企业数据科学、机器学习和 AI
2023 年 1 月 26 日
企业 AI 平台十大用例


Martin Durant 是 Anaconda 的高级软件工程师。在这篇博文中,他详细介绍了 fastparquet 的背景、改进计划、依赖项和升级。继续阅读以了解 Martin 如何努力改进 fastparquet 用户体验和读取端性能。
在过去的六个月中,我投入了大量精力来现代化和改进 fastparquet,这是一款 Python parquet 读/写包,已为 PyData 社区服务五年。通过这些添加,现在可以实现多种功能,许多事情变得更快,而且最重要的是,没有任何事情变慢(至少在读取端!)。
关于我自己的背景:我的职业生涯始于天体物理学家,曾在多个学术职位工作,包括医学影像研究。之后我成为了一名数据科学家,并且一直是开源 Dask、Intake、Streamz、fsspec 和 Zarr 维护团队的成员,专门研究数据访问、远程文件系统和数据格式。我在 Anaconda 工作了六年,主要担任我们开源团队的软件工程师。
fastparquet 是第一个用于 parquet 格式大数据的读取器和写入器,它可以在 Python 中工作,而无需 Spark 或其他非 Python 工具。它提供与 pandas DataFrame 的高性能转换,并且与 Dask 良好集成。在 pyarrow 的 parquet 集成到来之前,它是唯一的向量化 parquet 引擎(另请参阅早期的 parquet-python,它与它共享一些代码)。
截至 2021 年初,fastparquet 仍然是 pandas-parquet 的主要软件包之一,根据 pypistats,每月下载量约为 100 万次。然而,它已经有一段时间没有看到任何实质性的发展。
2021 年 4 月,我创建了一个 issue,详细说明了要实现的重要改进。此列表在随后的几个月中得到了扩充,但大多数项目都在初始形式中。正如您所见,几乎所有项目都已完成(另请参阅下面的“未来”部分)。
各种任务的实施导致了一系列版本发布,在这里我们将比较 0.7.1 和 0.5.0 版本的读取性能。
cramjam 包于 2020 年出现,链接了 parquet 所需的压缩编解码器的 Rust 实现(LZO 除外,没有人使用!)。这简化了 fastparquet 的依赖项,用户不再需要为 snappy、brotli 或 zstd 寻找额外的包。此外,在某些情况下,cramjam 可能更快。
Fastparquet 最初是使用 Numba 提供的加速功能构建的。这对于编/解码 parquet 规范中各种可能的字节表示形式非常有效。不幸的是,Numba 不处理(Python)字符串,因此也存在一些 Cython 代码。
我们将所有 Numba 代码重写为 Cython。这没有带来更好的性能,但减少了所需环境的大小(没有 LLVM!),并消除了一些运行时编译。
最后,在 PR 中,我们即将消除对 thrift 的需求,使用我们自己的实现。
Conda 环境大小

我们对 fastparquet 进行了许多更改以进行改进,因此我概述了一些亮点,这些亮点使最终用户体验更好。
加载没有“_metadata”文件的目录:这始终是可能的,但需要用户首先显式获取文件列表。
读取和写入“数据页眉 2”:很久以前添加到 parquet 规范中。只有少数框架开始生成 V2 文件,但我们需要能够读取它们。碰巧的是,使用 V2 确实有性能优势。
编码类型 RLE_DICT 和 DELTA,以实现兼容性。
可空类型和纳秒分辨率时间,以更好地匹配 pandas 和 parquet 类型系统。默认情况下启用可空类型,因此可选的 int 列在读取时变为 pandas 可空 Int 列,但将转换为 float 并使用 NaN 标记 null 的旧行为仍然可用。
行过滤:仅生成您实际想要的数据的 DataFrame。这是一个两步过程,一步加载您要过滤的列,一步应用过滤器。目的不是速度,而是更低的内存占用空间(由于 parquet 是一种块状格式,您最终会读取相同数量的字节)。
大部分精力都投入到了这里,特别是读取端性能。以下是一些选定的基准测试。请记住,基准测试是有偏差的,并且使用了相同的测量技术来指导优化过程。数字是我的机器给出的。
开放数据集“split”

fsspec 在列出和获取有关本地文件的信息方面进行了一些改进。同样,当没有全局元数据可用时,将并发获取远程文件,从而减轻延迟影响。
首次读取时间

差异主要是由于 0.7.1 中没有运行时编译。导入时间大致相同,并且由 pandas 主导。
列读取时间
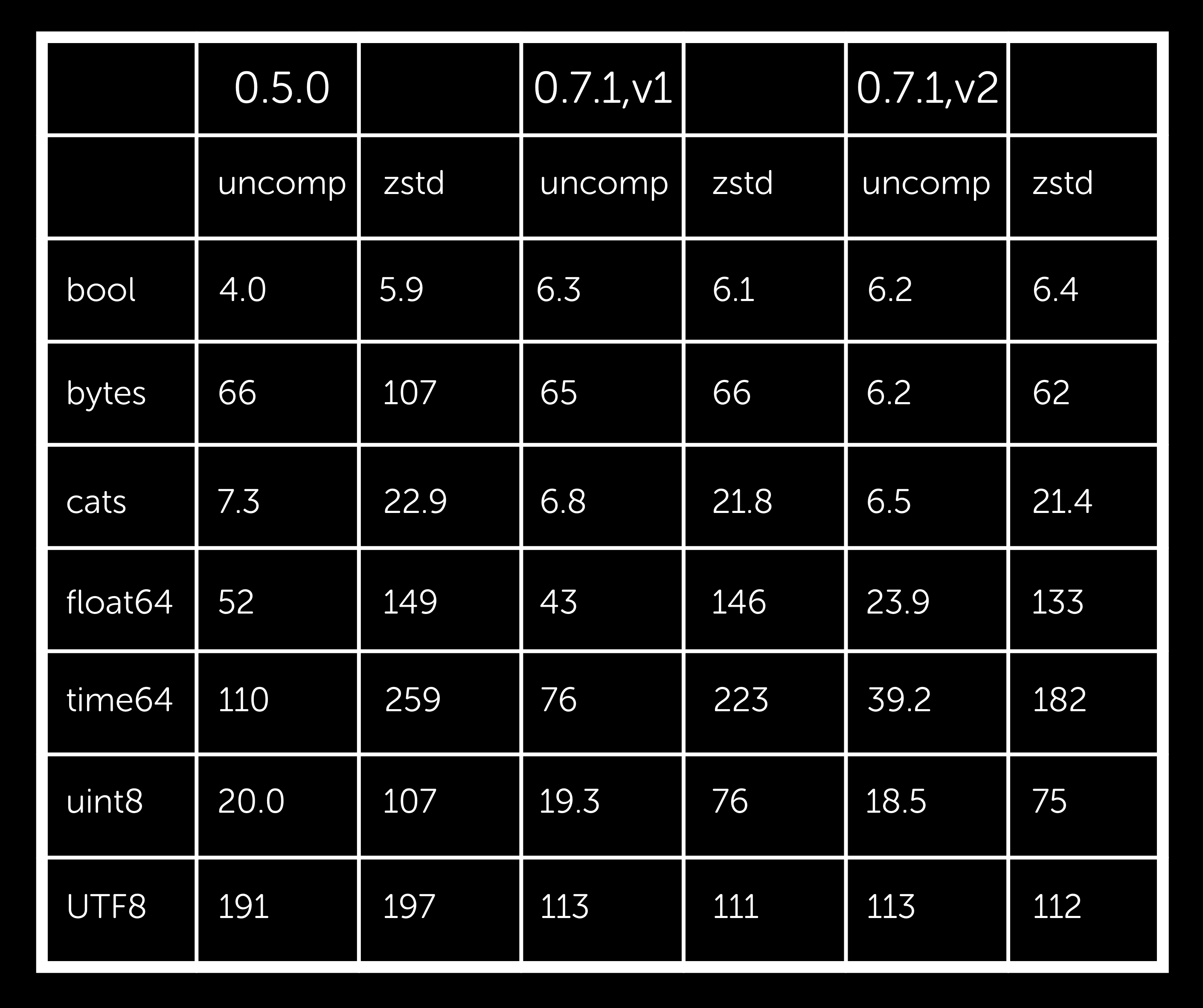
我们可以看到,0.7.1 通常更快或相同(bool 类型略有例外),并且使用 V2 页面可以显着改善 float 和 time 类型(以及未包含的 int32/64 类型)。我们还看到 zstd 压缩相同或更好,并且 V2 再次可以产生积极影响。对于 gzip(总是很慢)和 snappy(总是很快,但对于随机数据没有有效的压缩),这种差异不太明显。
未来
四月份计划中剩下的唯一主要工作是实现独立于 thrift 包的 thrift 读取/写入。PR#663 完成了这项工作,尽管仍然存在一些粗糙之处,但原始性能非常令人鼓舞
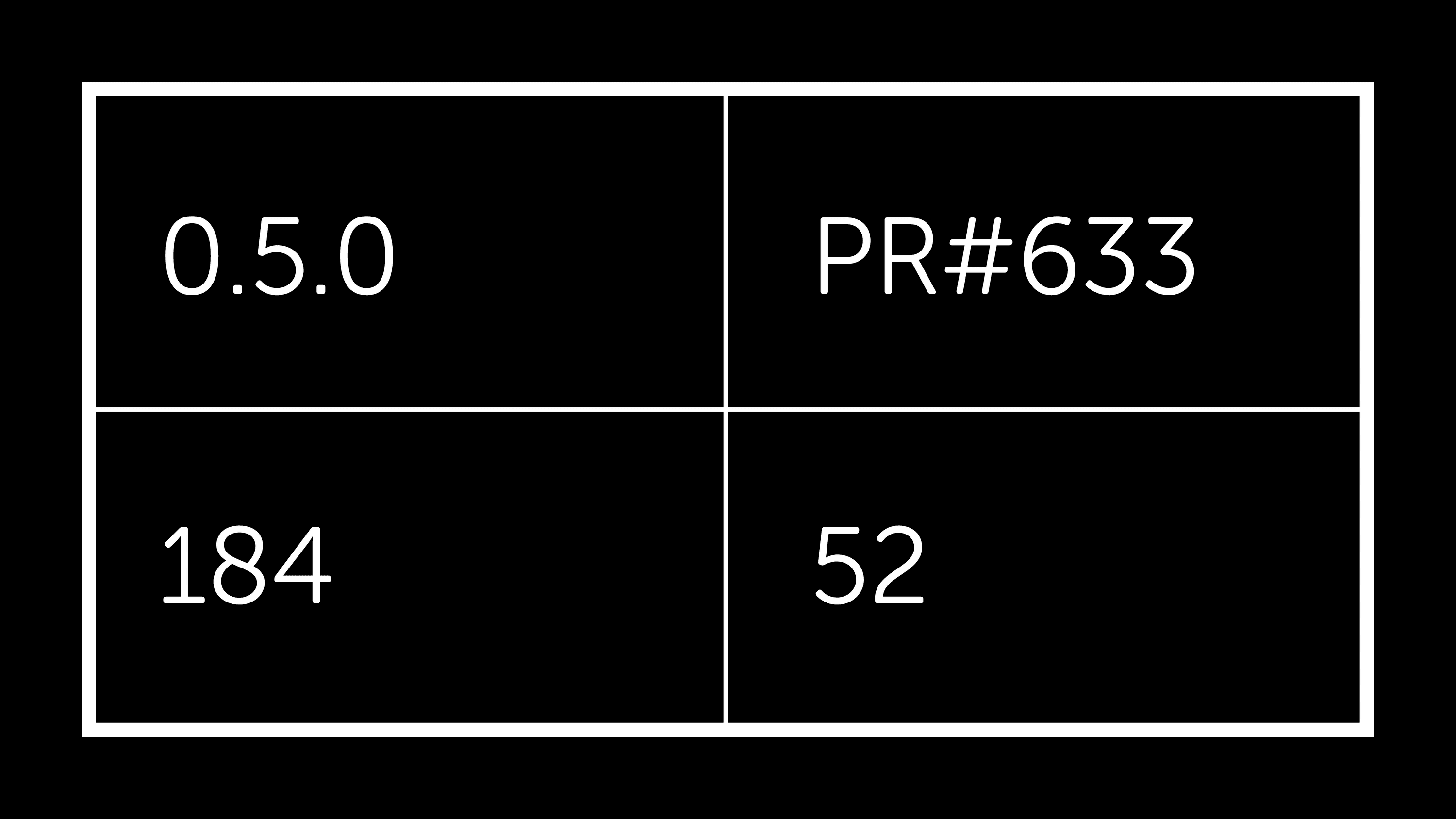
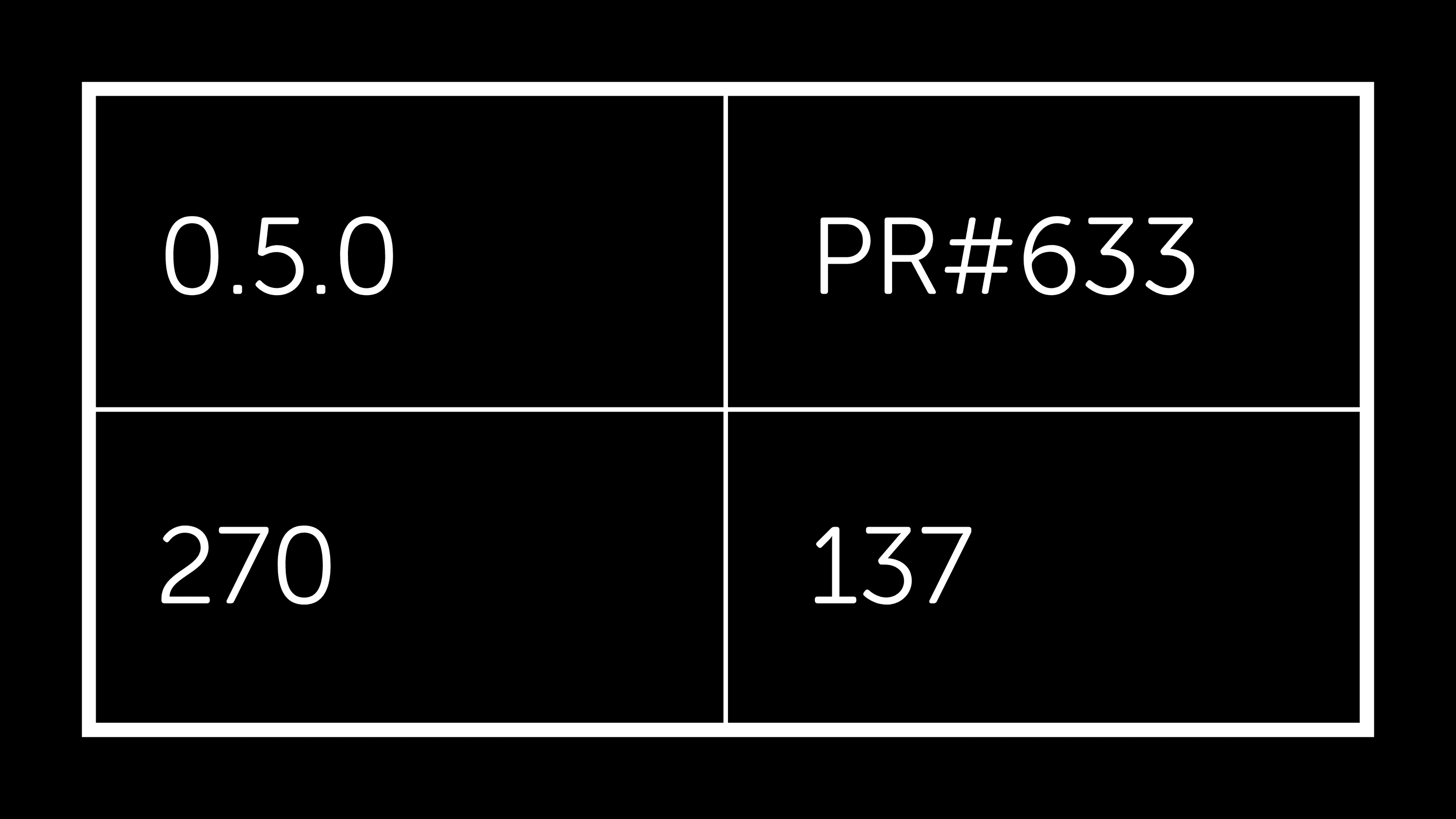
除了上面详述的内容外,其他外部更改也在后台发生。虽然有些需要修复,但另一些则提供了继续提高 fastparquet 的性能和功能的机会。我对我们今天取得的进展感到兴奋,并期待分享有关该项目持续进展的未来更新。
与我们的专家之一交谈,为您的 AI 之旅找到解决方案。

