众所周知,每个科学、工程或分析学科都有其独特的计算需求。事实上,许多这些学科已经开发了完全独立的工具集来处理数据,涵盖数据存储、读取、处理、绘图、分析、建模和探索。
不幸的是,大多数现有的栈都基于过时的架构和假设
- 不适用于云或远程:通常绑定到本地 GUI 或仅限桌面的操作系统
- 不可扩展:代码仅在单个 CPU 上运行,无论出于技术原因还是许可问题,并假设数据在本地可用
- 非通用:绑定到有关数据内容的严格假设,这限制了创新和协作,也限制了受众、维护者社区和潜在的资金来源
现在是时候采用更好的方法了,Python 社区已经创造了它!
什么是 Pandata?(以及为什么你需要它)
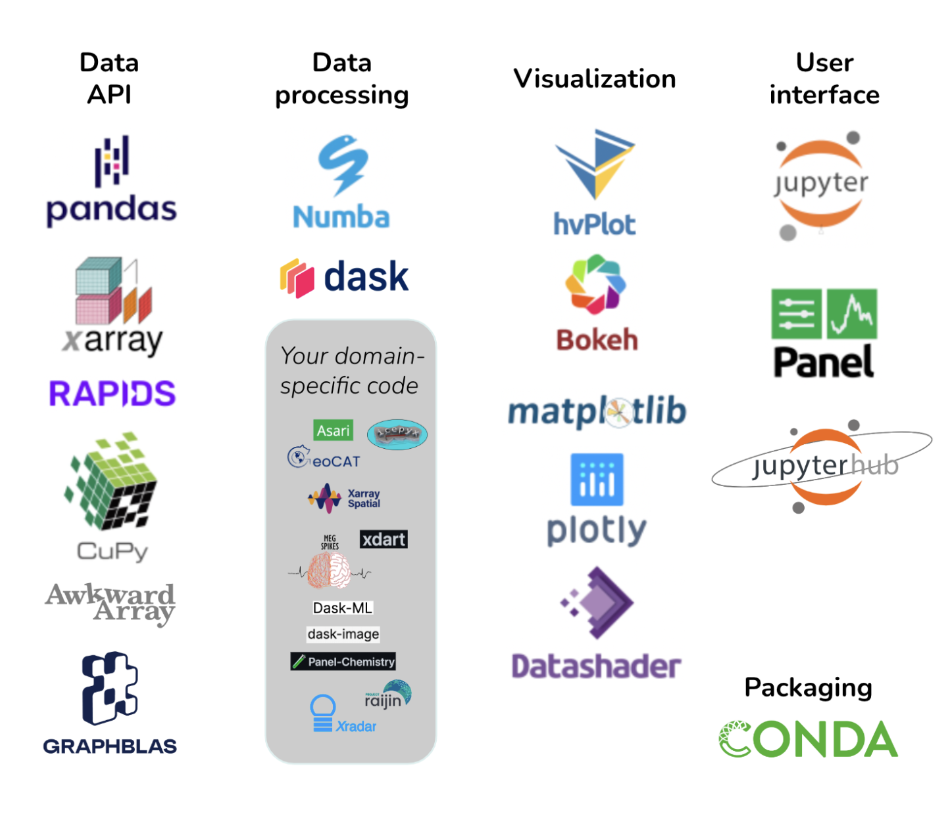
Pandata 是一个开源 Python 库集合,这些库可以单独使用,并由不同的人分别维护,但它们协同工作以解决大问题。你可以使用 Pandata 网站来确定数千个可用的 Python 库中哪些库符合 Pandata 关于可扩展性、交互性、云支持等的标准。Pandata 包括 Parquet 和 Zarr 数据格式、Pandas、Xarray 和 Rapids 数据 API、Numba 和 Dask 高性能计算工具、hvPlot、Bokeh、Matplotlib 和 Datashader 可视化工具、Jupyter 和 Panel 用户界面工具,等等!
使用 Pandata 的 12 个理由
Pandata 是一个可扩展的开源分析栈,可以在任何领域使用。与其使用特定于你领域的工具,不如使用现代 Python 数据科学工具,这些工具是
- 领域独立:由许多社区成员在全球范围内使用、维护和测试,并从许多不同的来源获得资金
- 高效:利用矢量化数据或 JIT 编译以机器代码速度运行
- 可扩展:可以在从单核笔记本电脑到拥有数 PB 数据的千节点集群的任何地方运行
- 云友好:使用任何文件存储系统,包括本地、集群或远程计算
- 多架构:在 Mac/Windows/Linux CPU 和 GPU 上运行,在你的桌面或远程服务器上运行方式相同
- 可脚本化:以批处理模式运行以进行参数搜索和无人值守操作
- 可组合:为了解决你的问题,选择你需要的工具并将它们组合在一起
- 可视化:渲染甚至最大的数据集,无需转换或近似
- 交互式:支持完全交互式探索,而不仅仅是渲染静态图像或文本文件
- 可共享:可以部署为 Web 应用程序,供任何人在任何地方使用
- 开源软件 (OSS):免费、开放,并可用于研究或商业用途,无需限制性许可或限制分享和重用
请注意,许多 Pandata 工具通常用于数据科学领域,而不是任何特定的科学或研究领域。你可能不认为自己正在做数据科学,但数据科学工具只是处理数据的几种方法,它们适用于许多学科!数据科学不仅仅用于人工智能 (AI)、机器学习 (ML) 和统计学,尽管它也很好地支持这些领域。
谁在运行 Pandata?
Pandata 没有专门与之相关的管理、策略或软件开发;它只是一个GitHub 上的信息网站,由一些 Pandata 工具的作者创建。查看该网站,考虑使用这些工具,如果它们满足你的需求,请放心地使用它们,因为它们通常可以协同工作来解决问题。如果你有任何问题或想法,请随时打开一个问题,说明如何处理 Pandata。
示例
网上有很多将 Pandata 库应用于解决问题的示例,包括
- Pangeo:JupyterHub、Dask、Xarray 用于气候科学;Pandata 是任何领域的 Pangeo
- Project Pythia:特定于地球科学的示例,其中许多示例使用 Pandata 工具
- 吸引子:使用 Numba 处理大型数据集,使用 Datashader 渲染
- 人口普查:从 Parquet 读取分块数据,使用 Dask + Datashader 渲染
- 船舶交通:使用交互式查找渲染空间索引数据
- Landsat:Intake 数据目录、xarray n 维数据、hvPlot+Bokeh 绘图、Dask ML
- Minian:Jupyter、Dask 和 HoloViews 用于神经科学
你可以下载并以任何组合使用任何 Pandata 包,并享受拥有所有这些功能的便利。有关更多信息,请参阅SciPy 2023 的 Pandata 论文。


 (17)")