Excel 中的 Python
2024 年 10 月 9 日

对于零售和电子商务公司而言,有效利用客户数据对于提高满意度、增强客户保留率和增加销售额至关重要。然而,情感检测、销售趋势监控和客户流失预测等高级分析通常需要 Excel 以外的工具,迫使团队在平台之间切换并依赖其他软件。现在,Python 已集成到 Excel 中,这些复杂的技术可以直接在您的电子表格中使用,将 Excel 的熟悉性与 Python 的分析能力相结合。
在这篇文章中,我们将探讨 Excel 中的 Python 如何通过情感分析、销售趋势分析和客户流失预测中的实际应用来转变客户洞察。从识别客户对您产品的感受,到预测哪些订阅者可能离开,每个示例都演示了 Python 的功能如何无缝地增强 Excel 的功能。现在,您可以轻松进行复杂的分析,使数据驱动的决策比以往任何时候都更快、更易于访问。
要开始在 Excel 中使用 Python,只需键入“=py(”,编辑器将打开,允许您应用 Python 函数、访问强大的库并执行高级分析——所有这些都无需离开您的电子表格。无论是分析客户评论还是预测客户流失,Excel 中的 Python 都使任何技能水平的团队都可以轻松进行数据科学。
每天,客户都会留下评论,这些评论提供了关于他们的体验、满意度水平甚至产品改进的宝贵见解。然而,手动分析大量的评论可能既耗时又主观。Excel 中的 Python 提供了一个高效的解决方案,可以直接在您的电子表格中进行情感分析,使您可以轻松地将评论分类为正面、负面或中性。
在本例中,我们将逐步介绍如何使用 NLTK 的文本处理工具对客户评论数据执行情感分析。这种方法利用自定义的正面和负面词语列表来准确分类情感,使您无需复杂的设置即可发现可操作的见解。
首先,我们需要将评论数据加载到 Excel 中并对其进行清理以进行分析。假设我们有一个客户评论数据集,包括文本和额外的元数据,如评分。导入后,Python 的 Pandas 库可以帮助我们格式化和清理数据,以确保数据已准备好进行情感分析。
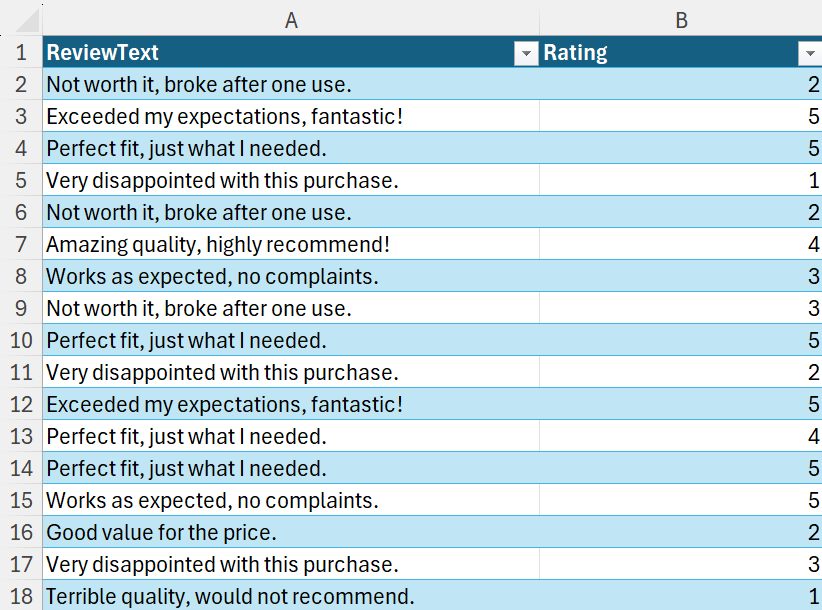
# Load review data from Excel
df = xl("Table3[#All]", headers=True)
# Import NLTK resources
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Define stopwords for cleaning
stop_words = set(stopwords.words('english'))
# Function to clean and tokenize text
def clean_text(text):
tokens = word_tokenize(text.lower()) # Lowercase and tokenize
return [word for word in tokens if word.isalpha() and word not in stop_words]
# Apply text cleaning
df['CleanedReview'] = df['ReviewText'].apply(clean_text)这种快速设置为我们提供了评论文本和任何相关评分的有序视图,为我们将要分析的情感提供了基础数据。
在不依赖其他库的情况下,我们将使用自定义的正面和负面词语列表来分类情感。这种方法根据指示正面或负面情绪的词语的存在,为每个评论分配一个情感。
# Define positive and negative word lists
positive_words = ["good", "great", "excellent", "love", "amazing", "satisfied", "happy"]
negative_words = ["bad", "terrible", "poor", "hate", "disappointed", "unsatisfied", "worst"]
# Function to calculate sentiment based on word lists
def analyze_sentiment(review_tokens):
pos_count = sum(1 for word in review_tokens if word in positive_words)
neg_count = sum(1 for word in review_tokens if word in negative_words)
return "Positive" if pos_count > neg_count else "Negative" if neg_count > pos_count else "Neutral"
# Apply sentiment analysis
df['Sentiment'] = df['CleanedReview'].apply(analyze_sentiment)此分析为每个评论提供一个情感评分,指示其极性。通过快速筛选,您可以按情感细分评论,帮助您识别客户反馈的总体基调。
在计算出情感评分后,我们可以可视化正面、中性和负面评论的分布。此概述使我们能够快速评估客户的总体情绪。
# Reorder the data with specific order and colorssentiment_order = ['Negative', 'Neutral', 'Positive']colors = ['red', 'grey', 'green']
# Plot with ordered categoriesdf['Sentiment'].value_counts().reindex(sentiment_order).plot( kind='bar', color=colors)
plt.title("Sentiment Analysis of Customer Reviews")plt.xlabel("Sentiment")plt.ylabel("Number of Reviews")sns.despine()plt.show()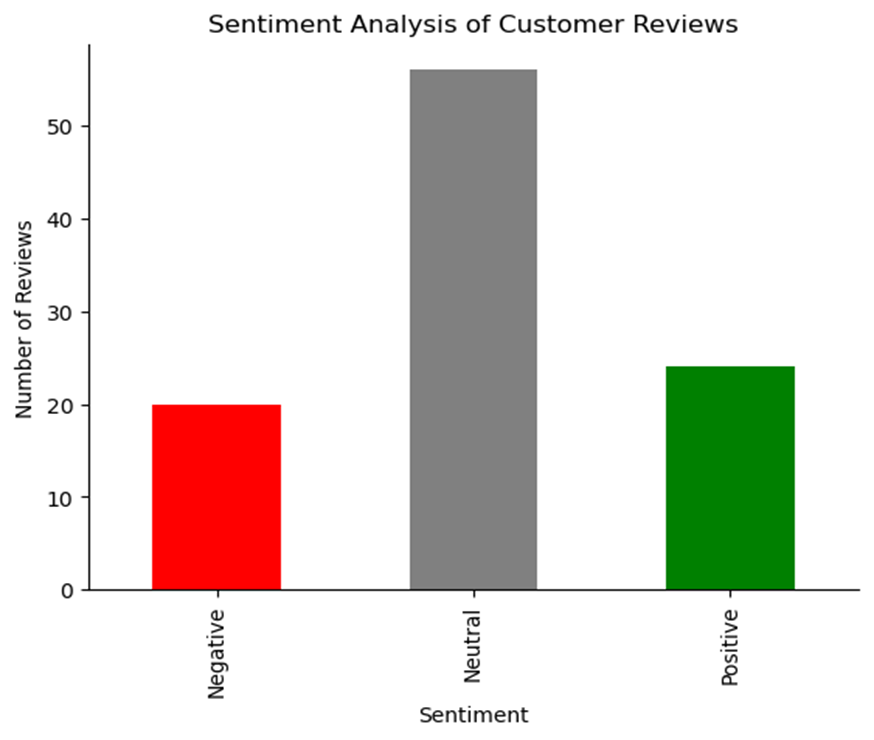
通过使用 Python 将情感分析集成到 Excel 中,零售和电子商务团队可以快速捕获客户情感,并使用该信息来指导产品改进、客户支持和营销策略。借助 Python 的文本分析功能,您可以在手动所需时间的一小部分内对数百或数千条评论进行分类,从而及时了解客户满意度。这种无缝的工作流程将强大的文本分析直接引入 Excel,使其成为客户洞察的可访问的、宝贵的工具。
对于零售和电子商务公司而言,了解按产品类别的销售趋势对于战略规划和库存管理至关重要。通过分析这些趋势,企业可以识别受欢迎的产品线,预测季节性需求,并相应地调整库存水平。然而,执行详细的趋势分析通常需要在工具之间切换,特别是对于高级数据操作。借助 Excel 中的 Python,您可以直接在电子表格中进行全面的销售趋势分析,从而更轻松地可视化关键见解并采取行动。
在本例中,我们将使用 Excel 中的 Python 按产品类别分析每月销售趋势,以帮助识别哪些类别正在增长、稳定或下降。这种方法不仅突出了趋势,还使企业能够就产品放置、促销和库存做出数据驱动的决策。
首先将销售数据加载到 Excel 中,并使用 Python 按月和类别对其进行组织。假设我们有一个数据集,其中包括产品类别、销售额和日期。借助 Python 的 Pandas 库,我们可以快速设置此数据以进行时间序列分析。
# Load sales data from Excel tabledf = xl("SalesData[#All]", headers=True)
# Group by month and category and sum the salesdf['Month'] = df['Date'].dt.to_period('M')monthly_sales = df.groupby(['Month', 'Category'])['Sales'].sum().reset_index()monthly_sales.Month = monthly_sales.Month.dt.to_timestamp()monthly_sales我们可以将此 Python 单元格的输出设置为“Excel 值”,以便 DataFrame monthly_sales 从单元格 E1 溢出到网格。
现在我们可以使用 Anaconda 工具箱快速创建一个图表来可视化销售趋势。
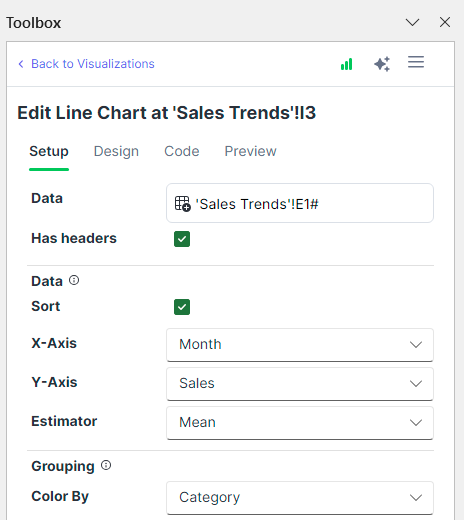
我们创建一个新图表,选择折线图,然后像这样配置设置
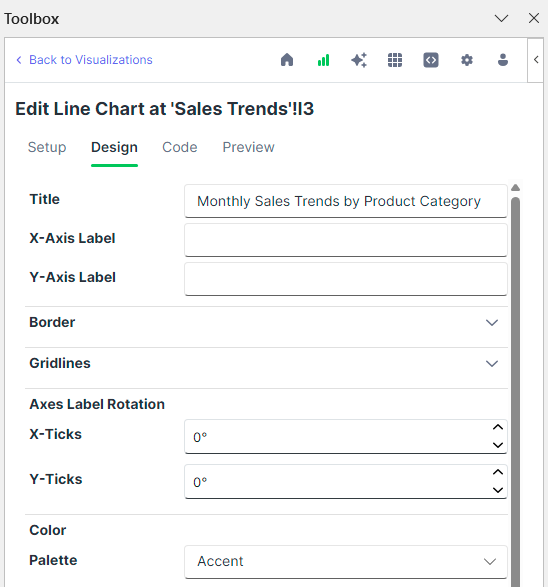
我们可以在“设计”选项卡上设置一些视觉偏好,例如调色板、图表标题和线宽。
当我们对我们的选择感到满意时,我们可以在“预览”选项卡上预览图表。
为了微调图表的外观,我们可以选择在“代码”选项卡上编辑生成的代码。
当我们完成图表设置后,我们可以点击“创建”按钮将图表加载到工作簿中的单元格中。
完成的图表如下所示
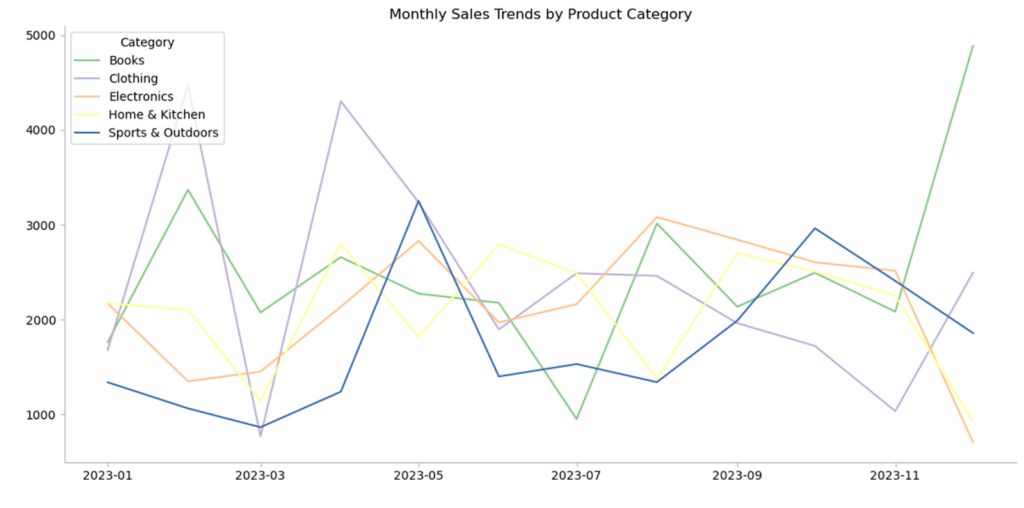
数据准备好后,我们可以可视化每个类别的销售趋势。Excel 中可访问的 Python 的 Matplotlib 库允许我们为每个产品类别创建折线图,从而可以轻松地一目了然地识别季节性模式或新兴趋势。
# Plot monthly sales trends by category
plt.figure(figsize=(10, 6))
for category in monthly_sales['Category'].unique():
category_data = monthly_sales[monthly_sales['Category'] == category]
plt.plot(category_data['Month'].astype(str), category_data['Sales'], label=category)
plt.title("Monthly Sales Trends by Product Category")
plt.xlabel("Month")
plt.ylabel("Sales")
plt.legend(title="Category")
plt.xticks(rotation=45)
plt.show()现在我们已经清楚地可视化了趋势,让我们量化哪些类别的表现最佳。通过计算每个类别的总销售额或识别最高的增长率,我们可以查明哪些产品线正在获得关注,哪些可能需要关注。
# Calculate total sales and growth rate for each category
category_summary = monthly_sales.groupby('Category')['Sales'].agg(['sum', 'mean'])
category_summary['Growth Rate'] = monthly_sales.groupby('Category')['Sales'].pct_change().fillna(0).mean()
# Sort categories by total sales to identify top-performing product lines
top_categories = category_summary.sort_values(by='sum', ascending=False)
top_categories| 总和 | 平均值 | 增长率 | |
| 类别 | |||
| 书籍 | 29880.73 | 2490.061 | 0.187185 |
| 服装 | 28519.73 | 2376.644 | 0.187185 |
| 电子产品 | 25819.73 | 2151.644 | 0.187185 |
| 家居与厨房 | 25075.16 | 2089.597 | 0.187185 |
| 运动与户外 | 21248.69 | 1770.724 | 0.187185 |
借助 Excel 中的 Python,按产品类别进行销售趋势分析成为一个简化的过程。您可以轻松探索哪些产品类别推动销售增长,可视化每月趋势,并计算增长率或总销售额等指标——所有这些都在您的 Excel 工作流程中完成。
通过将 Python 的数据分析能力与 Excel 的熟悉性相结合,零售和电子商务企业可以及时获得洞察力,适应季节性需求变化,并优化库存水平,而无需其他工具。这种无缝集成使分析师和非技术团队成员都能够利用高级趋势分析,从而帮助推动更明智的决策,从而提高整体业务绩效。
对于电子商务企业而言,客户流失(即客户停止参与或取消订阅的比率)可能是一个重大挑战。了解订阅者流失的原因并预测谁可能离开对于制定有效的客户保留策略至关重要。传统工具可以处理一些分析,但预测客户流失需要更高级的技术。借助 Excel 中的 Python,您现在可以构建一个预测模型,以直接在电子表格中识别高风险客户,从而帮助您采取积极措施来挽留他们。
在本例中,我们将使用 Python 根据模拟客户数据预测电子商务订阅者的客户流失。通过结合过去的行为、人口统计数据和购买历史数据,我们可以开发一个模型来标记有流失风险的订阅者。这种方法使企业能够将客户保留工作精确地定位在最需要的地方。
首先,加载订阅者数据,包括相关特征,如人口统计数据、购买频率和参与度评分。此数据将作为我们客户流失预测模型的输入。
# Load subscriber data from Excel
df = xl("SubscribersData[#All]", headers=True)数据应包括年龄、参与度评分、平均购买价值以及二进制“客户流失”列等特征,指示每个订阅者是否已流失。此数据构成了我们预测模型的基础。
使用 Python 的 scikit-learn 库,我们可以开发一个基本的逻辑回归模型,这是二元分类问题(如客户流失预测)的常用选择。逻辑回归提供了清晰的可解释性,使人们更容易理解每个特征对客户流失概率的影响。
from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_reportfrom sklearn.preprocessing import StandardScaler
# Separate features and targetX = df[['Age', 'EngagementScore', 'AvgPurchaseValue', 'NumPurchases']] # Feature columnsy = df['Churn'] # Target column
# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize the scaler and fit it to the training datascaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
model = LogisticRegression()model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Evaluate model performanceprint("Accuracy:", accuracy_score(y_test, y_pred))print(classification_report(y_test, y_pred))准确率:0.66
精确率 召回率 F1 分数 支持
0 0.67 0.64 0.65 75
1 0.65 0.68 0.67 75
准确率 0.66 150
宏平均值 0.66 0.66 0.66 150
加权平均值 0.66 0.66 0.66 150
此模型根据每个订阅者的数据计算其流失的可能性。准确率和精确率等指标可帮助我们评估模型的有效性,为进一步改进(如果需要)提供基础。
在模型训练完成后,我们可以将其应用于整个数据集,以预测哪些订阅者有流失风险。此列表允许企业优先考虑针对风险最高的客户的客户保留策略。
# Predict churn probabilities for all subscribers
df['ChurnProbability'] = model.predict_proba(X)[:, 1]
# Identify subscribers with a high churn probability
at_risk_subscribers = df[df['ChurnProbability'] > 0.5] # Threshold for high risk
at_risk_subscribers.head()| 客户 | 年龄 | 参与度评分 | 平均购买价值 | 购买次数 | 客户流失 | 客户流失概率 |
| 0 | 56 | 0.46 | 271.71 | 45 | 1 | 0.930341 |
| 1 | 46 | 0.55 | 231.57 | 18 | 0 | 0.999997 |
| 3 | 60 | 0.39 | 288.63 | 21 | 0 | 1 |
| 4 | 25 | 0.96 | 94.52 | 15 | 0 | 0.662107 |
| 6 | 56 | 0.2 | 433.66 | 35 | 1 | 1 |
“客户流失概率”列提供介于 0 和 1 之间的分数,表示每个订阅者的客户流失风险。概率高于 0.5 的订阅者被标记为高风险。
借助 Excel 中的 Python,电子商务公司可以简化客户流失预测,而无需离开其电子表格环境。通过使用逻辑回归,您可以构建一个简单而有效的模型,该模型可以标记有流失风险的订阅者,从而实现有针对性的干预,从而提高客户保留率。这种方法节省了时间,并使非技术团队能够将高级分析直接整合到 Excel 中。
通过将 Python 集成到 Excel 中,零售和电子商务公司可以将他们的数据分析提升到一个新的水平,而无需离开熟悉的 Excel 环境。从提供客户反馈快速洞察的情感分析,到保持库存优化的趋势分析,再到识别高风险订阅者的客户流失预测模型,Excel 中的 Python 为有影响力的决策提供了一个全面的工具包。
此集成消除了对外部软件的需求,并使非技术团队能够轻松利用高级分析。通过结合这两种工具的优势,零售和电子商务企业可以将原始数据转化为可操作的见解,从而支持从营销和客户服务到库存和客户保留策略的各个方面。无论您是 Python 新手还是经验丰富的分析师,Excel 中的 Python 都能让您在您熟悉且每天使用的软件中利用数据获得竞争优势。