和讨论主题,请访问 Anaconda Nucleus。
与我们的专家之一交流,为您的 AI 之旅寻找解决方案。

