创客博客系列
2022 年 3 月 24 日
在开源中找到一席之地


这可能就是你!点击此处提交我们的创客博客系列的摘要。
大量的生命科学研究依赖于重组 DNA 分子的构建或分析。这些分子的精确序列对于它们所属的科学工作的可重复性至关重要。每篇出版物通常都附带对克隆策略的临时描述。不幸的是,大多数已发表的克隆策略要么不完整,要么含糊不清,有些则完全错误。手动遵循克隆策略是一个艰巨的过程,这可能是为什么如此多的此类错误通过了同行评审过程的原因。Pydna 是 Python 的一个扩展,用于紧凑地表达克隆策略。在 Jupyter Notebook 中使用 Pydna 可以被具有 Python 初步知识的用户阅读,因为叙述格式类似于传统的自由形式描述。这些克隆策略很容易通过简单地重新执行 notebook 来验证。另一个好处是使用自动集成服务(如 GitHub Actions)进行自动验证。
代谢工程是一个生命科学领域,通常涉及调节代谢途径以实现代谢物过量生产,旨在为具有生物技术意义的分子创建所谓的细胞工厂。细胞工厂被认为在向绿色经济转型中发挥未来作用。在我自己的实验室中,我们尝试通过将新基因插入面包酵母(基本上是与在家制作面包相同的生物体)来生产辣椒素分子中产生热量的脂肪酸部分。
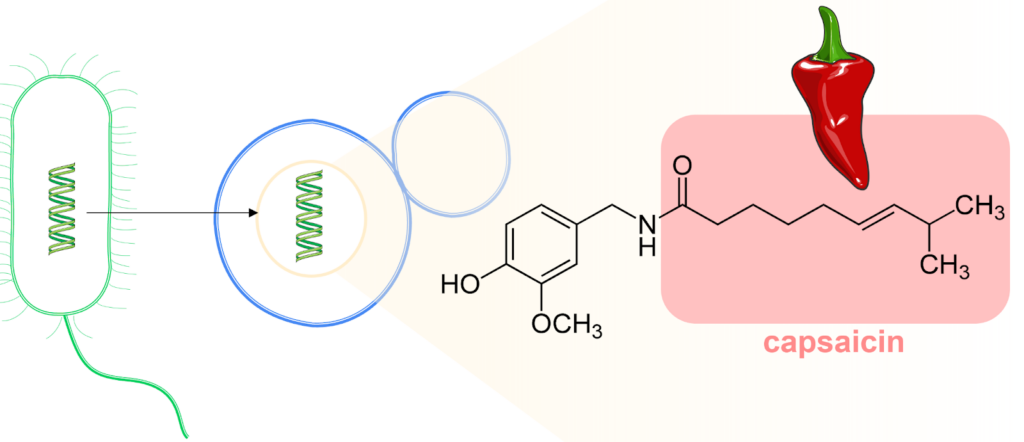
图 1:来自大肠杆菌(绿色)的基因被转移到面包酵母细胞(蓝色)中。最终目标是生产辣椒素(红色框)中的脂肪酸。图片由 Cláudia Barata,米尼奥大学提供。
我们需要确保新的 DNA 分子通过按照计划将较小的 DNA 分子组合成较大的分子(重组 DNA)在细胞内稳定维持和发挥功能,这个计划通常被称为克隆策略。
那么为什么博客标题如此具有挑衅性呢?事实证明,许多涉及重组 DNA 的学术出版物并未包含用于实验的 DNA 构建体的完整、明确的克隆策略。克隆策略有时是通用的,例如“基因 X 被克隆到质粒 Y 中,生成质粒 Z。”(质粒是一个小的环状 DNA 片段,可以自行复制,而此处的克隆仅指将 DNA 分子连接在一起。)这不足以重建质粒 Z,导致对质粒 Z 的研究无法重复。未能记录克隆策略中的精确工作既是不幸的,也是不必要的,因为它们由一系列简单的单元操作串联而成,结果几乎总是确定性的。
克隆项目的手动规划非常常见,其中使用点击式 DNA 编辑器以及从数据库或 DNA 测序实验中获得的序列文件。这些数据文件、序列登录号、PCR 引物序列等,以及对执行的操作的详细描述,对于在体外或计算机中重建最终构建体序列是必需的。即使提供了这些信息,除非手动重新创建每个步骤,否则也无法保证其正确和完整。然而,这可能并不容易,因为对于应包含哪些信息或如何描述克隆策略,没有广泛采用的标准。
克隆策略可以使用 pydna 包在 Python 中正式表达。Pydna 可以以紧凑的方式处理最常见的亚克隆技术(即,将 DNA 分子缝合在一起的技术)。Jupyter Notebook 支持线性叙述格式,该格式通常已用于描述克隆实验。
在酵母中合成辣椒素脂肪酸的背景下进行的几种基因修饰之一是来自大肠杆菌的脂肪酸合酶基因 AcpH(酰基载体蛋白磷酸二酯酶)的表达。将此基因克隆到名为 pYPKa 的质粒中将用作如何使用 pydna 的一个简单示例。
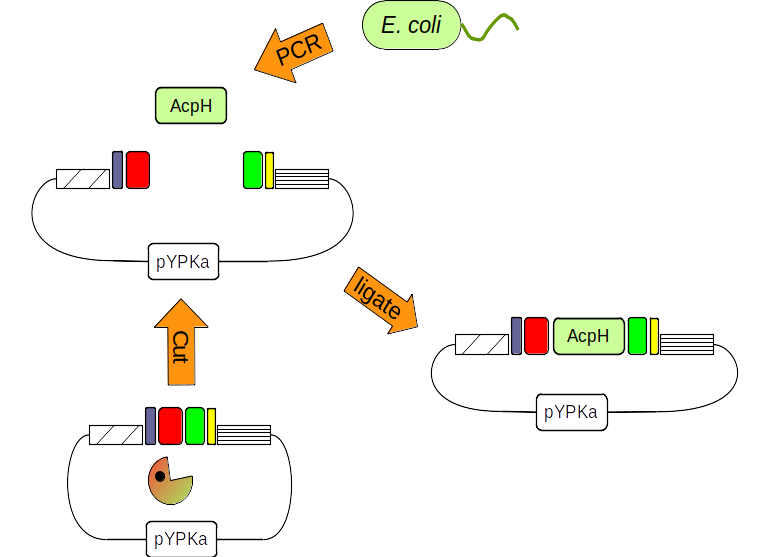
图 2:pYPka 质粒被限制性内切酶(吃豆人)切割。来自大肠杆菌的 AcpH 基因通过 PCR 扩增。最后,两个 DNA 分子通过连接组合在一起。
第一步是从 pydna 导入一些必要的功能。

pYPKa 质粒从本地文本文件中读取。这个 DNA 分子是环状的。

限制性内切酶 AjiI 从 Python 包 Biopython 导入。(限制性内切酶是一种分子剪刀,可以以可预测的方式切割 DNA 链。)

环状质粒使用在单个独特位置切割质粒的限制性内切酶线性化。

需要访问 Genbank 才能下载 AcpH 基因。美国国家生物技术信息中心 (NCBI) 提供了一个名为“E-utilities”的 API,可以从 Python 访问。在执行此脚本之前,请更改下面的电子邮件地址,因为在使用 e-utilities 时,您应始终提供电子邮件地址。

AcpH 基因从下面的 Genbank 下载。

下载的基因可以在这里查看:NC_000913 424337-424918。我们通过将 DNA 序列作为字符串打印出来来检查该基因

基因是通过使用聚合酶链式反应 (PCR) 从源 DNA(通常称为模板 DNA)复制的。相对于模板 DNA,相对较短的特定 DNA 片段被大量复制。(顺便说一句,PCR 也用于检测 COVID-19 等传染病。)下面的两个 PCR 引物(868 和 867)用于 PCR 扩增 AcpH 基因。PCR 引物是用于指导 PCR 基因复制过程的短单链 DNA 片段。

基因通过使用两个 PCR 引物通过 PCR 合成
我们可以像这样可视化引物如何位于 AcpH 基因的每一端
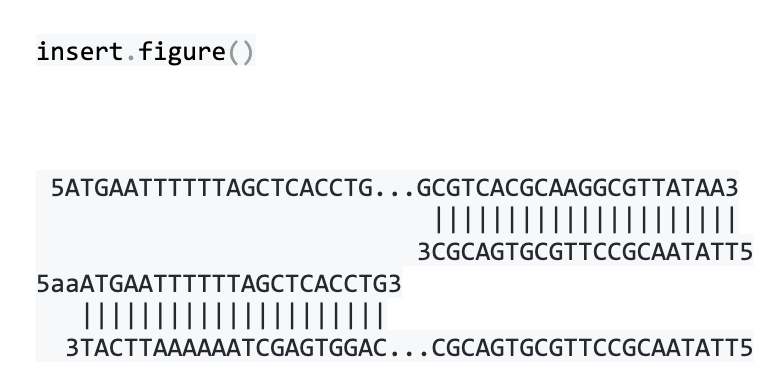
最终载体由两个线性 DNA 分子连接在一起

我们只需将两个线性 DNA 分子加在一起,并告诉 pydna 我们想要使用 looped 方法的环状序列。然后,我们最终可以使用 write 方法将质粒写入文件。

包含上述完整示例的 Jupyter notebook 可在此处获得。
我们在上一个示例中制作的质粒不足以使基因活跃。基因通常需要一个 启动子和一个 终止子才能进行转录。启动子和终止子是启动和结束 转录的 DNA 片段,转录会生成基因的 RNA 副本 (mRNA)。
同源重组和 Gibson 组装技术通常用于组装更大、更复杂的重组 DNA 分子。这些技术需要在 DNA 末端有短的相同 DNA 序列片段。Pydna 实现了一种 DNA 组装算法,该算法仅依赖于分子的 DNA 序列。在下面的示例中,我们使用 pydna 模拟同源重组,以为我们在上一个示例中克隆的基因制作表达质粒。
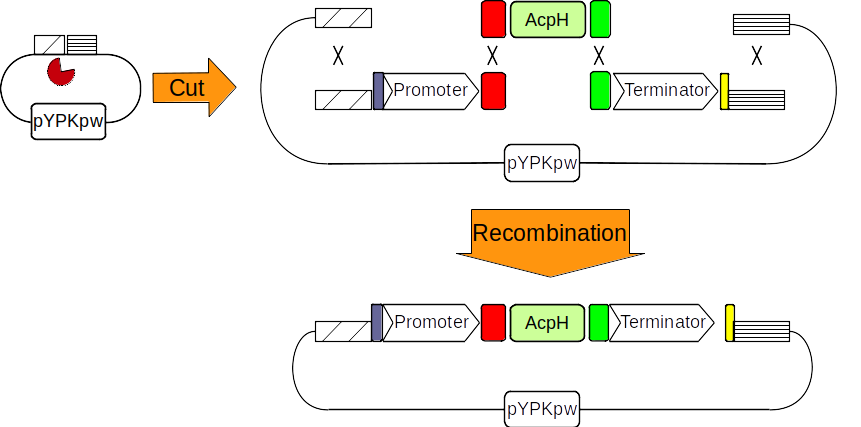
图 3:pYPkpw 质粒被限制性内切酶(吃豆人)切割。启动子、AcpH 基因和终止子通过 PCR 获得。四个线性 DNA 分子通过共享的 DNA 序列重组在一起,形成一个新的环状分子。
我们从本地文件读取 DNA 序列。

pYPKa_Z_RPL17A 和 pYPKa_E_RPL16B 质粒与上一个示例中构建的质粒相似,但分别携带启动子和终止子。我们使用三对 PCR 引物合成三个 PCR 产物
质粒载体通过用限制性内切酶 EcoRV 消化而线性化。

组装算法会查看参数中的 DNA 序列,丢弃短于某个限制的序列。

组装类有两种方法可供选择,assemble_circular 和 assemble_linear,具体取决于组装的目标。我们对环状组装感兴趣。

我们为 pYPK0_RPL17A_EcacpH_RPL16B 载体获得了两个环状产物。这是预期的,因为这两个分子互为反向互补。
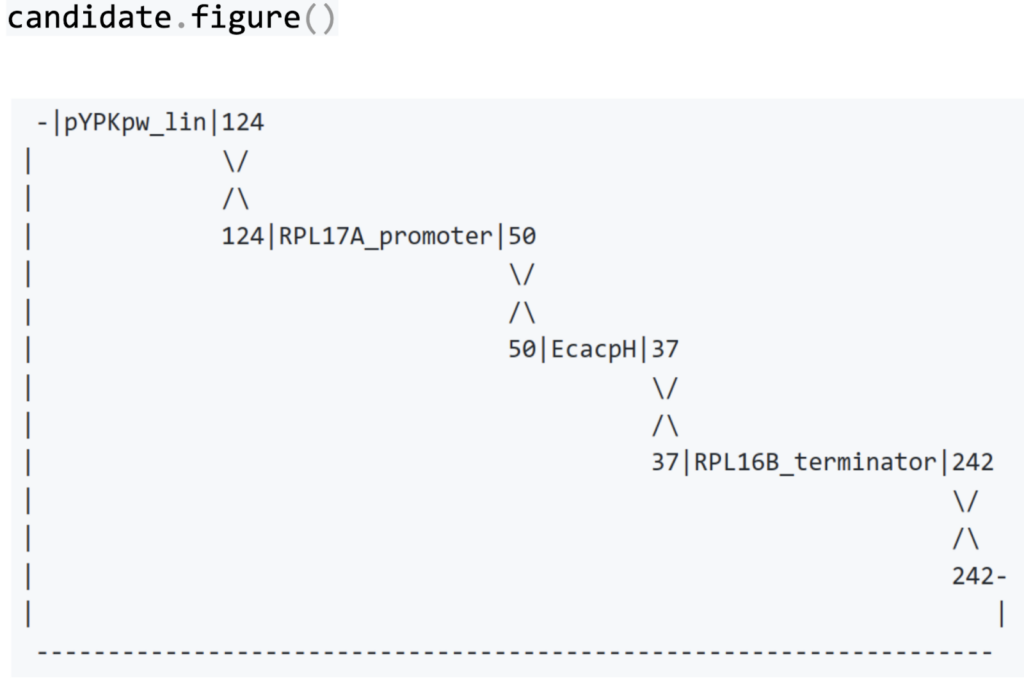
我们可以可视化四个线性 DNA 分子如何在新的环状质粒中结合在一起。下图中的数字是共享相同序列的长度。
上面的代码示例为了简洁起见省略了一些必要的步骤。包含完整同源重组示例的 Jupyter notebook 可在此处获得。
当前采用 pydna 的一个障碍是一些生物学家仍然对与“编写代码”相关的略微负面的看法。然而,由于该领域产生的数据量不断增加,编程可能会成为未来生物学家工具箱中不可或缺的一部分。Pydna 和类似的工具可以帮助生命科学领域争取可重复性。
这项工作由葡萄牙科学技术基金会 (FCT) 通过 FatVal PTDC/EAM-AMB/032506/2017 项目资助,该项目由国家基金通过 FCT I.P. 资助,并由 ERDF 通过 COMPETE2020 – Programa Operacional Competitividade e Internacionalizacão (POCI) 资助。CBMA 由 UIDB/04050/2020 战略计划资助,该计划由国家基金通过 FCT I.P. 资助。
Björn Johansson 是葡萄牙布拉加米尼奥大学生物学系的助理教授,他在那里领导一个小型研究小组并教授生物学。他的研究领域是酵母生理学和代谢工程,他的团队正在尝试扩大面包酵母的代谢范围,以包括有趣的新产品和底物。在生物学之外,Björn 对生物信息学和开放的可重复科学感兴趣。他也是开源软件爱好者,自 2007 年以来一直在桌面上使用 Linux。
Anaconda 正在通过每月博客系列扩大其一些最活跃和最受珍视的社区成员的声音。如果您是一位创客,一直在寻找机会讲述您的故事、详细阐述您最喜欢的项目、教育您的同行并建立您的个人品牌,请考虑提交摘要。有关更多详细信息并访问丰富的教育数据科学资源和讨论主题(包括关于此博客文章的主题),请访问 Anaconda Nucleus。
与我们的专家之一交流,为您的 AI 之旅找到解决方案。

