Excel 中的 Python
2023 年 8 月 22 日
面向 Excel 分析师的 Python:基础知识

这是关于教您如何使用 Python 代码处理数据表的系列博客文章中的第二篇。 这篇文章向您介绍如何处理 pandas DataFrame 对象的列。
如果您不熟悉 pandas 库,请查看本博客系列的第 1 部分(基础知识)。
本系列中的每篇文章都附带一个 Microsoft Excel 工作簿,供您下载并用于培养技能。 这篇文章的工作簿可在此处下载。
为方便起见,以下是本系列所有博客文章的链接
注意:要重现这篇文章中的示例,请安装 Excel 中的 Python 试用版。如果您喜欢本博客系列,请查看我的 Anaconda 认证课程,使用 Excel 中的 Python 进行数据分析。
本系列的上篇博客文章概述了如何使用 pandas 库在 Python 中表示数据表。 您还了解了您的 Microsoft Excel 知识如何映射到 Python 代码。
将您的 Excel 知识映射到 Python 将是贯穿本系列文章的 recurring theme。 正如您在 Excel 中将函数与数据列一起使用一样,在编写 Python 代码时,您也会这样做。
例如,在 Excel 中,通常将函数应用于列以清理数据或计算某些值(例如,平均值)。 当您进入更高级的数据分析场景(例如,聚类分析)时,您将使用 Python 代码执行相同的操作。
您有多种选项可以访问 pandas DataFrame 对象的列。 这篇博客文章将重点介绍最灵活的选项之一,而以后的博客文章将介绍其他方法。
考虑一下您将如何编写 Excel 代码来访问 InternetSales 表的 SalesAmount 列
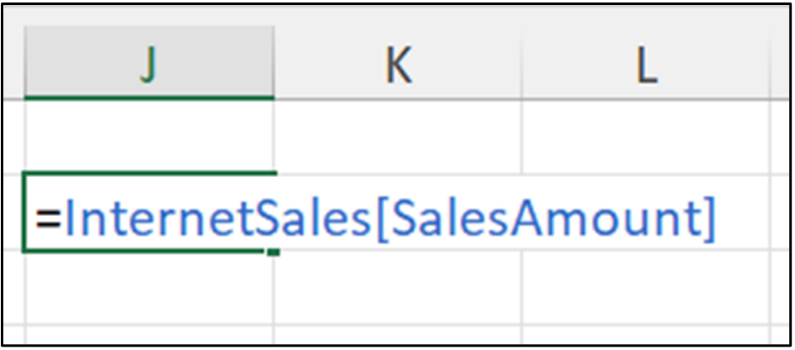
上面的 Excel 公式将 SalesAmount(列)视为 InternetSales 对象(表)的属性。DataFrame 对象的工作方式类似。
以下 Python 代码访问 internet_sales 对象(DataFrame)的 SalesAmount(pandas Series)

DataFrame 通过使用方括号提供对列的访问。 使用此选项时,您需要提供要访问的列名作为带引号的字符串。
Python 编码约定是使用单引号,但使用双引号(例如,“SalesAmount”)也是有效的。
以这种方式访问 DataFrame 列的主要好处是支持复杂的列名(例如,带有空格的名称)。
您还可以使用方括号同时访问多列。 但是,这要求您使用所谓的 Python 列表。 Python 列表是声明值集合的一种方式。
有关 Python 列表的更多信息,请查看 Anaconda 的本课程。
以下 Python 代码访问 internet_sales DataFrame 的 TotalProductCost 和 SalesAmount 列

上面的 Python 代码有一对嵌套的方括号。 内部一对括号创建包含两个值的 Python 列表
Python 列表在编写 pandas 代码时很常用。 您将在以后的博客文章中看到更多示例。 为简单起见,这篇文章将仅处理一个 DataFrame 列(即,pandas Series 对象)。
作为 Excel 分析师,您通常处理数字列。 当处理新数据集时,通常会计算数值列的摘要统计信息。 使用摘要统计信息可以深入了解数值列中值的分布。
摘要统计信息的一些示例包括
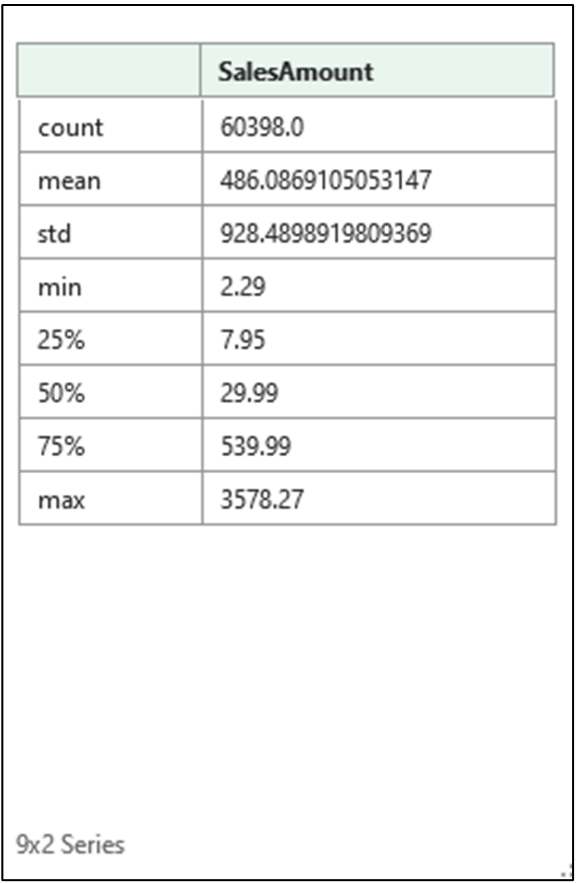
以下 Excel 代码显示了计算 InternetSales 表的 SalesAmount 列的摘要统计信息
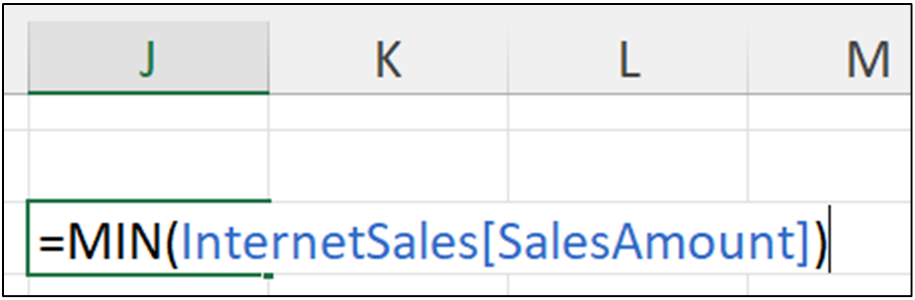
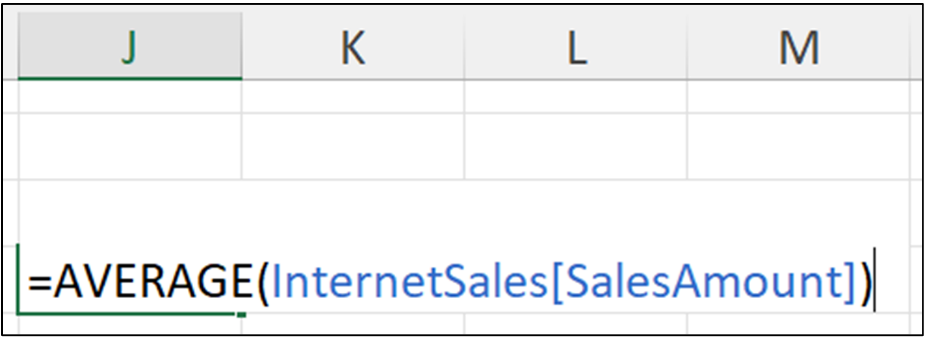
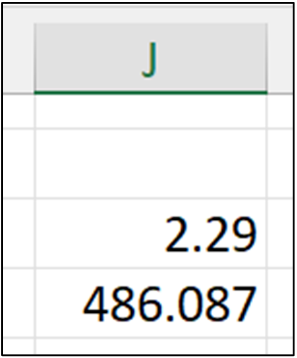
图 5 的输出告诉我们,最小 SalesAmount 为 2.29 美元,平均 SalesAmount 为 486.087 美元。 即使仅计算了两个摘要统计信息,我们也已经了解了很多关于 SalesAmount 列的信息
从概念上讲,使用 Python 中的 pandas 库计算摘要统计信息与 Microsoft Excel 相同—您请求在值集合上运行函数。 Python 函数名称通常与 Excel 中的名称相同!
这是一个使用 Python 查找 SalesAmount 列的最小值的示例。
首先,使用 PY() 函数创建您的 Python 公式
接下来,当您键入“(“ 时,单元格将指示它包含 Python 代码
您可以使用 pandas Series 对象的 min() 方法来获取列中包含的最小值

在键盘上按 <Ctrl+Enter> 运行 Python 代码并生成输出

平均值的另一个名称是 mean。 以下 Python 公式使用 pandas Series 的 mean() 方法来计算 SalesAmount 列的平均值

使用 <Ctrl+Enter> 运行上面的 Python 公式会生成以下输出

如上所示,用于计算摘要统计信息的 pandas 代码与 Excel 代码非常相似。 虽然上面的示例很简单,但重要的是您在处理 pandas Series 对象时使用的 Python 代码模式。
在以后的博客文章中,您将学习如何从现有列在 DataFrame 中创建新列,以更深入地了解数据。 此过程称为 特征工程,并建立在您在这篇文章中学到的技能之上。
pandas Series 数据类型提供了一种方便的方法来计算多个摘要统计信息 — describe() 方法。 以下代码在 SalesAmount 列上调用 describe() 方法

运行 Python 公式将生成一个新的 pandas Series 对象,其中包含计算出的摘要统计信息。 使用鼠标悬停在卡片上
单击卡片将显示 Series 对象的内容
describe() 方法返回的 Series 对象提供了有关 SalesAmount 列的大量信息,并且比编写许多 Excel 公式来调用相应的 Excel 函数更快/更轻松
还有更多方法可用于处理数值 pandas Series 对象。 有关更多信息,请参阅在线文档。
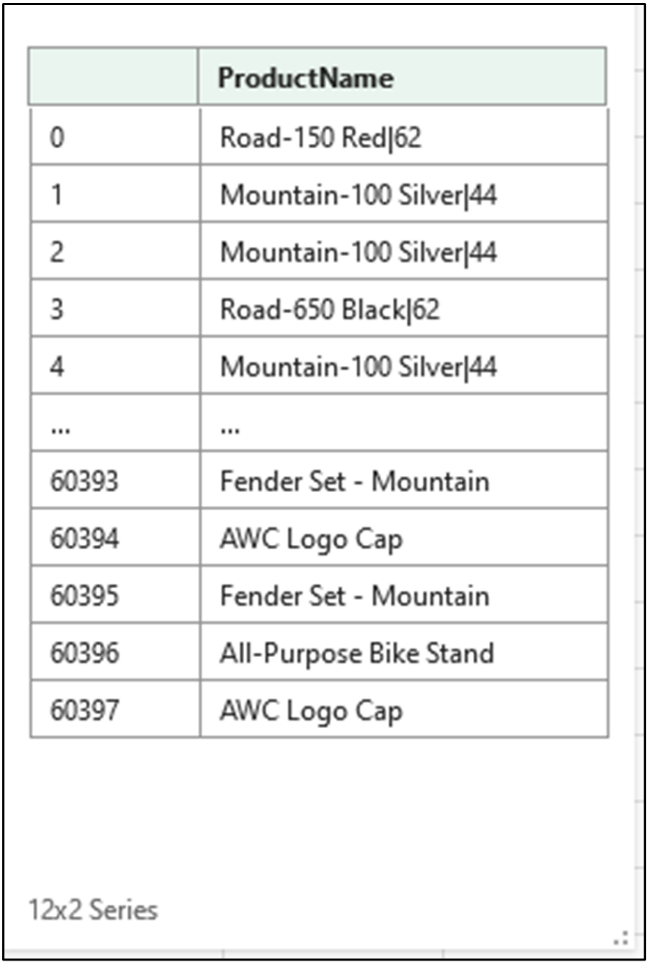
文本是业务数据的常见形式。 文本数据有多种形式 — 产品名称、地理位置、地址等。 在 Python 中,术语 string 用于指代文本数据。
清理和转换字符串数据非常常见。 很可能在您作为 Excel 分析师的工作中,您必须整理字符串数据,然后才能将其用于分析。 整理字符串数据的一些常见示例包括
以下 Excel 代码显示了处理字符串数据时的常见数据整理场景 — 删除逗号。
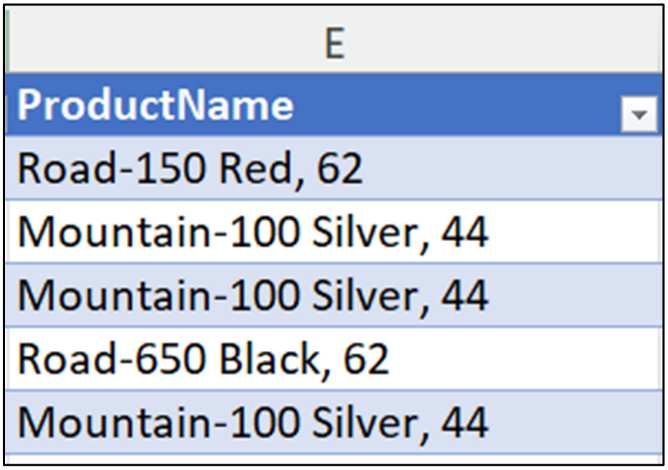
InternetSales 表的 ProductName 列是包含逗号的字符串数据
以下 Excel 代码将 ProductName 列中包含的每个逗号后跟一个空格(即“, ”)的实例替换为管道字符(即“|”)
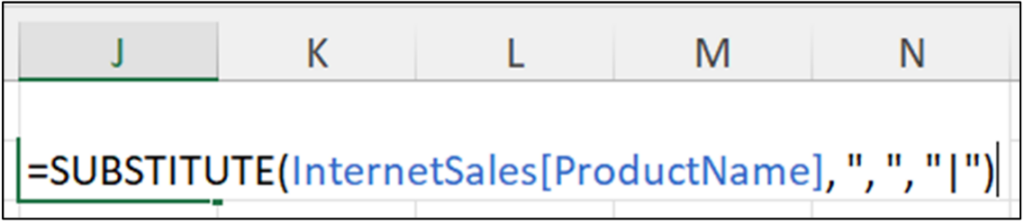
当使用逗号分隔值 (CSV) 文件共享数据时,这种类型的字符串整理很常见。
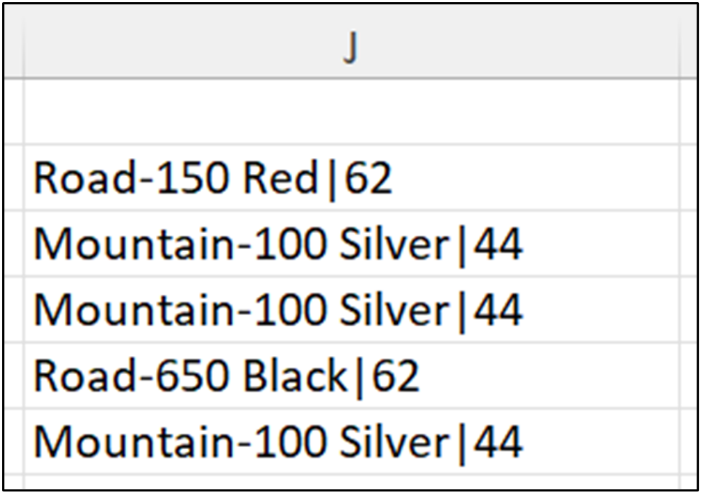
运行上面的 Excel 代码会生成以下输出
在 Excel 中执行的所有字符串整理操作都可以使用 Python 完成。 要使用 Python 进行字符串整理,您需要将您的 Excel 知识映射到适用的 pandas Series 方法。
使用 pandas Series 对象执行字符串整理时,第一步是使用 str 属性。 使用 str 属性使您可以访问执行字符串整理所需的方法

replace() 方法提供类似于 Excel 的 SUBSTITUTE() 函数的功能。 以下代码将每个“, ”实例替换为“|”

replace() 方法返回一个新的 pandas Series 对象,其中包含整理后的字符串数据。 这类似于您在运行 SUBSTITUTE() 函数后在 Excel 工作表中看到的。
上面的 Python 代码将新的 Series 对象存储在名为 prod_name_clean 的变量中。 使用命名变量允许您在以后可能编写的 Python 公式中轻松重用该对象。
您可以通过将鼠标悬停在单元格中的卡片上并单击来检查此对象的内容。 Excel 将提供 prod_name_clean Series 对象内容的预览
方便,对吧? 鉴于字符串数据在分析中有多么常见,str 属性提供了许多用于处理字符串数据的方法。 有关更多信息,请查看在线文档。
这篇博客文章简要介绍了如何处理 DataFrame 的列(即 Series 对象)。
pandas Series 数据类型为处理数据列提供了与 Microsoft Excel 相当的功能。 例如,Series 数据类型为处理日期/时间数据提供了完整的功能。
处理 pandas DataFrame 和 Series 对象是更高级的 Python 数据分析场景(如可视化、预测建模和聚类分析)的基本技能。
本系列的下一篇文章将向您介绍处理数据表的另一个基本概念:筛选。
如果您想了解有关使用 pandas 处理数据表的更多信息,请参加此入门课程,了解pandas 数据分析入门,并查看官方 pandas 用户指南。
免责声明:Microsoft Excel 中的 Python 集成在本文发布时处于 Beta 测试阶段。 功能和函数可能会发生变化。 如果您发现此页面上有错误,请随时联系我们。
Dave Langer 创立了 Dave on Data,他在那里提供为任何专业人士设计的培训,以培养数据分析技能。 多年来,Dave 培训了数千名专业人士。 之前,Dave 在 Schedulicity、Data Science Dojo 和 Microsoft 提供了推动业务策略的见解。
与我们的专家之一交谈,找到适合您 AI 之旅的解决方案。

