新闻
2020 年 8 月 19 日
Anaconda Team Edition 6.1.3:更轻松的管理和精选的 CVE


在过去的几周里,我们对 Pangeo 的云部署进行了一些令人兴奋的更改。这些更改将使使用者更容易使用 Pangeo 的集群,同时使部署对于管理员来说更安全且更易于维护。
一直追溯到最初的原型,Pangeo 的云部署结合了类似 Jupyterlab 的用户界面和可扩展的计算。直到最近,Pangeo 还在 Kubernetes 集群上使用 Dask Kubernetes 来启动 Dask 集群。这在过去几年中运行良好,但存在一些缺点。
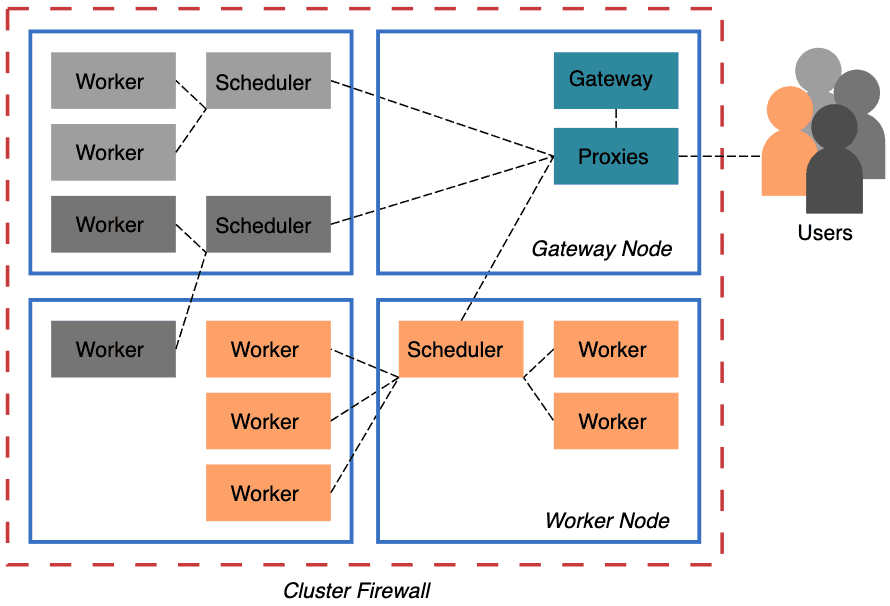
为了解决这些问题,我们在 Pangeo 的 Helm Chart 中包含了 Dask Gateway,这是一个安全的多租户服务器,用于管理 Dask 集群。Pangeo 的 Binders 和 Jupyterhubs 现在已启用 Dask Gateway,这使使用者和集群管理员(他们通常只是戴着不同帽子的使用者)都受益。
以前,希望自定义其 Dask 集群的使用者通常需要直接与 Kubernetes API 交互,而 Kubernetes API 非常庞大。例如,假设我们有一个相对内存密集型的工作负载:我们正在加载大量数据,但仅进行一些非常简单的转换。因此,我们希望调整 CPU 核心与内存的比率,以获得更多内存。Pangeo 管理员在配置文件中提供了一些默认值。
# file: dask_config.yaml
kubernetes:
worker-template:
spec:
containers:
- args:
- dask-worker
- --nthreads
- '2'
- --memory-limit
- "7GB"
resources:
limits:
cpu: 2
memory: "7G"
requests:
cpu: 1
memory: "7G"资源 dask_config.yaml 示例
创建 dask_kubernetes.KubeCluster 时,会自动使用这些值。对于我们的“高内存”工作负载,我们需要调整几个地方才能获得所需的 CPU 核心与内存的比率。
containers = [
{
"args": [
"dask-worker", "--nthreads", "1",
"--memory-limit", "14GB",
],
"resources": {
"limits": {"cpu": 1, "memory": "14G"},
"requests": {"cpu": 1, "memory": "14G"},
},
}
]
dask.config.set(**{"kubernetes.worker-template.spec.containers": containers})对于“给我更少的内核和更多的内存”这个相对简单的请求,这需要大量的专业知识。
将此与 Dask Gateway 解决相同问题的方法进行比较。集群管理员可以 向使用者公开选项。使用者可以使用图形化小部件或通过代码从这些选项中进行选择。
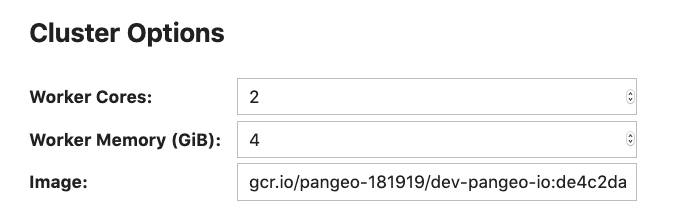
这构建在整个 Jupyter 生态系统中使用的相同技术之上,因此 ipywidgets 等库的使用者会发现该界面很熟悉。
Dask-Kubernetes 需要 Kubernetes Pod 上 更广泛的权限,这对于某些组来说可能存在问题。使用 Dask Gateway,只有管理员部署的服务需要直接与 Kubernetes 集群交互。使用者是完全隔离的。
Pangeo 管理员现在可以更好地控制集群的使用方式。我们可以设置服务器端限制,例如集群的最大大小以及每个使用者的并发集群数量。以前,使用者可以创建巨大的 Dask 集群,这些集群会淹没我们的 Kubernetes 集群,从而降低其他任何使用该集群的人的体验,并导致 Pangeo 损失资金。
现在 Dask Gateway 在所有 Pangeo 云部署上默认可用,我们正在帮助熟悉 Dask-Kubernetes 的使用者过渡到 Dask Gateway。幸运的是,两者之间的过渡非常简单。
Dask-Kubernetes 集群的典型用法
from dask.distributed import Client
from dask_kubernetes import KubeCluster
cluster = KubeCluster() # create cluster
cluster.scale(...) # scale cluster
client = Client(cluster) # connect Client to Cluster现在,使用 Dask Gateway 创建 Dask 客户端
from dask.distributed import Client
from dask_gateway import Gateway
gateway = Gateway() # connect to Gateway
cluster = gateway.new_cluster() # create cluster
cluster.scale(...) # scale cluster
client = Client(cluster) # connect Client to ClusterDask Gateway 提供了一些关于如何使用其 API 的优秀文档,但我们仍然会解开一些差异
gateway = Gateway():连接到 Dask Gateway 部署。此网关将管理 Dask 集群并充当 Kubernetes API 的访问代理。cluster = gateway.new_cluster():我们没有实例化 KubeCluster,而是要求 Gateway 为我们创建一个新集群。这将返回一个对象,该对象与其他 Dask Cluster 对象非常相似。cluster.scale():此处没有变化。使用 .scale() 或 .adapt() 向上和向下扩展集群。请注意,Dask Gateway 可能会对每个使用者或每个集群的 CPU 或内存使用量强制执行限制。client = Client(cluster):同样,此处没有变化。将客户端附加到集群可确保该集群用于所有未来的计算。就是这样!主要的变化是我们正在与 Gateway 交互,而不是直接与 Kubernetes 集群交互。其他一切,包括集群持久性和扩展,都将与以前相同。
此 binder 具有在 Pangeo binder 上使用 Dask Gateway 的可运行示例。
如果您正在使用 Pangeo 的 binder 部署之一(在 Google 上 或 在 AWS 上),您现在需要在您的环境中包含 Dask Gateway,而不是 dask-kubernetes。有关更多信息,请参阅 pangeo-binder 文档。
总结
我们希望这篇关于 Dask Gateway 的温和介绍以及 Pangeo 采用它的原因对您有所帮助。有关更多详细信息,请关注此 GitHub issue 和链接的 pull request。虽然我们希望在 Pangeo 的部署上继续支持 Dask-Kubernetes 一段时间,但我们最终将关闭此集成。
与我们的一位专家交流,为您的 AI 之旅寻找解决方案。

