Anaconda 观点
2022 年 9 月 22 日
将 Python 推向下一个十年:Anaconda 的 OSS 愿景


即使您不是 Mac 用户,您可能也听说过 Apple 正在从 Intel CPU 切换到他们自己的定制 CPU,他们统称为“Apple Silicon”。 Apple 上一次如此 драматично 地改变其计算机架构是在 15 年前,当时他们从 PowerPC 切换到 Intel CPU。 因此,技术媒体上已经写了很多关于这种转变对 Mac 用户意味着什么的文章,但很少从 Python 数据科学家的角度来看。 在这篇文章中,我将分解 Apple Silicon 对当今 Python 用户意味着什么,特别是那些进行科学计算和数据科学的用户:哪些有效,哪些无效,以及这可能走向何方。
简而言之,Apple 正在将其整个笔记本电脑和台式计算机产品线从使用 Intel CPU 过渡到使用 Apple 自己设计的 CPU。 Apple 成为 CPU 设计商已经将近十年了(自 2012 年发布 iPhone 5 以来),但在 2020 年底之前,他们的 CPU 仅用于 iPhone 和 iPad 等移动设备。 经过多次迭代,技术观察家清楚地看到,Apple 的 CPU,尤其是在 iPad Pro 中,在性能上已经可以与低功耗 Intel 笔记本电脑 CPU 相媲美。 因此,当 Apple 在 2020 年的开发者大会上宣布他们将在未来两年内将整个 Mac 产品线转移到他们自己的 CPU 时,这并不完全出乎意料。 正如承诺的那样,Apple 在 2020 年 11 月发布了首批 Silicon Mac。 它们由 MacBook Air、13 英寸 MacBook Pro 和 Mac Mini 组成,外观与之前的型号相同,但包含 Apple M1 CPU 而不是 Intel CPU。 2021 年 4 月,他们将 M1 添加到 iMac 和 iPad Pro。
那么这些 Apple CPU 有什么优势呢? 根据许多专业评测(以及我们在 Anaconda 这里的测试),M1 的主要优势在于出色的单线程性能和笔记本电脑的电池续航时间得到改善。 重要的是要注意,基准测试是一个棘手的主题,对于 M1 的速度到底有多快存在不同的观点。 一方面,有什么比定量测量性能更客观的呢? 另一方面,基准测试也是主观的,因为评测者必须决定要测试哪些工作负载,以及要与哪些基线硬件和软件配置进行比较。 尽管如此,我们非常有信心,对于“典型用户”(不一定是“数据科学用户”)的工作负载,M1 通常比以前的 Intel Mac 更快,同时功耗更低。
从 CPU 架构的角度来看,M1 与之前的 Intel CPU 有四个显着差异
CPU 架构从 x86 更改为 ARM
Apple 现在设计片上 GPU(而不是来自 Intel 的片上 GPU 或来自 NVIDIA 或 AMD 的独立 GPU 芯片)
来自 iPhone 和 iPad 芯片的自定义 Apple 加速器现在可在 Mac 上使用,例如 Apple 神经网络引擎 (ANE)
系统 RAM 直接焊接到 CPU 封装上,并由 CPU、GPU 和 ANE 核心共享。
我们将在后面的章节中更多地讨论这些更改的影响。
作为软件用户和创建者,我们关于 Apple Silicon 的第一个问题是:我是否需要更改任何内容才能使我的软件继续工作? 答案是:是的,但比您想象的要少。
为了详细说明这一点,我们需要深入研究指令集架构 (ISA)。 ISA 是关于一系列芯片如何在低级别工作的规范,包括机器代码必须使用的指令集。 应用程序和库是为特定的 ISA(和操作系统)编译的,除非重新编译,否则无法直接在具有不同 ISA 的 CPU 上运行。 这就是为什么 Anaconda 为我们支持的每个平台提供不同的安装程序和软件包文件的原因。
Intel CPU 支持 x86-64 ISA(有时也称为 AMD64,因为 AMD 最初在 1999 年提出了这个 64 位 x86 扩展)。 新的 Apple Silicon CPU 使用 ARM 设计的 ISA,称为 AArch64,就像它们所源自的 iPhone 和 iPad CPU 一样。 因此,这些新的 Mac 通常被称为“ARM Mac”,以区别于“Intel Mac”,尽管 ARM 仅定义了 Apple M1 使用的 ISA,但并未设计 CPU。 总的来说,64 位 ARM 架构的命名约定令人困惑,因为不同的人会为同一事物使用略有不同的术语。 您可能会看到有些人将这些 CPU 称为“ARM64”(Apple 在其开发者工具中就是这样做的),或者略微不正确地称为“ARMv8”(这是一个描述 AArch64 和 AArch32 的规范)。 即使在 conda 中,您也会看到平台名称 osx-arm64(用于在 M1 上运行的 macOS)和 linux-aarch64(用于在 64 位 ARM CPU 上运行的 Linux)。 在本文的其余部分,我们将使用“ARM64”,因为它比“Apple Silicon”更短,并且比“AArch64”更简洁。
细心的读者会注意到,ISA 兼容性仅对编译代码很重要,编译代码必须转换为机器代码才能运行。 Python 是一种解释型语言,因此用纯 Python 编写的软件无需在 Intel 和 ARM Mac 之间进行更改。 但是,Python 解释器本身是一个编译程序,并且许多 Python 数据科学库(如 NumPy、pandas、Tensorflow、PyTorch 等)也包含编译代码。 所有这些软件包都需要在 macOS 上为 ARM64 CPU 重新编译,才能在新推出的基于 M1 的 Mac 上本地运行。
但是,Apple 也为此提供了一个解决方案。 Apple 从其 PowerPC 模拟器中回收了“Rosetta”名称,在 macOS 11 中包含了一个名为 Rosetta2 的系统组件。 Rosetta2 允许 x86-64 应用程序和库在 ARM64 Mac 上不变地运行。 关于 Rosetta2 的一个有趣的事实是,它是一个 x86-64 到 ARM64 的转换器,而不是模拟器。 当您第一次运行 x86-64 程序(或加载编译库)时,Rosetta2 会分析机器代码并创建等效的 ARM64 机器代码。 这会在您第一次启动 x86-64 应用程序时造成轻微的前期延迟,但转换后的机器代码也会缓存到磁盘,因此后续运行应该会更快启动。 这与模拟器(如 QEMU)形成对比,模拟器在软件中逐条指令地模拟 CPU 的行为和状态。 模拟通常比运行翻译后的二进制文件慢得多,但从一个 ISA 翻译到另一个 ISA 并使代码仍然正确有效地运行可能很困难,尤其是在处理多线程和内存一致性时。
Apple 没有透露他们究竟是如何从 x86-64 二进制文件生成具有良好性能的 ARM64 机器代码的,但有 理论 认为他们设计的 M1 具有额外的硬件功能,使其能够在运行翻译后的代码时模仿 x86-64 芯片的某些行为。 最终结果是,与原生 ARM64 相比,大多数人在使用 Rosetta2 运行 x86-64 程序时会看到 20-30% 的性能损失。 在 ARM64 编译软件的选择赶上之前,这对于兼容性来说是一个相当合理的权衡。
但是,这里有一个问题,特别是对于 Python 中数值计算软件包的用户而言。 x86-64 ISA 不是一个冻结的规范,而是 Intel 随着时间的推移进行了大量改进的规范,为不同的工作负载添加了新的专用指令。 特别是,在过去 10 年中,Intel 和 AMD 推出了对“向量指令”的支持,该指令同时对多个数据片段进行操作。 具体而言,对 x86-64 指令集的这些添加是 AVX、AVX2 和 AVX-512(其本身具有不同的变体)。 您可能会想象,当处理数组数据时,这些指令可能很方便,并且一些库在为 x86-64 编译二进制文件时采用了它们。 问题在于 Rosetta2 不支持任何 AVX 系列指令,如果您的二进制文件尝试使用它们,则会产生非法指令错误。 由于存在具有不同 AVX 功能的不同 Intel CPU,许多程序已经可以在 AVX、AVX2、AVX-512 和非 AVX 代码路径之间动态选择,在运行时检测 CPU 功能。 这些程序在 Rosetta2 下可以正常工作,因为报告给在 Rosetta2 下运行的进程的 CPU 功能不包括 AVX。 但是,假设应用程序或库不具备在运行时选择非 AVX 代码路径的能力。 在这种情况下,如果软件包开发者在编译库时假设 CPU 将具有 AVX 支持,则它在 Rosetta2 下将无法工作。 例如,TensorFlow wheels 在 M1 上的 Rosetta2 下无法工作。 此外,即使程序在 Rosetta2 下工作,没有像 AVX 这样的东西也会使 M1 在执行某些类型的数组处理时速度变慢。 (同样,与在 Intel CPU 上使用 AVX 的程序相比。 由于各种原因,只有一些 Python 库使用 AVX,因此您可能会也可能不会注意到很大的差异,具体取决于您的用例。)
目前有三种在 M1 上运行 Python 的选项
使用 pyenv 创建环境,并使用 pip 安装原生 macOS ARM64 wheels 或从源代码构建软件包。
使用 x86-64 Python 发行版,如 Anaconda 或 conda-forge,搭配 Rosetta2。
使用实验性的 conda-forge macOS ARM64 发行版。
第一个选项目前具有挑战性,因为很少有 Python 项目上传了 macOS 的原生 ARM64 wheels。 许多 Python 项目使用免费的持续集成服务(如 Azure Pipelines 或 Github Actions)来构建二进制 wheels,而这些服务目前还没有可用的 M1 Mac。 如果您尝试使用 pip 安装没有 wheel 的软件包,pip 将尝试从头开始构建软件包,这可能会也可能不会成功,具体取决于您是否拥有适当的编译器和其他外部依赖项。
第二个选项提供了最广泛的软件包范围,尽管不是最快的选项。 您可以下载适用于 Anaconda(或 conda-forge)的 macOS x86-64 安装程序,并将其安装在 M1 Mac 上,一切都将正常工作。 您会看到安装程序发出警告,提示“架构似乎不是 64 位”,但您可以安全地忽略该警告。 运行 Python 应用程序时,您可能会注意到在第一次启动 Python 或导入软件包时会暂停(有时很长!),因为 Rosetta2 会将机器代码从 x86-64 转换为 ARM64。 但是,该暂停将在后续运行中消失。 主要限制是需要 AVX 的软件包将无法运行。 例如,pip 安装的 TensorFlow 2.4 wheel 将会失败(由于其构建方式),但是,来自 conda-forge 的 TensorFlow 2.4 软件包将可以工作。 您可以使用以下命令将其安装到您的 conda 环境中
conda install conda-forge::tensorflow第三个选项是使用为 macOS ARM64 构建的实验性 conda-forge 发行版。 conda-forge 团队使用一种称为“交叉编译”的技术,使用其现有的 macOS x86-64 持续集成基础设施来构建 macOS ARM64 二进制文件。 对于无法访问 M1 Mac 硬件来说,这是一个很好的变通方法,但缺点是构建系统无法测试软件包,因为没有 M1 CPU 可以运行。 尽管如此,我们测试过的软件包似乎工作正常。 如果您想试用适用于 osx-arm64 的 Miniforge
转到 Miniforge 下载页面 并下载 OSX ARM64 安装程序。
按照 安装说明 进行操作
许多流行的 OSX ARM64 软件包都可以从 conda-forge 获得,包括 PyTorch、TensorFlow(目前仅适用于 Python 3.8)、Scikit-learn 和 pandas。
我们正在添加 macOS ARM64 作为 Anaconda 支持的平台。 这些软件包将在 M1 Mac 上构建和测试。 这些软件包目前还不可用,但请保持关注!
虽然有时被称为 8 核 CPU,但 M1 最好描述为 4+4 核 CPU。 有 4 个“高性能核心”(有时在 Apple 文档中称为“P 核心”)和 4 个“高效率核心”(有时称为“E 核心”)。 P 核心提供 CPU 的大部分处理吞吐量,并消耗大部分功率。 E 核心的设计与 P 核心不同,它以最大性能换取更低的功耗。 虽然桌面和笔记本电脑芯片具有两个不同的核心是不寻常的,但这在移动 CPU 中很常见。 后台进程和低优先级计算任务可以在 E 核心上执行,从而节省电量并延长电池续航时间。 Apple 提供了 用于设置线程和任务“服务质量”的 API,这会影响操作系统是否将它们分配给 P 核心或 E 核心。
但是,Python 没有使用任何这些特殊的 API,那么在您的应用程序中使用多个线程或进程时会发生什么情况? Python 报告 CPU 核心数为 8,因此如果您启动 8 个工作进程,其中一半将在较慢的 E 核心上运行。 如果您运行少于 8 个,操作系统似乎更喜欢在 P 核心上运行它们。 为了帮助量化这一点,我们创建了一个简单的微基准测试,我们在其中创建了一个大量计算余弦的函数
import math
def waste_time(_):
n = 1000000
for i in range(n):
math.cos(0.25)然后在 multiprocessing.Pool 中使用不同数量的进程运行其多个副本,计算吞吐量。 结果如图所示
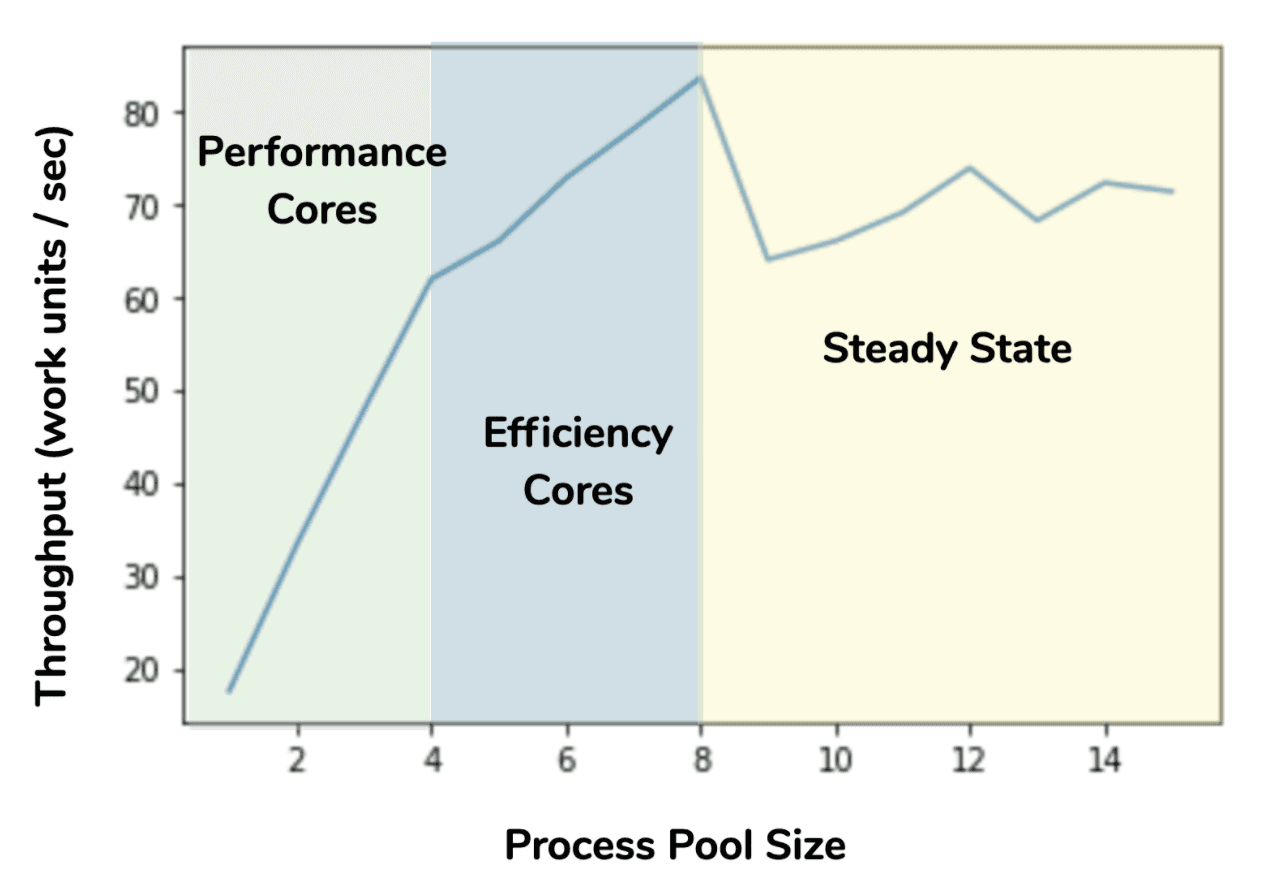
该行为与操作系统调度程序在进程数少于或等于 4 个时将工作进程分配给性能核心的情况一致。 随着进程池增长超过 4 个,每个核心的吞吐量增加减少,直到我们达到 8 个进程,这表明较慢的 E 核心被用于额外的进程。 最后,过去 8 个进程没有额外的 CPU 资源可供利用,现在调度效果和内存争用导致吞吐量变化但没有改善。 此外,有趣的是,对于 M1 的峰值总吞吐量(在此测试中),75% 的吞吐量由 P 核心提供,25% 由 E 核心提供。 这是 E 核心的不可忽视的贡献,因此如果可以,并且您的工作分配系统可以处理工人之间可能花费非常不同时间的任务,那么使用它们是一个好主意。 (也就是说,工作必须动态调度,或者必须支持工作窃取。) 在 Intel Mac 上运行类似的扩展测试表明,M1 上 E 核心的性能提升与 Intel CPU 上超线程的性能提升大致相当。 但是,这两个功能完全不同。
虽然 Apple 曾表示他们不会阻止用户在 M1 硬件上运行其他操作系统,但目前没有 Boot Camp 等效项用于将 M1 Mac 双启动到 Linux 或 Windows,并且将 Linux 移植到在 M1 硬件上本地运行的工作仍处于高度实验阶段。 但是,(在撰写本文时)有两种在 M1 上运行 Linux 的方法
在这两种情况下,您都需要运行为 ARM64 编译的 Linux 发行版,但这些发行版很容易获得,因为 Linux 长期以来一直用于 ARM 系统。 我们发现 M1 上的 Docker 非常简单直接,M1 Mac mini 是持续集成系统的绝佳选择,这些系统需要测试 Linux ARM64 软件,而不是使用 Raspberry Pi 和 NVIDIA Jetson 等低功耗单板计算机。 例如,Numba 广泛的单元测试套件在 M1 Mac mini 上的 Docker 中运行速度比在运行 Ubuntu Linux 的 Raspberry Pi 4 快约 7 倍。 (请注意,我们尚未找到在 M1 上运行 32 位 ARM Linux 发行版的方法。)
Parallels Desktop 现在也可以运行 ARM64 版本的 Windows,但 ARM 版 Windows 软件不如 Linux 软件普遍。 Windows 本身仅通过 Windows 预览体验计划提供 ARM 版,并且数据科学家可能使用的几乎所有软件都可以在 Linux 上使用。
M1 对数据科学家的最大好处基本上与对典型用户的好处相同
高单线程性能
出色的电池续航时间(对于笔记本电脑而言)
M1 Mac 没有提供任何专门惠及数据科学家的东西,但这可能即将到来(请参阅下一节)。
但是,M1 目前的目标是 Apple 产品线中功耗最低的设备,这给它带来了一些缺点
只有四个高性能 CPU 核心:许多数据科学库(如 TensorFlow、PyTorch 和 Dask)受益于更多 CPU 核心,因此只有四个是一个缺点。
最大 16 GB 的 RAM:更多内存始终有助于处理更大的数据集,而 16 GB 可能不足以满足某些用例。
Python 数据科学生态系统中对 GPU 和 ANE 的支持最少:M1 上所有不同计算单元和内存系统之间的紧密集成可能非常有利。 但是,在这一点上,唯一可以使用 M1 GPU 或 ANE 的非 alpha Python 库是 coremltools,它仅加速模型推理。
ARM64 软件包可用性:PyData 生态系统需要时间才能赶上来,并持续为 ARM64 Mac 运送 Python wheels,并且可能会存在差距。 在 Rosetta2 下运行可能是更好的选择,只要您可以避免需要 AVX 并且根本无法运行的软件包。
与现有的 Intel Mac 相比,CPU 核心数和 RAM 限制非常显着,尽管 M1 在其拥有的资源方面非常高效。
M1 的许多当前缺点仅仅是因为它是新的基于 ARM64 的 Mac 产品线中的第一个 CPU。 为了将更高性能的 Mac(尤其是 Mac Pro)转换为这种新架构,Apple 将需要发布具有更多 CPU 核心和更多内存的系统。 与此同时,Python 开发者生态系统将赶上来,并且将提供更多原生 ARM64 wheels 和 conda 软件包。
但最令人兴奋的发展将是机器学习库可以开始利用 Apple Silicon 上的新 GPU 和 Apple 神经网络引擎核心。 Apple 提供了 Metal 和 ML Compute 等 API,它们可以加速机器学习任务,但它们在 Python 生态系统中尚未广泛使用。 Apple 有一个使用 ML Compute 的 TensorFlow alpha 端口,并且可能在未来几年内,其他项目也能够利用 Apple 硬件加速。
除了 Apple 之外,M1 还展示了桌面级 ARM 处理器可以做什么,因此希望我们能看到来自该市场中其他 ARM CPU 制造商的竞争。 例如,来自另一家制造商的 M1 级 ARM CPU 运行 Linux 并配备 NVIDIA GPU 也可能是一个令人印象深刻的移动数据科学工作站。
M1 Mac 是一个令人兴奋的机会,可以了解笔记本电脑/桌面级 ARM64 CPU 可以实现什么。 对于一般用途,性能非常出色,但这些系统目前并非针对数据科学和科学计算用户。 如果您出于其他原因想要 M1,并打算进行一些轻量级的数据科学,它们是完全足够的。 对于更 интенсивное 的使用,您现在需要坚持使用 Intel Mac,但请密切关注软件开发(随着兼容性的提高)和未来的 ARM64 Mac 硬件,这可能会消除我们今天看到的一些限制。
与我们的专家之一交谈,为您的 AI 之旅找到解决方案。

