新闻
2022 年 8 月 24 日
介绍《Numerically Speaking》:Anaconda 播客


本文由 Intel AI 框架工程师 Vasilij Litvinov 撰写。
AI 和数据科学正在快速发展,这带来了越来越多的数据,使我们能够得出日益复杂的想法和解决方案。
但另一方面,我们看到这些进步正在将重点从价值提取转移到系统工程。此外,硬件能力的增长速度可能快于人们学习如何正确利用它们的速度。
这种趋势要么需要增加一个新的职位,即所谓的“数据工程师”,要么需要数据科学家处理与基础设施相关的问题,而不是专注于数据科学的核心部分——产生见解。其中一个主要原因是缺乏针对数据科学家的优化数据科学和机器学习基础设施,这些数据科学家本质上不一定是软件工程师——这可以被认为是两个独立的,有时重叠的技能组合。
我们知道数据科学家是习惯性动物。他们喜欢 Python 数据栈中熟悉的工具,例如 pandas、Scikit-learn、NumPy、PyTorch 等。然而,这些工具通常不适合并行处理或 TB 级数据。
Anaconda 和 Intel 正在合作解决数据科学家最关键和核心的问题:如何使他们熟悉的软件栈和 API 更具可扩展性和速度?
本文旨在介绍 Modin(又名 Intel® Distribution of Modin),它是 Intel® oneAPI AI Analytics Toolkit (AI Kit) 的一部分,现在可以从 Anaconda 的默认频道(以及 conda-forge)获取。
虽然 pandas 是“行业标准”,但在许多情况下,它本质上是单线程的,这使得它在处理海量数据时速度很慢(甚至对于不适合内存的数据集会停止工作)。
虽然有很多其他旨在解决这些问题的替代方案(例如 Dask、pySpark、vaex.io 等),但这些库都没有提供完全兼容 pandas 的接口——用户必须相应地“修复”他们的工作负载。
Modin 可以为最终用户提供什么?它试图坚持“工具应该为数据科学家服务,而不是反过来”的理念。因此,它为 pandas 提供了一个非常简单的、即插即用的替代方案——您只需将“import pandas as pd”语句替换为“import modin.pandas as pd”,即可在许多用例中获得更好的可扩展性。
通过消除“将 pandas 工作流程重写为 X 框架”的步骤,可以加快见解的开发周期。
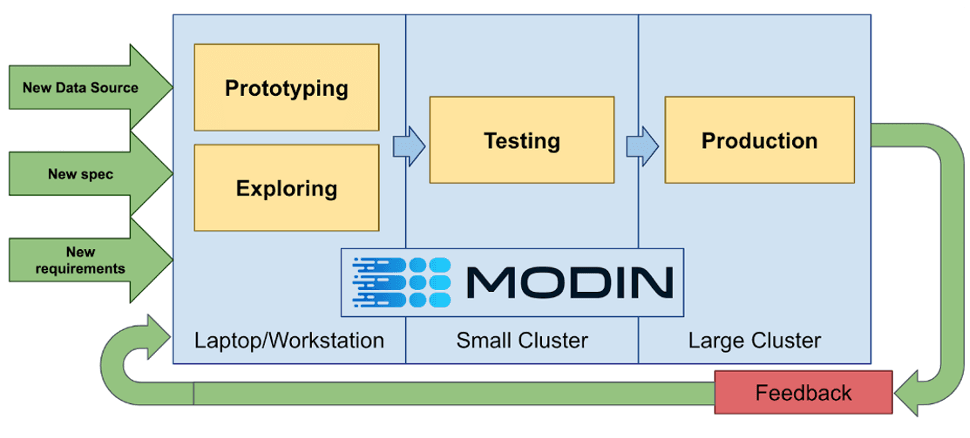
Modin 更好地利用硬件的方式是通过网格分割 dataframe,这使得某些操作可以以并行分布式方式运行,无论是单元格级、列级还是行级。
对于某些操作,可以利用 OmniSci 引擎的实验性集成,以更好地利用多核的强大功能。

通过 AI Kit 或 Anaconda 默认频道(或 conda-forge)安装 Modin,还可以使用实验性的、速度更快的 OmniSci 后端,只需进行一些简单的代码更改即可激活。
import modin.config as cfg
cfg.Engine.put('native')
cfg.Backend.put('omnisci')
import modin.experimental.pandas as pd废话不多说,让我们看看基准测试。
有关不同 Modin 引擎的详细比较,请参阅社区测量的微基准测试:https://modin.org/modin-bench/,它跟踪提交到 Modin 仓库的不同数据科学操作的性能。
在本文中,让我们使用更相关的端到端更大规模的基准测试,在基于 Intel® Xeon® 8368 Platinum 的服务器上运行(参见下面的完整硬件信息),通过 Modin 使用 OmniSci。
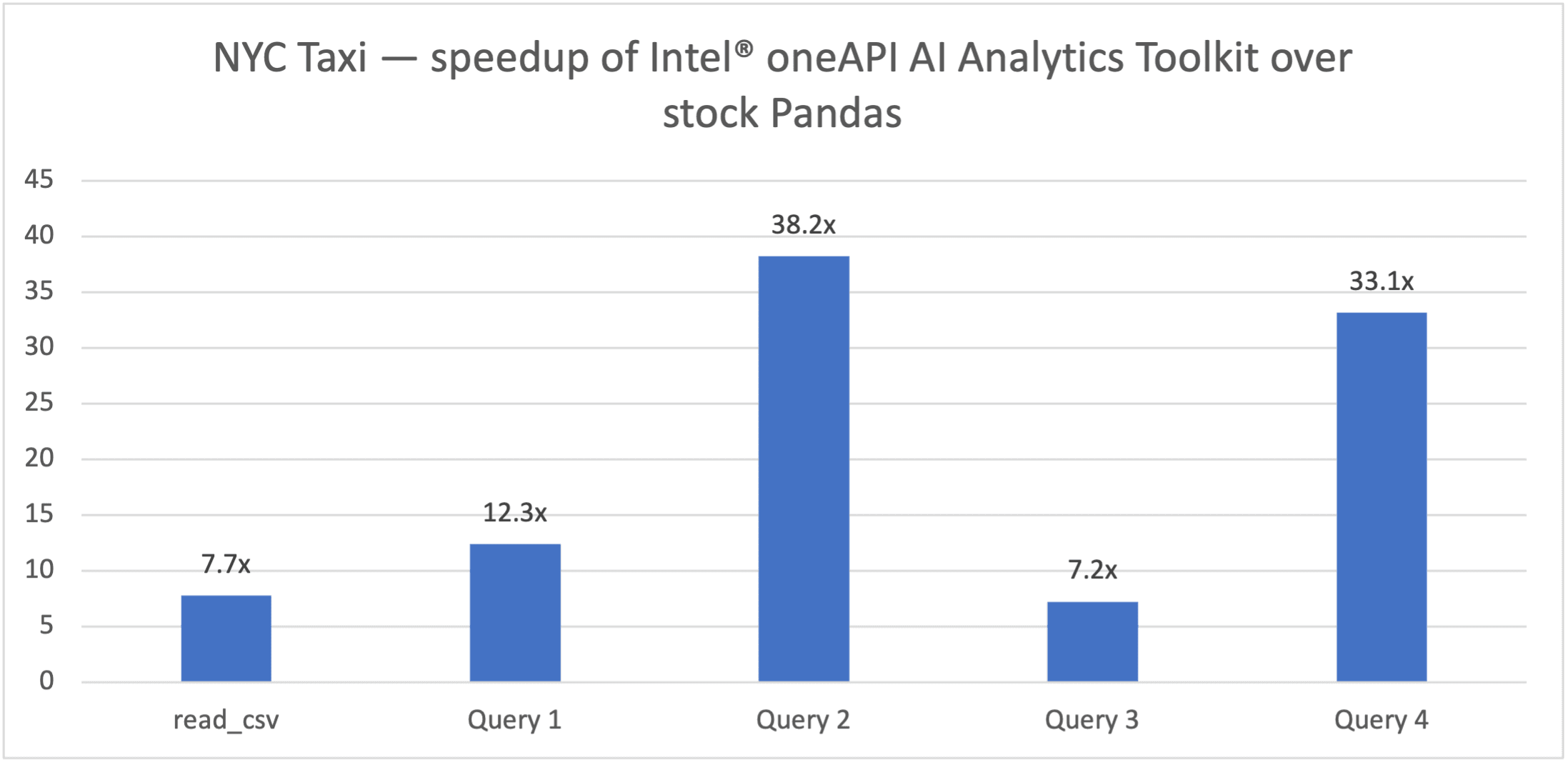
图 3. 运行 NYC Taxi(2 亿条记录,79.2GB 输入数据集)

图 4. 运行 Census(2100 万条记录,2.1GB 输入数据集)
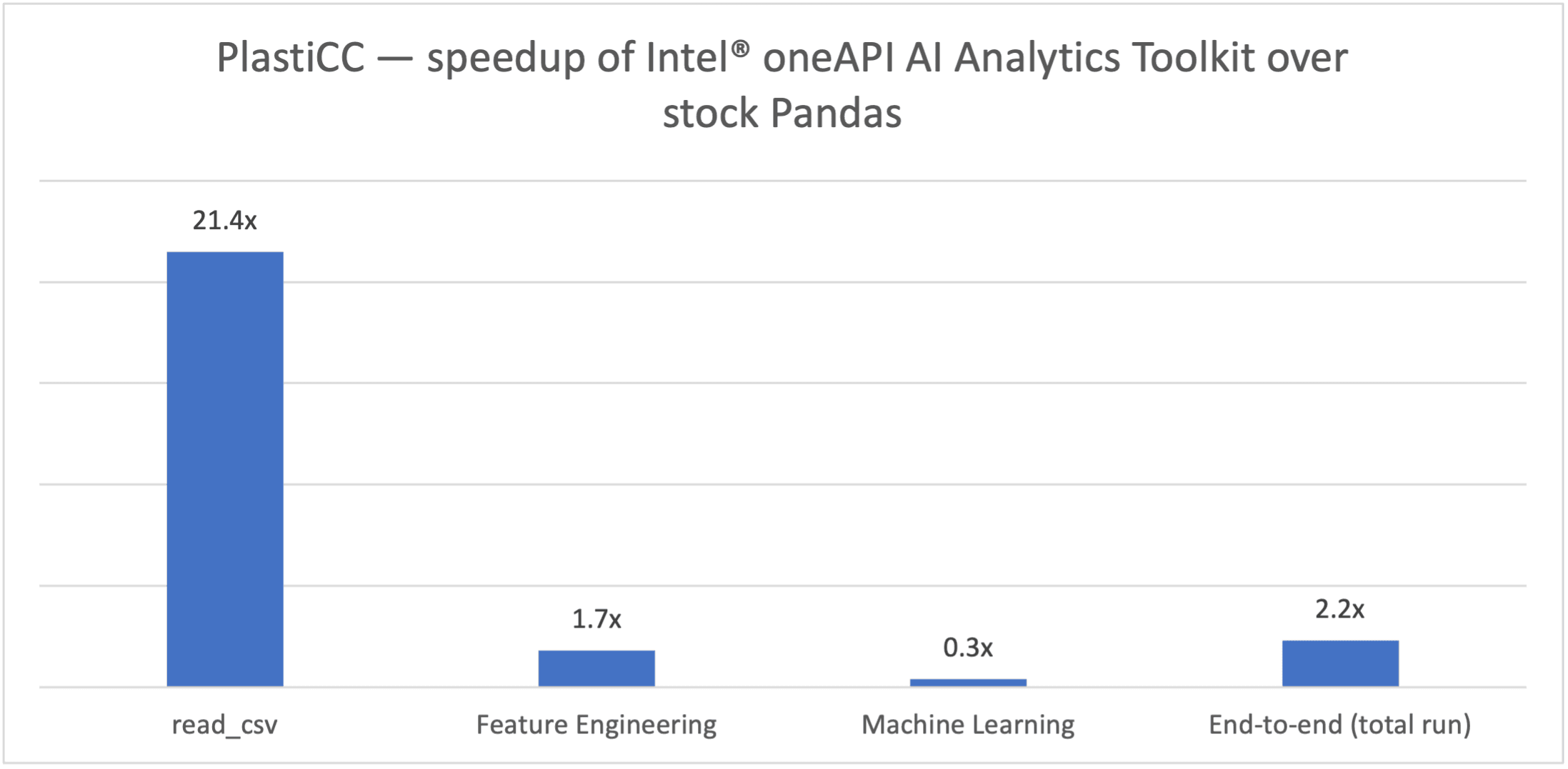
图 5. 运行 PlastiCC(4.6 亿条记录,20GB 输入数据集)
硬件信息:1 个节点,2 个第三代 Intel Xeon 8368 Platinum,C620 主板,512GB (16 插槽/32GB/3200) DDR4 内存,微代码 0xd0002a0,HT 开启,Turbo 开启,Centos 7.9.2009,3.10.0-1160.36.2.el7.x86_64,1 个 Intel 960GB SSD 操作系统驱动器,3 个 Intel 1.9TB SSD 数据驱动器。 软件信息:Python 3.8.10, Pandas 1.3.2, Modin 0.10.2, OmnisciDB 5.7.0, Docker 20.10.8,由 Intel 于 2021 年 10 月 5 日测试。
如果在一个节点上运行不足以处理您的数据,Modin 支持在集群上运行,设置非常简单(对于 Ray 驱动的集群,请参阅 https://docs.rayai.org.cn/en/latest/cluster/cloud.html#manual-ray-cluster-setup 进行设置;有关 Dask,请参考 https://docs.dask.org.cn/en/latest/how-to/deploy-dask-clusters.html)。
您还可以使用实验性的 XGBoost 集成,它将自动为您利用基于 Ray 的集群,而无需任何特殊设置!
了解了所有这些新信息后,请立即尝试通过 Anaconda 安装 Modin 和 Intel® oneAPI AI Analytics Toolkit!
参考资料
通知和免责声明
性能因使用、配置和其他因素而异。 详情请访问 www.Intel.com/PerformanceIndex。
性能结果基于配置中所示日期的测试,可能未反映所有公开可用的更新。 详见配置披露。
没有产品或组件可以是绝对安全的。
您的成本和结果可能会有所不同。
Intel 技术可能需要启用的硬件、软件或服务激活。
©Intel 公司。 Intel、Intel 徽标和其他 Intel 标志是 Intel 公司或其子公司的商标。 其他名称和品牌可能是其他方的财产。
与我们的专家之一交流,为您的 AI 之旅寻找解决方案。
