Excel 中的 Python
2023 年 8 月 22 日
Excel 分析师的 Python:基础知识


这是系列博客文章中的第四篇,教您如何使用 Python 代码处理数据表。这篇文章的主题是数据分析中最关键的操作之一:清洗和整理您的数据。
如果您不熟悉,这里有一个 来自维基百科的定义
“数据整理,有时也称为数据清洗,是将数据从一种 ‘原始’ 数据形式转换和映射到另一种形式的过程,目的是使其更适合和更有价值,以便用于各种下游目的,例如分析。”
作为一名 Excel 分析师,您无疑已经多次整理过数据。数据整理是您获得最具影响力的数据分析的原材料的方式。
使用 Python pandas 库清洗和整理您的数据为您提供两大优势:
如果您不熟悉 pandas 库,请查看本博客系列第 1 部分:基础知识。
本系列中的每篇文章都附带一个 Microsoft Excel 工作簿,供您下载并用于培养您的技能。这篇文章的工作簿可在此处下载。
为了方便起见,这里提供了本系列中所有博客文章的链接
注意:要重现本文中的示例,安装 Excel 中的 Python 试用版。如果您喜欢这个博客系列,请查看我的 Anaconda 认证课程, Excel 中的 Python 数据分析。
最常见的数据整理形式之一是添加从一个或多个现有表格列中的数据创建的新列。这种数据整理的示例包括
添加列的目的是提高数据对特定分析技术的有用性。
例如,在机器学习中,此过程称为“特征工程”。特征工程旨在创建对构建预测模型最有用的数据表示。
InternetSales 表提供了关于销售订单财务方面的两列:TotalProductCost 和 SalesAmount。添加一个新列 (GrossProfit) 将提供在许多分析中有用的附加信息。
使用 Microsoft Excel 添加新列的过程非常简单
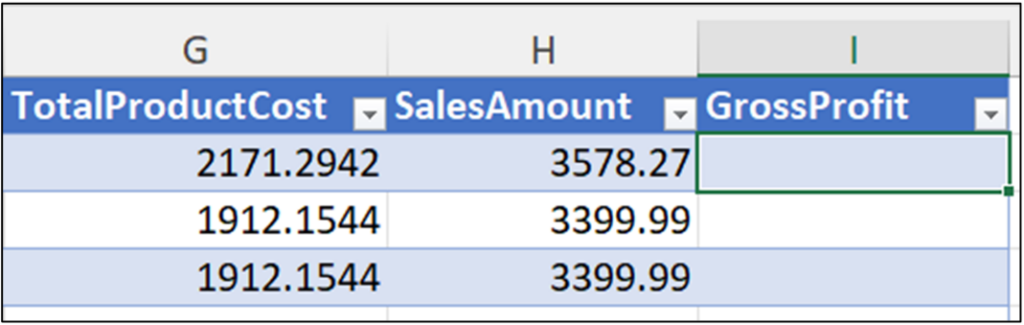
创建 GrossProfit 列后,需要用数据填充它。GrossProfit 的值应通过从表中每行的 SalesAmount 中减去 TotalProductCost 来计算。
Excel 用户填充 GrossProfit 列最常见的方式是使用单元格引用公式
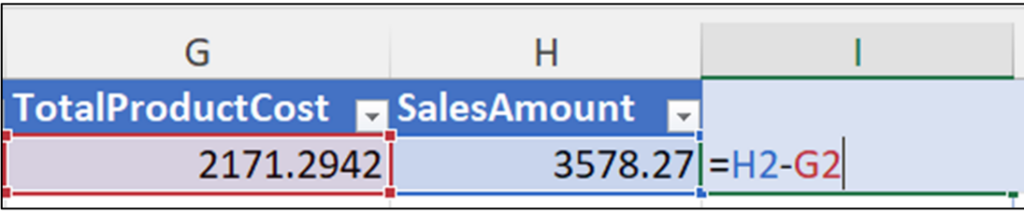
Microsoft Excel 还支持使用结构化引用。例如,可以使用基于 TotalProductCost 和 SalesAmount 列的结构化引用的公式来填充 GrossProfit 列

使用图 3 的公式并按下 <enter> 键会自动为 InternetSales 表的每一行填充公式
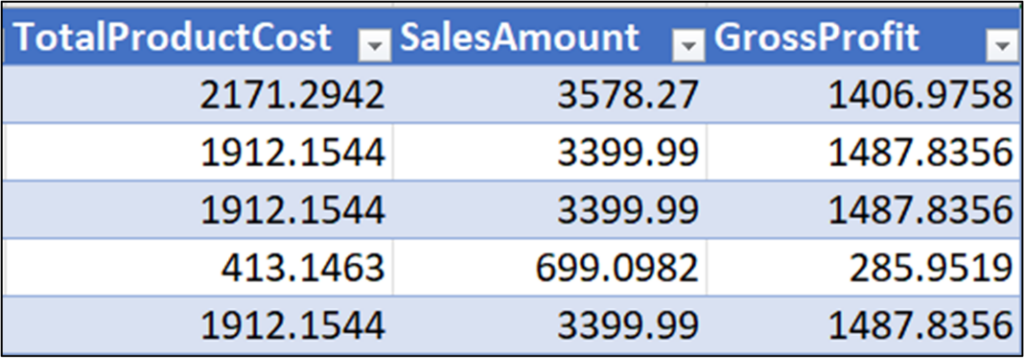
向 pandas DataFrame 添加列在概念上类似于使用 Microsoft Excel 结构化引用公式。
这是一个如何将 GrossProfit 列添加到 InternetSales 表的示例
首先,使用 PY() 函数创建您的 Python 公式
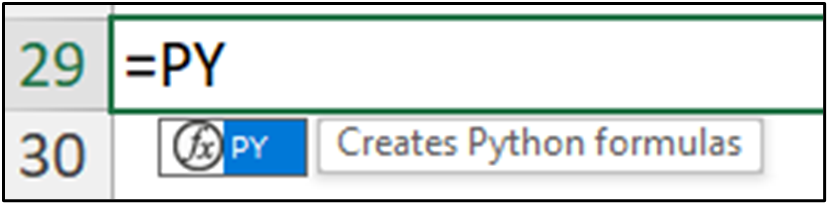
接下来,当您键入 “(“ 时,单元格将指示它包含 Python 代码

以下 Python 代码添加了 GrossProfit 列,并用 internet_sales DataFrame 每行的计算值填充

注意:图 7 中描绘的代码显示在多行上,因为单元格使用 Excel 功能区设置为自动换行。
从概念上讲,图 7 的代码的工作方式如下
在键盘上按 <Ctrl+Enter> 执行 Python 公式,在 Excel 工作表中产生以下内容

由于图 7 的 Python 代码没有返回任何内容(即,代码更改了 internet_sales DataFrame),因此图 8 中描述的 NoneType 是预期的。
运行以下 Python 代码将允许您检查更改后的 DataFrame

要查看更改后的 DataFrame,请将鼠标悬停在卡片上
单击卡片将显示 internet_sales 的内容
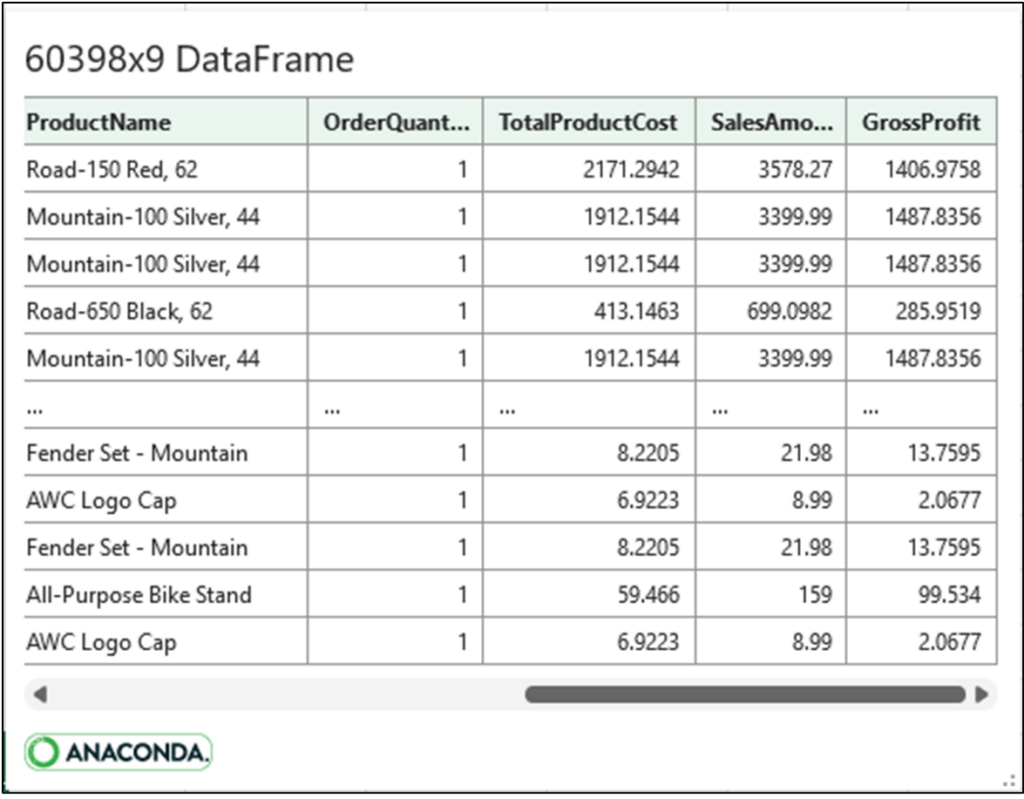
如图 11 所示,Python 代码产生与图 3 中的 Excel 结构化引用公式相同的输出。
考虑图 7 中的代码。当执行此代码时,计算会自动逐行执行。这是 pandas DataFrame 的一种称为“向量化”的行为。
作为一名 Excel 分析师,您熟悉向量化:它是 Excel 表格的默认行为。pandas DataFrame 对向量化的支持使在 Python 中处理数据表非常容易。
上一节介绍了最常见的数据整理场景之一:添加新列。本节将介绍另一个常见的数据整理场景:清洗现有列中的数据。
从概念上讲,清洗数据包括三个步骤
识别需要清洗的列的最快方法是获取 DataFrame 的摘要。
DataFrame 提供 info() 方法,为您提供 DataFrame 内容的摘要

执行图 12 的代码不会返回任何内容。相反,调用 info() 方法将触发 Excel 打开“诊断”窗格以显示 DataFrame 摘要:
info() 方法提供有用的信息,用于识别需要清洗的列。查看图 13,为您提供以下信息
您要识别的第一件事是是否存在任何缺失值。在大多数分析中,必须清洗缺失数据(例如,替换为默认值)。
在 info() 方法输出中,缺失数据表示为 null。由于每个 DataFrame 列的非空值计数与行数完全相同,因此没有数据缺失。
下一步是分析您的数值和字符串数据。
由于 internet_sales DataFrame 的数值列中没有缺失数据,您需要确定数值是否适合给定的业务流程。
如本博客系列第 2 部分 中详述,分析数值数据的最快方法是使用 pandas Series(即列)的 describe() 方法。
DataFrame 也具有您可以使用的 describe() 方法

DataFrame describe() 方法返回一个包含分析详细信息的 DataFrame。单击公式单元格中的卡片将显示分析结果
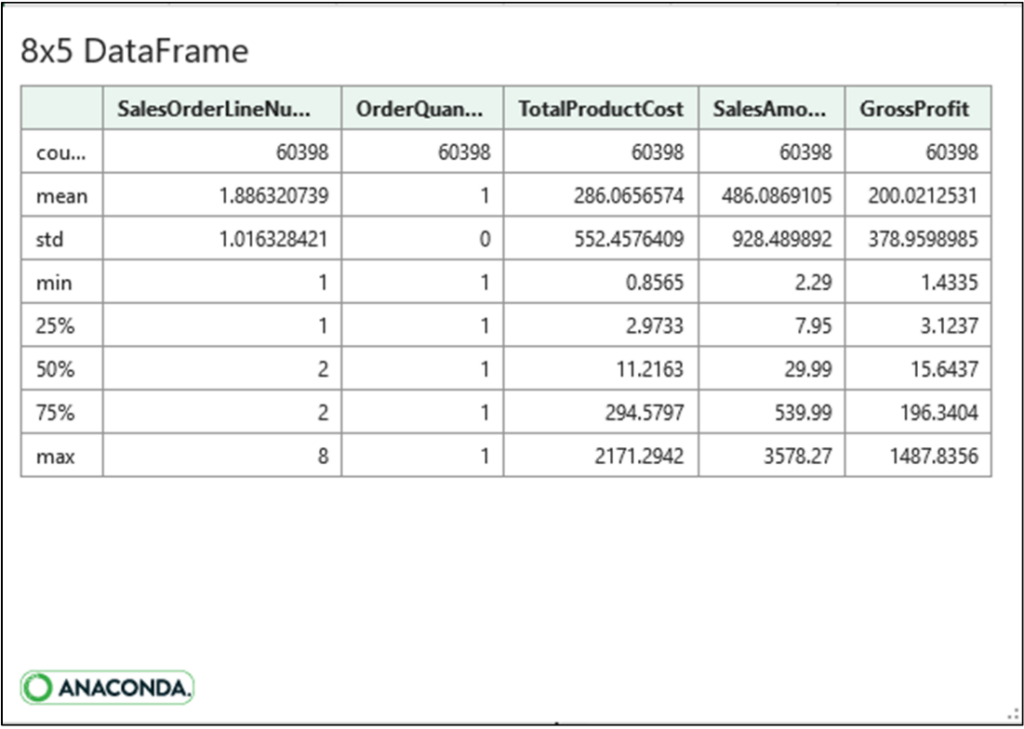
使用图 15 中描述的信息,您可以快速回答以下问题
以上问题的答案标识了可能需要数据清洗的列(例如,替换极端值或删除具有极端值的行)。
例如,OrderQuantity 列仅包含值 1。根据业务流程,这可能是预期的,也可能表明存在数据质量问题。
字符串数据列通常需要清洗——尤其是当数据由人工输入时(例如,街道地址)。
在分析字符串数据方面,pandas Series(即列)的 value_counts() 方法是您理解字符串数据值的首选方法

value_counts() 方法返回一个 Series。返回的 Series 对象包含列中包含的唯一字符串值的计数。默认情况下,计数器值按降序排列。
单击公式单元格的卡片将显示 Series 数据
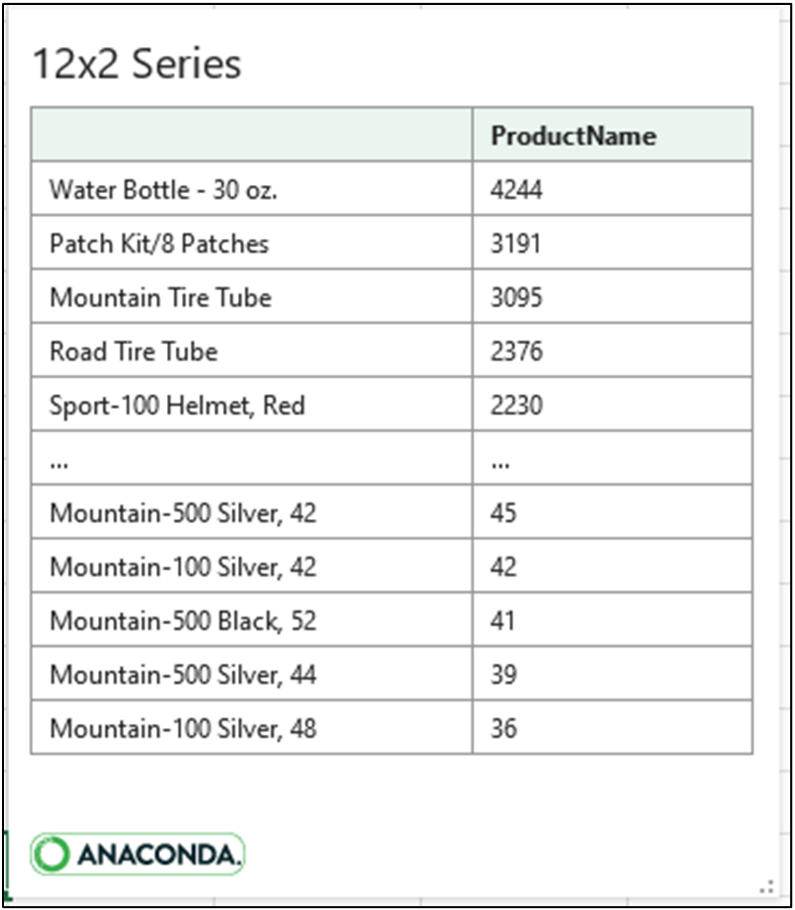
如图 17 所示,pandas DataFrame 和 Series 对象默认显示前五行和后五行。
这在这种情况下不是非常有用,因此另一种方法是告诉 Excel 将整个 Series 数据直接作为Excel 值返回到工作表
更改 Python 公式单元格输出会生成许多行数据
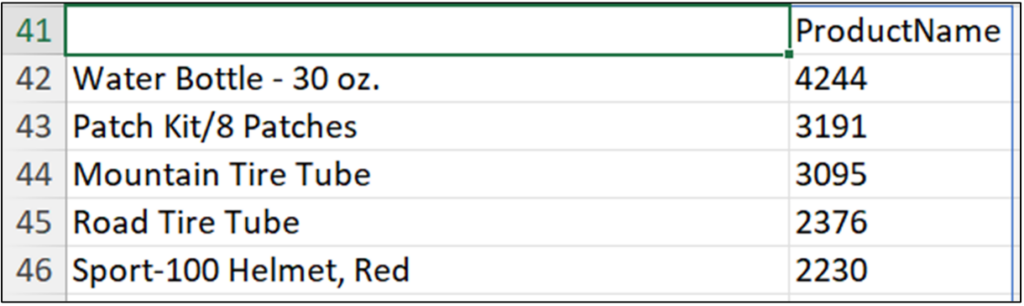
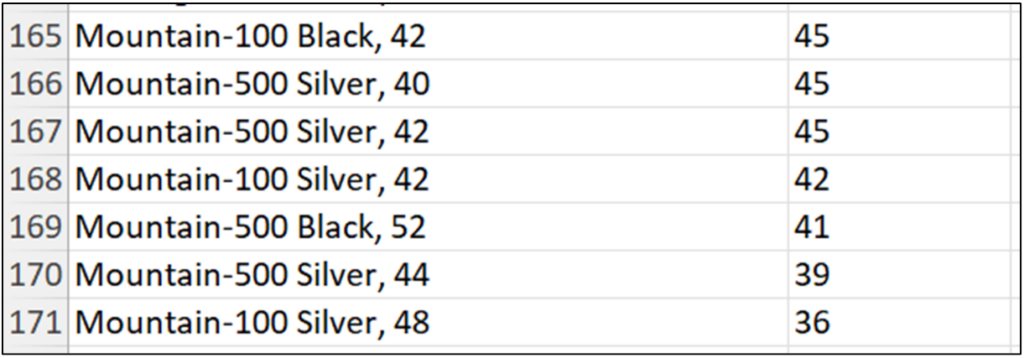
图 19 描绘了清洗字符串数据中的常见场景:使用特定的格式。例如,各种类型的自行车(例如,“Mountain-100 Black, 42”)遵循模型、颜色和尺寸的格式。
典型的数据清洗操作是转换这些字符串格式。
假设您有兴趣对自行车销售额进行分析,但自行车颜色不是一个因素。ProductName 列的当前格式包含颜色,这将使这些分析变得困难。
清理 ProductName 列以移除颜色将允许您进行必要的分析。正如本博客系列第 2 部分所演示的那样,实现此目标的最简单方法是在 ProductName 字符串列上使用 replace() 方法。

注意:图 20 中描述的代码显示在多行上,因为单元格设置为使用 Excel 功能区的自动换行。
查看数据清理结果的最简单方法是再次使用 value_counts() 方法,并将 Series 对象输出作为 Excel Value 返回到工作表。


图 22 描述了如何使用清理后的 ProductName 数据来分析自行车销售,而无需考虑自行车颜色。
pandas Series 数据类型提供了用于处理字符串数据的广泛库。请查看在线文档以获取更多信息。
注意:此帖子中使用的数据清理示例很常见,但肯定不是唯一的数据清理方法。有关数据清理的更多资源,请查看以下 Anaconda 课程:Pandas 数据分析入门 和 Pandas 数据清理。
这篇博客文章是对使用 pandas 进行数据整理的简要介绍。
pandas 库为数据清理和整理提供了大量功能。这包括您过去在 Microsoft Excel 中使用的所有功能,以及更多功能。
在 Python 数据分析代码中,大部分通常都集中在获取、清理和整理数据上。培养 Python 数据整理技能将对您大有裨益。
本系列的最后一篇文章将向您介绍在制作最佳数据分析时的另一项基本操作:连接数据表(类似于 VLOOKUP)。在这方面,使用 Python 连接数据表为您提供三个显著优势:
如果您想了解更多关于使用 pandas 处理数据表的信息,请参加 Pandas 数据分析入门 初学者课程,并查看官方 pandas 用户指南。
免责声明:截至本文发布之时,Microsoft Excel 中的 Python 集成尚处于 Beta 测试阶段。功能和函数可能会发生变化。如果您发现此页面上有错误,请随时联系我们。
Dave Langer 创立了 Dave on Data,他在那里提供旨在帮助任何专业人士发展数据分析技能的培训。多年来,Dave 已经培训了数千名专业人士。此前,Dave 在 Schedulicity、Data Science Dojo 和 Microsoft 提供了推动业务战略的见解。
与我们的专家之一交流,为您的 AI 之旅寻找解决方案。

