Excel 中的 Python
2023 年 8 月 22 日
在 Excel 中使用 Python 进行数据可视化入门

Microsoft 和 Anaconda 新推出的 Excel 中的 Python 集成允许访问整个 Python 生态系统,用于数据科学和机器学习。由于它与 Anaconda Distribution 的直接连接,我们可以直接在 Excel 工作簿中利用 NumPy、pandas、Seaborn 和 scikit-learn 等软件包的内置功能。这篇文章将解释一个简单的用例,用于在 Excel 中创建您的第一个机器学习实验。我们将展示在机器学习实验中执行的一些最常见的步骤(例如,数据分区、特征分析),将常见的 Python 任务转换为 Excel 工作簿。
注意:要重现本文中的示例,安装 Excel 中的 Python 试用版。
在 Excel 中开始您的第一个机器学习实验非常容易!您只需要安装了新 Excel 中的 Python 集成的 Excel。您不需要在计算机上预先安装 Python,也无需设置具有特定软件包的特殊环境。嵌入在 Excel 单元格中的所有 Python 代码都将自动提交并在 Microsoft Azure 云上托管的沙盒环境中运行。此环境由 Anaconda 提供,使您可以立即访问最流行的用于数据科学和机器学习的 Python 堆栈。
让我们从打开一个新的空白 Excel 工作簿开始,命名为 My first Machine Learning Experiment.xlsx。
为了熟悉新的 Excel 中的 Python 集成,我们将首先编写一些简单的 Python 代码来显示有关我们的 Python 环境的信息。
在左上角的单元格 (A1) 中,让我们为我们将在单元格 A2 中显示的内容创建一个标题。类似“Python 环境信息”。
现在让我们移动到另一个单元格(例如,B1)并键入“=PY”来创建我们的第一个 Python 单元格。或者,您可以使用 Ctrl+Shift+Alt+P 键盘快捷键。现在让我们编写以下 Python 代码
import joblib
import sklearn
import numpy as np
import pandas as pd
import sys
env_info_details= f"""
Python: {sys.version[:6]} # we will just retain version number info
numpy: {np.__version__}
pandas: {pd.__version__}
scikit-learn: {sklearn.__version__}
Available CPUs: {joblib.cpu_count()}
"""
env_info_details在代码中,我们正在收集有关我们正在运行的 Python 版本的信息,以及环境中可用的 NumPy、pandas 和 scikit-learn 软件包的版本以及可用内核的总数。为了简单起见,我们将此信息存储在 env_info_details 变量中,该变量被定义为多行 f-string 变量,以便更快地格式化。
如果我们通过按 Ctrl+Enter 提交代码,我们将触发其执行。应生成以下输出
Python 3.9.10
numpy: 1.23.5
pandas: 1.5.3
scikit-learn: 1.2.1
Available CPUs: 1💡 注意 1:如果 Python 输出未以多行格式显示,这是因为 Excel 单元格格式规则未设置为允许文本“换行”。这是因为单元格格式和 Python 生成输出是 Excel 中的两个独立概念。换句话说,Excel 单元格格式属性将始终覆盖任何 Python 格式。
💡注意 2:您可能已经注意到我们没有使用 Python print 函数来生成单元格的输出,而是返回了 env_info_details 字符串变量。这是因为在 Excel 中使用 Python print 函数仅限于诊断信息(可通过“公式”>“Python”>“诊断”访问)。相反,如果我们返回一个字符串(即 str 对象)作为单元格的结果,则该对象将被转换为 Excel 输出并显示。这正是我们在第一个 Python 代码片段中所做的。
从我们的第一个示例中,我们可以看到我们的环境运行在 Python 3.9 和 scikit-learn==1.2.1 上(有关此版本的更多信息,请参阅相应的发行说明)。
现在让我们关注我们将在整个实验中使用的数据集。我们将使用一个经典的数据集,即 Iris 数据集。这可能是机器学习文献中最著名的数据集之一,并且被广泛用作机器学习实验的参考示例。因此,该数据集已自动集成到许多机器学习库和工具中。scikit-learn 在其 datasets 软件包中提供了此 数据集 的副本:sklearn.datasets.load_iris。
如果您不熟悉该数据集:我们将使用 150 个虹膜花样本的集合,每个样本都以一组四个不同的特征为特征,即萼片长度、萼片宽度、花瓣长度和花瓣宽度。每个虹膜样本都属于一个物种:Setosa、Versicolor 或 Virginica。机器学习任务是自动对所有虹膜样本进行分类。
与我们对 Python 环境所做的类似,现在让我们收集有关 scikit-learn 中可用的数据集的信息。让我们在新创建的 Python 单元格中编写以下代码。
在我的示例中,我将在单元格 D1 中编写,但请随意组织您的电子表格内容,如您所愿。
from sklearn.datasets import load_iris
iris = load_iris(as_frame=True)
X = iris.data
y = iris.target
ds_info_details = f"""
{X.shape[0]} samples
{X.shape[1]} features
{y.values.ndim} target
"""
ds_info_details您应该看到以下输出
150 samples
4 features
1 target太棒了!是时候直接在 Excel 中查看此数据了!
在之前的代码片段中,我们创建了 Python 对象,其中包含对特征和目标的引用,即 X 和 y 变量作为 pandas.DataFrame 对象。由于传递给 load_iris scikit-learn 函数的 as_frame=True 参数,这两个数据集作为 pandas.DataFrame 对象返回。
Excel 中的 Python 集成具有 DataFrame 对象的内置功能,可以轻松地跨多个单元格显示(在 Excel 术语中称为“溢出”)。
实际上,如果我们移动到一个空单元格(例如,A3)并创建一个新的 Python 公式(即 =PY),该公式仅包含对 X 变量的引用,然后我们按 Ctrl+Enter 运行,则将显示整个数据集

同样,我们可以通过键入以下 Python 公式在特征旁边显示相应的目标(例如,在 E3 单元格中,以避免重叠)
y.to_frame()您可以在下图看到最终输出。

太棒了!🎉
现在我们已经通过 Python 将我们的数据集直接集成到我们的 Excel 工作簿中!这是直接在我们的工作簿中访问 Python 的巨大好处之一:我们可以将代码和数据集成到 Excel 中。
值得强调的是,本文中探讨的所有内容都可以类似地应用于 Excel 中已有的任何数据集。
在进入下一节之前,让我们首先将当前工作表重命名为更有意义的名称,例如,数据集。在 Excel 工作簿中工作时,我们可以更好地将我们的实验组织到多个电子表格中,每个电子表格都专用于我们实验中的单个步骤。
现在机器学习实验真正开始了。要开始,您将从数据分区开始。我们将从我们的原始数据集中创建两个不同的数据分区,它们将用于训练和测试我们的机器学习模型。
因此,让我们在我们的工作簿中创建一个新的电子表格,命名为步骤 1 – 数据分区。
要创建我们的训练和测试数据分区,我们可以使用 scikit-learn 中包含的 train_test_split 实用程序函数,就像我们在 Jupyter notebook 中运行代码一样。与 notebook 类似,底层执行模型假定每个单元格之间共享一个全局命名空间。特别是对于 Excel 工作簿,这假定执行顺序从第一个工作表的左上角单元格开始,并以行优先方式进行。这意味着在一个单元格中定义的任何变量、函数或 Python 对象对于执行顺序中接下来的所有单元格也是可见和可访问的。
在上一节中,我们创建了对我们的特征和目标数据的引用,由 X 和 y 变量作为 pandas.DataFrame 引用。然后,我们可以在我们的新工作表中引用这些相同的变量并生成我们的数据分区。
让我们创建一个新的 Python 单元格(例如,在 A2 中),我们将在其中添加以下代码
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
random_state=12345,
stratify=y)
X_train现在,我们的命名空间包含四个新变量:X_train、y_train、X_test 和 y_test,分别保存对训练和测试的特征和目标的引用。当前单元格仅返回将溢出到相邻单元格的 X_train DataFrame。我们现在可以像上一节中那样继续填充其他数据,以可视化整个数据集,如下所示
y_train.to_frame() # e.g., in cell E2
X_test # e.g., in cell G2
y_test.to_frame() # e.g., in cell K2由于固定的随机种子(即 random_state=12345)和用于 test_size=0.25 的默认值,您应该得到完全相同的结果,训练和测试分区中分别有 112 个和 38 个样本。

现在让我们通过可视化训练和测试分区中特征的成对分布来探索我们的数据。
让我们首先创建一个新的电子表格,使用与上一节相同的约定命名:步骤 2 – 特征分析。通过这种方式,我们将保持工作簿的组织性,每个电子表格对应我们实验的单个步骤。
为了快速生成和可视化特征的成对分布,我们可以使用 seaborn.pairplot 函数。我们的数据已经以 DataFrame 的形式存在,因此我们只需要将特征和相应的目标连接在一起,因为 pairplot 函数期望单个 DataFrame 对象。此外,我们可能需要重复相同的操作来可视化训练和测试数据的特征分布。因此,编写一个我们可以使用不同数据多次调用的函数是明智的。
现在让我们创建一个新的 Python 单元格(例如,在 A1 中),使用以下代码
import seaborn as sns
from matplotlib import pyplot as plt
def feature_plot(X, y, title):
as_df = X.join(y) # join features, and targets
pplot = sns.pairplot(as_df, hue="target", markers=["o", "s", "D"],
diag_kind="hist", palette="tab10")
pplot.fig.suptitle(title, y=1.04)
return pplot
# merely return to have a label as cell output
"feature_plot function definition" 您可能已经注意到,在 feature_plot 函数定义之后,我们定义了一个 Python 字符串,即“feature_plot 函数定义。”。这是一个有用的技巧,用于标记不产生任何直接输出的 Python 单元格的内容。此单元格仅定义将在稍后的其他公式中重用的 Python 函数。
现在让我们在新 Python 单元格(例如,在 B1 中)中调用新的 feature_plot 函数,用于训练数据
feature_plot(X_train, y_train, title="Training Set - Feature Plot")默认情况下,图像将自动嵌入到当前单元格中。此时您有两个选择:
⚠️ 注意:如果您将图像从当前单元格中分离出来,则用于生成图像的所有 Python 代码都将丢失,因为该对象将不再存在于 Python 单元格中。在撰写本文时,此行为似乎仅限于以图像作为输出的单元格。
因此,建议使用 选项 1,并且将在本文中通篇使用。
在我们的案例中,这不会是一个大问题,因为我们编写的唯一 Python 代码只是一个函数调用。 因此,这里要传达的总的经验是:每当您的 Python 单元格预期根据其输出来生成图像时,最好将单元格中的代码限制为仅仅调用一个函数来生成图形,该函数已在其他地方定义!

这就是最终特征图在您的工作簿中的样子。 这些图表特别具有信息量,因为它们使我们能够定性地评估每对特征在分隔两个分区中的三个类别时是多么informative(信息丰富)。 事实上,一些特征在区分不同的鸢尾花种类方面似乎特别有效(例如,花萼长度与花瓣宽度,训练集数据中的右上角),而其他特征对则不太有用(例如,花萼宽度与花萼长度)。 在这种情况下,一种可能性是尝试使用降维方法在较低维度空间(例如,在 2D 中)上工作。
降维最流行的方法之一是主成分分析 (PCA),其旨在找到连续的正交成分(即维度),以解释最大量的方差。 让我们尝试在 Excel 中使用 PCA 处理我们的鸢尾花数据。
这次,我们还将尝试一些新的东西:让我们在一个新的 Python 单元格(例如,E1)中编写代码,并将其输出设置为 Python 对象(而不是默认的“Excel 值”)。 我们将在稍后讨论这种选择的含义。 现在让我们关注要包含的代码片段
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X_train)
pca代码本身非常简单:我们首先创建一个新的 PCA 模型,我们在训练数据上拟合模型,然后我们返回(训练好的)PCA 模型实例作为单元格输出。 这样做,我们可以通过简单地引用 Excel 单元格来随时引用模型实例。(这在接下来的步骤中将很有用,当我们想要直接访问 PCA 模型来缩放数据时)。
现在让我们创建一些实用函数,以在一个新的 Python 单元格中缩放数据并生成图表
def scale_data(X, y):
"""Utility function to scale data, and join them into a unique data frame"""
X_scaled = pca.transform(X) # X_scaled is a numpy array
X_scaled_df = pd.DataFrame(X_scaled, columns=["x1", "x2"])
X_scaled_df["target"] = y.values
return X_scaled_df
def plot_pca_components(X, y, title):
"""Utility function to visualize PCA components"""
X_scaled_df = scale_data(X, y)
pca_plot = sns.relplot(data=X_scaled_df, x="x1", y="x2",
hue="target", palette="tab10")
pca_plot.fig.suptitle(title, y=1.04)
return pca_plot
"plot_pca_components and scale_data function definitions"第一个函数只是缩放数据并将其作为 pandas.DataFrame 返回,以便更好地与 Seaborn 集成,将特征和目标堆叠在一起。 生成的数据帧将用于 plot_pca_components 函数中,以生成传递数据的 relplot 图。
我们将在 (X_train, y_train) 和 (X_test, y_test) 对上调用后一个函数,以可视化训练和测试数据集的 PCA 成分(在 2D 中)。
完整的工作表应类似于下图所示。 正如预期的那样,在较低维度的数据上工作可能会帮助分类模型。

在缩放数据后,PCA 帮助我们更好地理解了数据。 让我们看看聚类算法(例如,k-均值)如何划分我们的(缩放后的)数据,以及这些分区如何映射到实际预期的类别(即,鸢尾花种类)。
让我们创建一个新的工作表,命名为“步骤 3 – 探索性聚类”。
首先,我们需要生成一个新的 k-means 实例,该实例将在初步使用 PCA 算法缩放的数据上进行训练。 为了避免重复代码和浪费计算,我们可以通过直接引用具有“Python 对象”输出的 Python 单元格,从先前的工作表中直接访问经过训练的 PCA 模型。 为此,我们将使用特殊的 xl() Python 函数。
让我们创建一个新的 Python 单元格并将其输出设置为 Python 对象
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, n_init="auto")
pca_model = xl("'Step 2 - Feature Analysis'!E1") # reference the trained pca model
X_train_scaled = pca_model.transform(X_train)
kmeans.fit(X_train_scaled)
kmeans使用与 PCA 模型相同的“技巧”,我们将返回经过训练的 k-means 聚类模型实例,以便稍后直接访问。
现在让我们定义我们的函数,以在一个新的 Python 单元格中可视化聚类分区
def visualize_kmeans_clustering(X, y, title):
cluster = xl("A1")
X_scaled = scale_data(X, y)
features = X_scaled[["x1", "x2"]]
y_cluster = cluster.predict(features.values)
X_scaled["cluster"] = y_cluster
cluster_plot = sns.relplot(data=X_scaled, x="x1", y="x2",
hue="target", style="cluster", palette="tab10")
cluster_plot.fig.suptitle(title, y=1.04)
return cluster_plot
"visualize_kmeans_clustering function definition" # as cell output值得注意的是,我们正在引用聚类实例,通过 xl() 选择器函数选择前一个单元格(第 2 行:cluster = xl(“A1”))。 此外,我们正在重用上一节中定义的实用函数 scale_data,以使用 PCA 缩放数据并将结果作为数据帧获取,以便与 Seaborn 一起使用。
为了最终可视化我们的聚类结果,我们将再次依赖 seaborn.relplot 函数,但这次使用了一个额外的技巧。 每个元素(点)的颜色将由实际预期的类别(即,hue=”target”)确定,而标记将根据聚类标签(即,style=”cluster”)分配。 通过这种方式,我们将能够定性地评估聚类标签和预期类别之间存在多少同质性。
为了验证这一点,让我们在两个新的 Python 单元格中调用 visualize_kmeans_clustering 函数,并在显示图像作为单元格内容时使用前面提到的“陷阱”。 在下图中,聚类已相当成功地执行,在类别 1 和 2(即“杂色鸢尾花”和“维吉尼亚鸢尾花”)中的一些样本周围存在一些混淆。

我们终于到达了我们简单的机器学习实验的最后一步,在其中我们将训练一个分类模型并生成分类报告。
让我们开始创建一个新的工作表,命名为“步骤 4 – 鸢尾花分类”,以处理我们实验的最后代码片段。
在这一点上,我们拥有训练分类模型所需的一切
为了生成信息丰富的分类报告,我们应该包含分类指标的值(在这种情况下,accuracy_score 可以接受),以及相应的混淆矩阵。
让我们创建一个新的 Python 单元格,其中包含以下代码
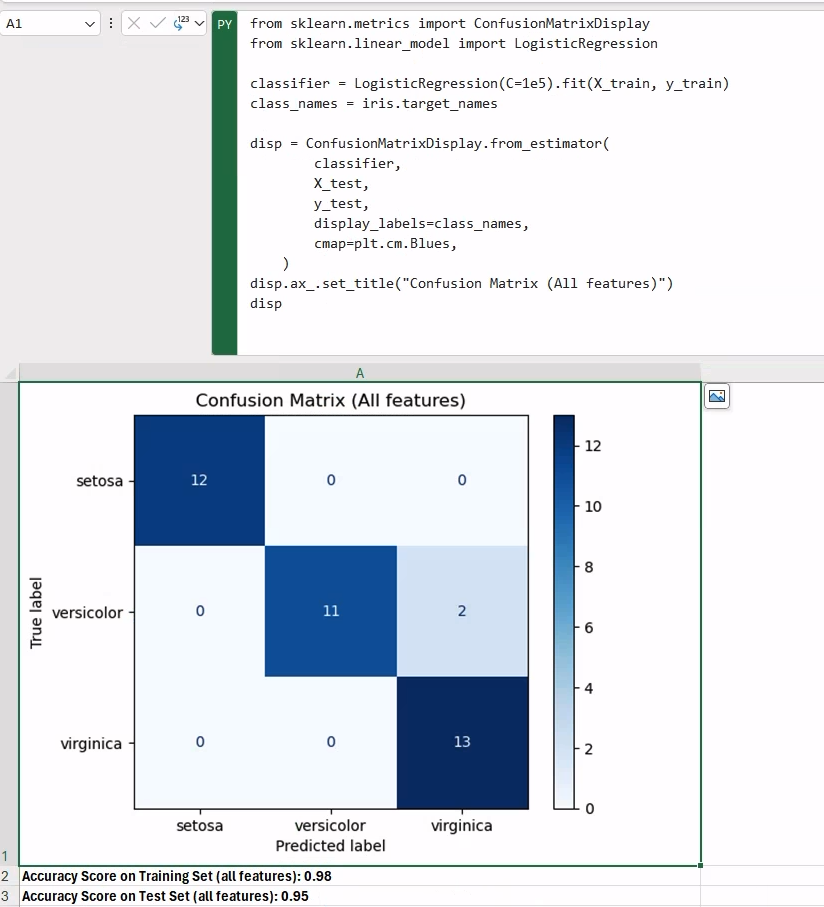
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(C=1e5).fit(X_train, y_train)
class_names = iris.target_names
disp = ConfusionMatrixDisplay.from_estimator(
classifier,
X_test,
y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
)
disp.ax_.set_title("Confusion Matrix (All features)")
disp分类模型是 LogisticRegression,考虑到手头的数据,该模型应该运行良好。 为了显示我们的混淆矩阵,我们使用了 scikit-learn 中的 ConfusionMatrixDisplay 实用程序类,它可以生成给定训练分类器的矩阵。
一旦我们有了训练好的分类器,在其他单元格中打印分数结果就像调用模型实例上的 score 方法一样简单,分别用于训练和测试数据:
f"Accuracy Score on Training Set (all features): {classifier.score(X_train, y_train):.2f}"f"Accuracy Score on Test Set (all features): {classifier.score(X_test, y_test):.2f}"作为练习,您可以尝试使用 PCA 将 X_train 数据替换为 2D 缩放版本,以查看性能会发生多大变化。
在这篇博文中,我们探讨了新的 Excel 中的 Python 集成如何使您能够在 Excel 工作簿中使用 Python 构建完整的机器学习实验。 我们完成了机器学习实验的多个步骤(从数据分区到最终分类报告),利用了与 Anaconda Distribution 的内置集成,该集成提供了对流行的数据科学和机器学习工具和库(如 pandas、scikit-learn 和 Seaborn)的直接访问。
本文中创建的工作簿的最终版本可在此处获取。 免责声明:Microsoft Excel 中的 Python 集成在本文发布时处于 Beta 测试阶段。 功能和函数可能会发生变化。 如果您发现此页面上有错误,请随时联系我们。
Valerio Maggio 是 Anaconda 的研究员和数据科学家倡导者。 他也是一位开源贡献者,并且是 Python 社区的活跃成员。 在过去的 12 年中,他为许多国际会议和社区聚会(如 PyCon Italy、PyData、EuroPython 和 EuroSciPy)做出了贡献并担任志愿者。
与我们的专家之一交谈,找到您 AI 之旅的解决方案。

