Excel 中的 Python
2023 年 8 月 22 日
使用 Excel 中的 Python 创建您的第一个机器学习实验

使用 Excel 和 Python 创建有效数据报告的最常见方法通常需要将数据加载到 Jupyter notebook 中 (例如,使用 pandas),并将 notebook 本身转换为报告以与利益相关者共享。 但是,如果我们不再需要在外部 Jupyter notebook 中工作,而是可以直接在 Excel workbook 中使用 Python,会怎么样呢?
在本文中,我们将探讨 Excel 中的 Python 如何使 Excel 用户能够直接在 Excel 电子表格中使用 Python 和 Anaconda Distribution。
注意:要重现本文中的示例,请安装 Excel 中的 Python 试用版。
数据报告对于与利益相关者沟通见解至关重要。Microsoft Excel 是一款功能强大的工具,使用户能够操作和可视化甚至大量数据。 借助数据透视表、数据表和各种统计函数等广泛的内置功能,Excel 被广泛应用于许多行业(例如,金融、会计和销售),以快速轻松地生成有效的数据报告。 然而,处理数据从来都不是“直线”,因为我们必须预处理(例如,清理、过滤、分组、转换)原始数据集,以便提取有意义的见解。 在通常情况下,我们会将整个工作负载迁移到 Python 代码(及其丰富的数据科学库和工具生态系统),但现在我们可以使用 Python 及其强大的库(例如 pandas),而无需离开 Excel。
Python 直接集成到 Excel 中,通过大量的科学计算和数据科学软件包(例如 NumPy、pandas、SciPy、Matplotlib、scikit-learn)增强了 workbook 的功能。
在这篇博文中,我将演示如何在 Excel workbook 中使用新的 Python 功能来实现有效的数据报告。
Excel 的主要创新是新的 =PY 单元格,它可以立即在 workbook 中启用 Python。 您可以通过选择一个单元格并键入“=PY”或使用键盘快捷键来在 Excel workbook 中创建一个新的 Python 单元格
Ctrl+Shift+Alt+P
为了强调我们正在新的 Python 单元格中工作,单元格及其编辑器的左边框将立即变为 深绿色(见下文)。

如您所见,该扩展程序还集成到公式窗格中,以快速创建新单元格或查看现有单元格。
注意:目前,Excel 中的 Python 功能仅供 Windows 用户使用。未来将扩展到 Mac 用户;请继续关注更新。
首先要澄清的是,您无需在计算机上预先安装 Python 即可在 Excel workbook 中运行 Python。 所有执行都在 Microsoft Azure 上的沙盒环境中自动进行。 因此,工作互联网连接是必要的。 由于沙盒执行环境,运行在单元格中的 Python 代码不允许访问互联网或本地文件系统。 因此,以下任何读取数据的 Python 代码都将不起作用
requests.get("https://url_to_my_fantastic_dataset")
# OR
pd.read_csv("C:\\Users\\Valerio\\Downloads\\my_fantastic_dataset.csv")
# OR
sklearn.dataset.fetch_california_housing() # requires internet to download the data新的 Excel 中的 Python 扩展程序完全由 Anaconda 提供支持:Anaconda Distribution 在后端自动使用,因此无需担心环境,因为所有用于数据科学和机器学习的主要软件包都已在 Excel 中提供:NumPy、SciPy、Matplotlib、Seaborn、statsmodels 和 scikit-learn,仅提及一些最受欢迎的软件包以及我们将在下一节的工作示例中使用的软件包。
当从外部 Jupyter notebook 过渡到 Excel workbook 时,最后要记住的是这两种格式之间的相似之处和差异,因为它们直接影响如何组织代码以及代码将如何执行。
Notebooks 和电子表格都是面向单元格的格式;内容组织成多个连续的单元格。 然而,虽然电子表格模型是二维的(即行和列),但 notebook 只是在一维中展开(即单列)。
Excel workbook 可以由一个或多个电子表格组成——因此,底层数据模型实际上是三维 (3D) (电子表格、行、列)。 Excel 中 Python 代码的执行将遵循相同的 3D 模型,从第一个电子表格的左上角单元格开始,并以行优先的方式继续。
在 Excel 中编写 Python 代码时,请牢记此模型。 例如,如果您在位于 C10 的 Python 单元格中导入一个软件包,由于所有单元格共享一个全局命名空间(类似于 Jupyter Notebook 单元格),因此该软件包也将在从 C11 开始的任何其他 Python 单元格(在当前电子表格中)以及之后的任何其他电子表格中可用。 但是,此软件包在 B1 中不可用,B1 比导入它的位置早一行。
尽管底层数据模型存在这些差异,但在 Excel workbook 的单元格中编写 Python 代码的开发最佳实践与 Jupyter notebook 的单元格相同:选择代码片段,而不是难以阅读和维护的较长代码清单。
在 workbook 中而不是在 Jupyter notebook 中编写 Python 的最大区别在于,单元格中包含的 Python 代码会自动“隐藏”,并且每个单元格的内容会自动替换为代码产生的任何返回值。 如果代码没有直接返回值,则默认情况下将显示“None”作为单元格内容。
如果这还不清楚,请不要担心。 我们将在稍后的示例中深入探讨单元格输出。
现在让我们探索一个具体的示例,了解 Excel 中的 Python 如何有效地工作和应用。
您可以直接下载此 财务示例 Excel Workbook。 下载并在 Excel 中打开后,我们要做的第一件事是将 Sheet1 电子表格重命名为“Financial_Data”,然后我们将添加一个名为“Report”的新电子表格。
给电子表格赋予有意义的名称通常是一个好习惯,并且也会使我们的电子表格在本文的后续部分中更容易引用。
在新的“Report”电子表格中,让我们在左上角单元格 (A1) 中添加我们的第一行 Python 代码
import pandas as pd
# This will be automatically converted into a pandas.DataFrame
df = xl("'Financial_Data'!A1:P701", headers=True)
# Make sure that the date column is interpreted as datetime
df["Date"] = pd.to_datetime(df["Date"])
# return value of the cell
df使用 Ctrl+Enter 提交 Python 代码并触发其执行。
执行后,这将生成一个 pandas.DataFrame,表示 workbook 中的数据。 借助新的 xl() 函数,我们能够选择 Excel 单元格的 RANGE,这些单元格在移植到 Python 运行时环境时会自动转换为 pandas.DataFrame。
现在让我们让事情变得更有趣。 我们不复制所有数据,而是利用 pandas 的过滤和分组功能来生成此数据的聚合版本。
现在让我们回到相同的 A1 单元格,并使用以下代码修改内容:
import pandas as pd
# This will be automatically converted into a pandas.DataFrame
df = xl("Financial_Data!A1:P701", headers=True)
# Make sure that the date column is interpreted as datetime
df["Date"] = pd.to_datetime(df["Date"])
# Aggregate by 'Country' and 'Segment' and then sum all the values in the 'Sales' column
country_segments = df.groupby(["Country", "Segment"], as_index=False)
.agg({"Sales": "sum"})
# return value of the cell (grouped data)
country_segments如果我们尝试运行此代码,我们会收到一个错误! ⚠️

这是一个很好的机会来了解当代码错误发生时事情会是什么样子。
显然 pandas 无法找到标记为 Sales 的列。 这是因为原始列名(即标题)包含空格:“ Sales ”而不是“Sales”)。 因此,我们应该从列名中删除此格式,以便以编程方式引用它们! 还记得吗? 处理数据从来都不是“直线”!
让我们通过添加一个解决方法来修复列名,从而重写我们的代码片段
import pandas as pd
# This will be automatically converted into a pandas.DataFrame
df = xl("Financial_Data!A1:P701", headers=True)
# Make sure that the date column is interpreted as datetime
df["Date"] = pd.to_datetime(df["Date"])
# Fix column names by stripping white space
df.columns = [col.strip() for col in df.columns]
# groupby
country_segments = df.groupby(["Country", "Segment"], as_index=False)
.agg({"Sales": "sum"})
# return value of the cell
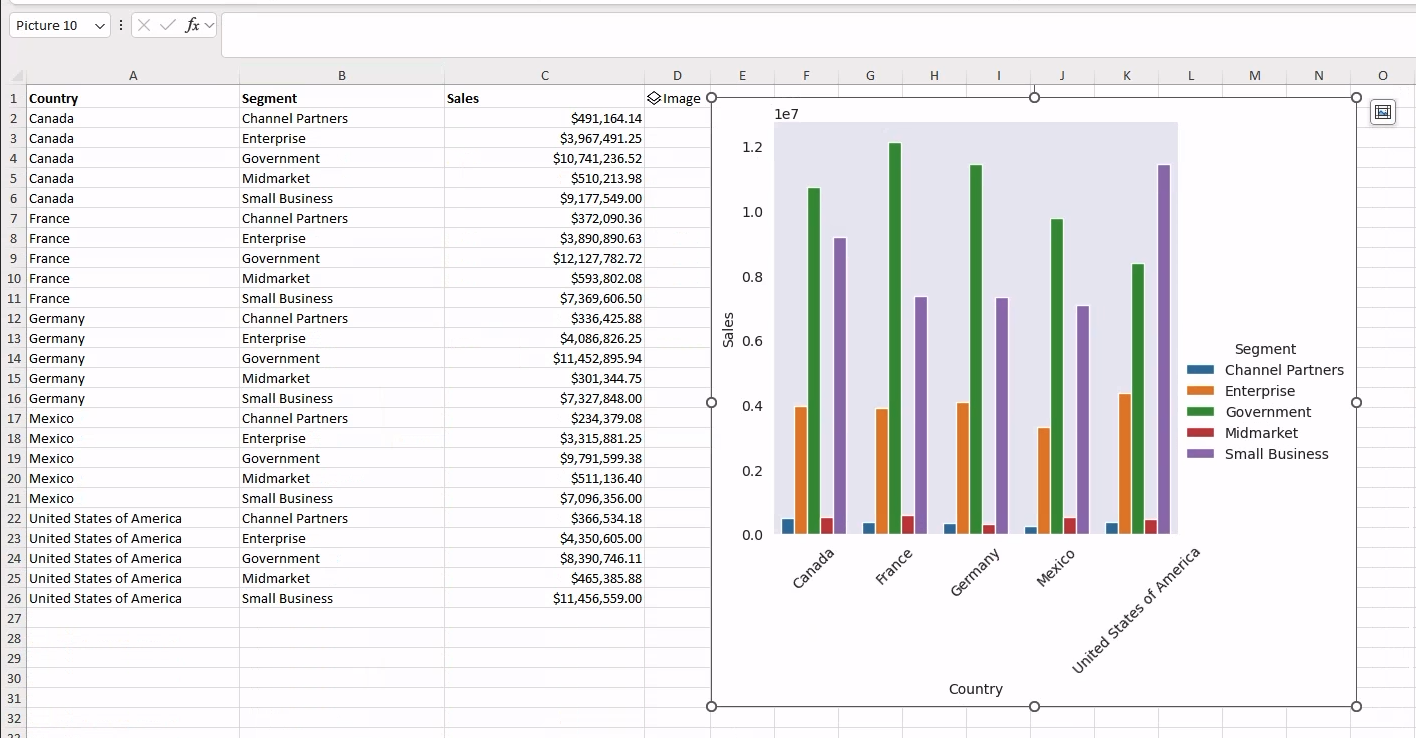
country_segments要提交并运行代码,请在单元格中按 Ctrl+Enter。 您应该获得以下结果(请参见下图)

生成输出后,我已用粗体标记了结果标题,即 Sales、Country 和 Segment,以提高可读性。 实际上,始终可以更改电子表格中单元格的格式以提高可读性。 同样,我们可以将新生成的 Sales 列中单元格的格式设置为货币

现在我们有了聚合数据,让我们使用 Seaborn 生成聚合销售额的图表。 具体来说,我们将生成一个 catplot,因为我们的聚合轴是分类轴(即 Country 和 Segment)。
让我们移动到单元格 D1 并输入 =PY。 但是,这次让我们通过单击单元格左侧的下拉菜单将其输出标记为 Python 对象。
Python 单元格的默认输出设置为“Excel 值”,这在下拉菜单中使用此图标标记: ![]() 。 当我们将单元格的输出设置为“Python 对象”时,菜单中的图标将变为此图标:
。 当我们将单元格的输出设置为“Python 对象”时,菜单中的图标将变为此图标: ![]() 。
。
当需要在单元格中显示图像时,默认的“Excel 值”输出会将图像直接显示在单元格中。 但是,如果我们决定分离单元格中的图像,则用于生成图像的所有(Python)代码都将丢失。
这通常不是问题,但为了本文的目的,我们希望将 Python 代码保留在单元格中并可视化结果图。 因此,将单元格的输出设置为 Python 对象 是更灵活的解决方案。
现在让我们将以下 Python 代码添加到 D1 中新创建的 Python 单元格中:
from matplotlib import pyplot as plt
import seaborn as sns
fig = plt.figure()
plot = sns.catplot(data=country_segments, x="Country", y="Sales", hue="Segment", kind="bar")
# FIX xticks labels orientation to improve readability
for axes in plot.axes.flat:
_ = axes.set_xticklabels(axes.get_xticklabels(), rotation=45)
# The figure object will be returned as Output
fig 当我们提交并运行代码时,这就是您应该在 workbook 中看到的内容

通过这种集成,Excel 现在内置了对 workbook 单元格中显示的 Python 对象 的支持。 图中 D1 单元格中显示的 Image 对象直接引用了底层的 Python 对象。
最后,为了可视化生成的图表,我们可以从上下文菜单中选择“图像”(如下图所示),或者在 E1 单元格中键入以下指令
=D1.Image

这将显示生成的分类图,然后可以将其放置在单元格上以进行进一步自定义。

在这篇博文中,我们探讨了新的集成如何使 Excel 用户能够直接在 Excel workbook 中利用 Python,而无需将分析转移到 Jupyter notebook 中。 Excel 中的 Python 由 Anaconda Distribution 提供支持,后者提供对丰富的数据科学和机器学习 Python 软件包生态系统的即时访问。 此扩展目前仅适用于 Windows 用户,并且仍处于 Beta 测试阶段。 因此,可能会出现错误,并且情况可能仍会发生变化和改进。 尽管如此,这项技术解锁的潜力确实是前所未有的,它为在 Excel 中执行数据分析提供了一种全新的方式。
您可以通过此链接查看本文中开发的 workbook。
免责声明:Microsoft Excel 中的 Python 集成目前处于 Beta 测试阶段。功能和函数可能会发生变化。如果您发现此页面上有错误,请随时联系我们。
Valerio Maggio 是 Anaconda 的研究员和数据科学家倡导者。 他也是开源贡献者和 Python 社区的活跃成员。 在过去的 12 年中,他为许多国际会议和社区聚会(如 PyCon Italy、PyData、EuroPython 和 EuroSciPy)做出了贡献并担任志愿者。
与我们的专家之一交流,为您的 AI 之旅寻找解决方案。

