Anaconda 文化
2022年8月16日
介绍 Anaconda 的 Safari 计划


数据可视化是数据科学家工作的重要组成部分——一图胜千言!即使我们生活在大数据和数据驱动决策的时代,但事实是,如果没有数据可视化,我们将在无休止的电子表格数字行中迷失方向。毕竟,仅在200年前,世界上只有不到 20% 的人口识字——但图像已经成为数万年来强大的沟通工具。
即使在今天这个高度识字的世界上,大多数人仍然难以理解充满数字的表格之间的关系。在今年的《数据科学现状调查》中,只有 52% 的受访者表示,他们组织的决策者大多具有数据素养。在这种背景下,数据可视化可以在传达重要概念和趋势方面发挥关键作用是合理的。即使数据可视化是一项(相对)较新的发展,历史也表明了它们对我们生活产生重大影响的潜力。也许这就是为什么今天的数据科学家表示他们花费 15% 的时间用于可视化的原因。
与此同时,数据可视化并不是传达数据科学工作成果的一劳永逸的灵丹妙药。即使对于经验丰富的从业者来说,要做好它们也很棘手。鉴于图表或图形在我们大脑中根深蒂固的有效性,如果它们不能准确或有效地表示底层数据,则可能会产生负面后果。
为了更好地理解数据可视化可能出错的地方——以及如何避免这些陷阱——将数据可视化分解为两种主要类型是有帮助的。第一种是探索性可视化:这是指数据科学家在得出任何结论或进行全面分析之前,使用可视化工具来更好地理解他们的数据。第二种是叙述性可视化:这是数据科学家用来向更广泛的受众展示或传达他们的发现的方式。每种类型都有其自身的潜在挑战。
随着大数据的出现,探索性数据可视化成为数据科学过程的关键部分。当处理成千上万、数百万或数十亿个数据点时,个人不可能仅仅通过盯着单个值或计算简单的统计数据来找到数据集中的模式和分布。因此,从业者转向数据可视化,以便处理他们的数据并探索进一步的分析途径。不幸的是,传统的可视化方法需要仔细的手动调整,以避免过度绘制、欠饱和和过饱和等问题,而当您理解数据的唯一方法是通过可视化本身时,手动调整很难安全地完成!如果您正在使用传统的可视化技术对大数据进行探索性分析,那么对于小数据来说只是令人恼火的绘图问题可能会导致您对大数据得出完全错误的结论。
为了避免这些问题,重要的是要认识到您在探索性数据可视化中使用的任何工具的局限性,并批判性地思考信息的显示方式如何影响您对其的评估。我们几年前创建 Datashader 的原因之一是为了帮助应对这一挑战。Datashader 是一个开源库,它可以自动创建任何大小数据集的准确表示,而无需手动调整透明度或点大小等参数。我们使用 Datashader 的目标是让从业者探索他们的大型数据集的真实面貌,包括缺陷(好吧,异常值!)和所有,而无需一开始就知道他们在寻找什么。
无论您使用 Datashader 还是其他工具,避免探索性数据可视化问题的关键是确保您不会在潜意识里试图使您的数据与预先设想的假设相匹配时,挤压掉数据的纹理和细微差别。
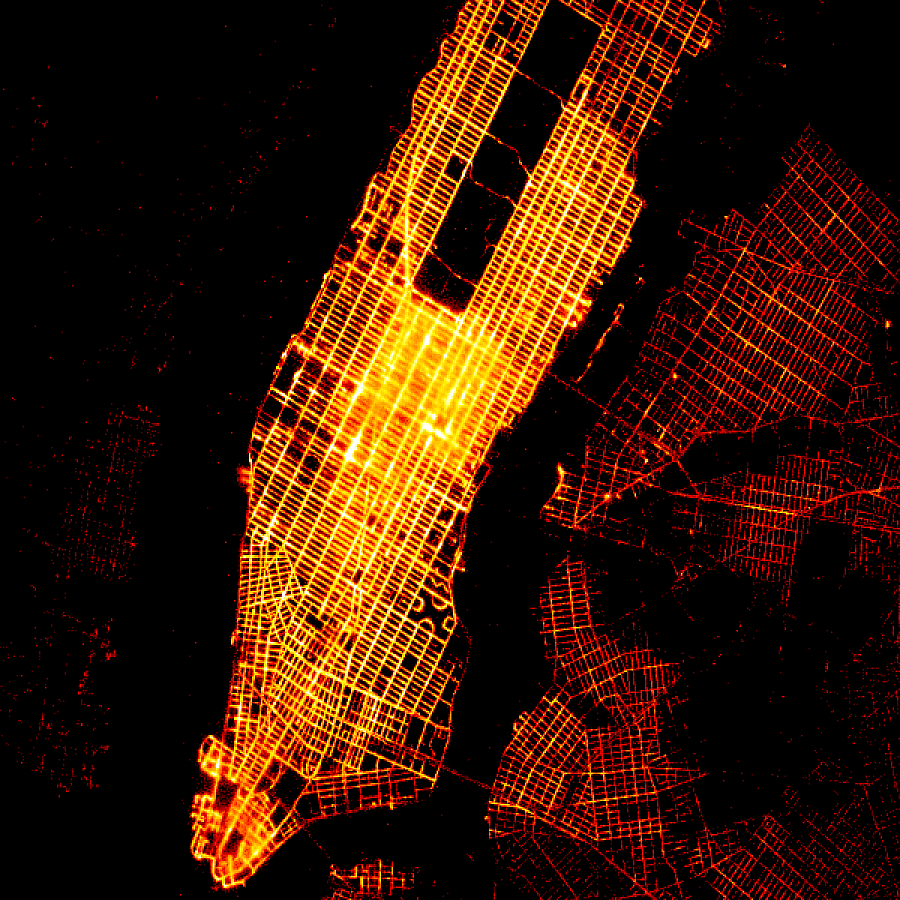
这些类型的数据可视化是非从业者最熟悉的,因为它们包括我们经常看到的用于解释基于数据的趋势和模式的图表和图形。像这样的数据可视化是传达信息的非常强大的工具,这使得做好它们非常重要。
一个出色的叙述性数据可视化可以精确地传达作者对数据的理解,同时还传达数据中的任何不确定性或局限性。它不是数据讨论的唯一输出或最终产品,而是更大对话的一部分。这种类型的数据可视化应指示执行的分析、做出的假设、考虑的数据以及未包含的数据。在构建叙述性数据可视化时,重要的是不仅要考虑您自己的经验,还要考虑最终用户。例如,他们可能是色盲,并且无法区分红色和绿色。此外,还要考虑叙述性数据可视化的美学;例如,在美国,许多观众会将绿色与“好”联系起来。
鉴于如今有无数种方法可以使今天的图形看起来具有视觉吸引力,例如使用花哨的图形或动画,因此有意地使用叙述性数据可视化尤其重要。在追求创建这些可视化效果的过程中,至关重要的是不要跳过高质量的数据科学过程——如今在数据可视化方面,有无数种方法可以给猪涂口红,但如果核心数据或假设存在缺陷,那么图表看起来有多好都无关紧要。不应为了清晰的视觉故事而牺牲准确性。
作为数据科学家,我们有权帮助塑造商业决策、公共政策、医学研究和日常生活的其他重要领域。我们有责任负责任地和合乎道德地实践我们的技艺,这包括数据可视化过程。在我们的能力范围内,我们需要确保我们的可视化清晰地表明可能融入我们结果中的任何假设或偏见,并且它们支持观看者提出进一步的问题,而不是充当任何讨论的“句号”。无论目的是探索性还是叙述性,数据可视化都将从根本上锚定查看数据和主题的方式,因此如果值得首先制作图表,那么就值得花时间做好它。
与我们的专家之一交流,为您的 AI 之旅找到解决方案。

