选择适用于 Python 和开源的企业平台:买家核对清单
更新于 2023 年 6 月 30 日

简介
Marc Andreessen 在 2011 年 8 月的一篇博客文章中以一句挑衅性的话开篇:“软件正在吞噬世界。” 他的预测是,软件开发将颠覆传统行业。 事实上,像 Airbnb、Netflix 和 Uber 这样的公司只是“按需”经济中众多赢家中的一小部分,它们以重大而持久的方式颠覆了旅游、娱乐和购物等行业。
大约一年后,在 2012 年 10 月,《哈佛商业评论》报道称,数据科学家是“21 世纪最性感的工作”,它承诺专业人士可以“从非结构化数据中提取宝藏”。 结构化数据竞赛由此开始,各组织开始更仔细地审视其混乱的数据,并寻找使其更易于机器理解的方法。
快进七年到 2019 年 10 月,麦肯锡全球研究所对“人工智能春天的到来”提出了令人兴奋和警示的言论。 他们的研究表明,数百个商业案例加起来,有可能每年创造 3.5 万亿美元至 5.8 万亿美元的价值。 随着组织应用人工智能,他们发现它可以产生超额的商业价值。 数据科学能力成为高性能 AI 的先决条件,因此组织增加了对技术、数据科学团队以及机器学习和深度学习等技术的投资。
2022 年 8 月,Stable Diffusion 以其使用 Python 和深度学习构建的文本到图像模型震撼了视觉艺术界,该模型可以根据文本提示生成详细图像。 它激发了世界对 AI 的迷恋,并掀起了下一波浪潮:生成式 AI。
最后,三个月后,在 2022 年 11 月,OpenAI 发布了另一个生成模型:ChatGPT,这是一个大型语言模型 (LLM),它使用在 OpenAI 的 GPT-3 和 GPT-4 LLM 上的训练来根据用户的提示生成文本。 在短时间内,LLM 已席卷许多行业,新的产品和功能使 程序员能够与机器一起编写和调试代码,并使 作家能够与 AI 合作制作内容,这仅仅是越来越多用例中的几个例子。
寻找企业平台
凭借所有这些进步,似乎每个组织都应该以某种方式将这些新技术融入到他们的研究、产品和运营中。 然而,要充分发挥这些技术的潜力,需要一套功能齐全的工具、干净且结构化的数据、专家团队以及开源软件的力量,并由积极参与的创造者和维护者社区提供支持。
在整个企业组织中利用开源软件的力量,需要具备构建和部署安全 Python 解决方案的能力。 有越来越多的选项可用于将各种工具拼接在一起,从而使团队能够协作并使用数据科学和机器学习构建强大的应用程序。 但是,将工具拼凑在一起以将预测模型部署到生产环境中并不是创建组织可以依赖的平台以交付卓越成果的最佳方法。 而构建自己的平台可能既昂贵又复杂,因为您需要维护您创建的平台。
找到一个企业平台,它可以提供您需要的开源软件包、允许您在生产环境中重现和扩展模型的托管环境,以及保护您的组织免受不良代码和不良行为者侵害的安全工具,可能是一个艰难的挑战。 这正是本指南的全部内容——探讨在选择企业平台以与 Python 和开源软件一起使用以实现组织开发目标时需要考虑的事项。
是什么构成了平台?
关于平台的一个流行的描述来自微软 CEO 比尔·盖茨,正如 Charmath Palapithiya 转述:“平台是指每个使用它的人的经济价值超过创建它的公司的价值。” 当您评估平台时,请考虑以下基本特征,这些特征将帮助您在团队使用 Python 和开源开发和部署应用程序时利用社区的创新
- 个人用户数量: 用户越多,发现他人共享的新技术、更快地识别和解决安全风险以及从由软件制造商和维护者组成的丰富社区中受益的机会就越多。
- 企业用户数量: 企业用户越多,平台在规模上经过的测试就越多。 用户数量可以用组织或企业总数的百分比来表示,例如财富 500 强。
- 经验年限: 组织开发平台的时间越长,其团队就越有可能在工具、技术和用例方面拥有专业知识。
跨行业客户: 平台应用的行业越多,平台和支持团队可能遇到的集成、用例和数据类型就越多。
Python、开源、数据科学和企业
数据科学彻底改变了企业的运营方式。 如今,似乎每个人都在某种程度上与数据打交道,无论是分析客户行为、构建预测模型还是创建生成模型。 随着对数据驱动型洞察的需求持续增长,Python 已成为数据科学工作的首选语言。
事实上,Python 长期以来一直是数据科学工作的黄金标准,这在很大程度上归功于其简洁性和多功能性。 与其他语言不同,Python 允许用户轻松地操作和分析数据,使其成为从数据可视化到机器学习等各种应用的理想选择。 此外,众多开源库和框架的可用性确保了 Python 仍然是数据科学家的热门选择。
开源软件 使开发人员能够访问由全球贡献者组成的网络,他们不断更新和改进代码,使公司能够比以往更快、更高效地创建应用程序。 根据 Synopys 2023 年 OSS 风险分析报告,绝大多数 (96%) 代码库都包含开源软件。
OSS 的广泛应用是有道理的; 开源不仅可以帮助公司节省许可成本,还可以让他们利用开源社区的集体知识来创建定制化的解决方案,以满足其特定的业务需求。 因此,开源已成为希望在快速发展的技术世界中保持领先地位的组织的重要战略工具。
然而,在企业组织中管理 Python 开发在过去几年中变得更加复杂和困难。 这部分是由于 Python 社区内部的快速发展步伐,这导致了新工具和技术的定期发布。 其中一些工具是专有的,而另一些是开源的。 虽然这对从事数据工作的团队来说最终是一个积极的发展,但它可能会使人们难以跟上最新的技术和最佳实践。
尽管存在这些挑战,Python 仍然是可用于数据科学工作的最强大和最通用的工具之一。 随着行业的不断发展,Python 仍将是任何成功的数据科学团队工具箱的关键组成部分。
企业 Python 挑战
在 Anaconda,我们与世界各地使用 Python 的组织进行交流。 我们发现,大多数团队都面临着类似的挑战,并且他们正在尝试以类似的方式来解决这些挑战。
1. 软件包管理和构建环境
对于繁忙的企业团队来说,管理软件包和构建环境是一个重大挑战。 许多团队手动管理软件包,这样做的好处是让他们可以控制每个软件包和环境的自定义。 但是,这既耗时又容易出错。 它还可能导致环境不一致以及缺乏对数据保护和资源治理的监督。
其他团队使用专有的第三方软件包管理工具,这些工具可以简化软件包管理并提供现成的功能。 但是,这些工具不适合 Python 工作流程。 它们提供的自定义功能有限,并迫使您依赖供应商来构建工具以满足您的业务需求。
2. 协作与部署
项目协作是构建和扩展出色模型的重要组成部分,因此可重复性是一个巨大的挑战,尤其是对于大型团队而言。 大多数团队都以分散的方式进行协作,模型位于个人机器上,这导致数据科学家和数据工程师经常听到一句话:“在我的机器上可以运行。”
在部署方面,手动流程可以让您更好地控制管道,但与手动软件包管理一样,既耗时又容易出错和出现可扩展性问题。 构建自己的部署基础设施可以让您进行自定义,并让您拥有更多控制权,但由于高昂的开发和维护成本,您可能会看到较低的投资回报率。
有易于使用的机器学习平台,具有现成的功能和一些支持,但与开源软件相比,这些平台可能非常具有限制性,自定义选项有限。 它们也可能非常昂贵。
3. 治理和保护开源管道
一个可信的开源软件包来源从未像现在这样重要。 2023 年 3 月的 国家网络安全战略 和国家标准与技术研究院 (NIST) 的框架表明,安全负担正在转移到开发软件的组织和个人身上。
手动安全审计可以帮助您满足最低监管要求并识别一些安全风险。 但是,它们也既耗时又资源密集,并且使您的组织处于被动地位。 内部安全培训可以提高意识并促进良好实践,但其有效性有限,并且单靠它是不够的。
第三方扫描工具通常易于使用,并且像某些机器学习平台一样,提供现成的功能和一些支持。 但是,这些工具不适合 Python 工作流程,误报率很高,并且可能会错误处理编译后的软件包。
企业 Python 平台中需要关注的顶级功能:买家核对清单
企业平台应足够灵活,以满足您今天的需求,并且足够强大,以承受您未来工作负载和项目的需求。 您可以使用此清单来评估适用于 Python 和开源软件的企业平台。
基本功能
1. 数据集成
| 其他供应商 | |||
| 可以集成 | 可以集成 | 无法集成 | |
| 代码仓库 (Git, Bitbucket) | ✅ | ||
| 数据湖支持 | ✅ | ||
| 文件系统 | ✅ | ||
| Hadoop (Cloudera, Hortonworks, EMR) | ✅ | ||
| IoT/传感器数据 | ✅ | ||
| 监控解决方案(日志传输) | ✅ | ||
| NoSQL | ✅ | ||
| 专有数据库 (SAS, Teradata) | ✅ | ||
| SQL | ✅ | ||
| Web 数据集成 | ✅ |
2. 基础设施和硬件
| 其他供应商 | ||||
| 支持,并且可以选择气隙网络 | 支持,并且可以选择气隙网络 | 支持,但不提供气隙网络 | 不支持 | |
| AWS Sagemaker | ✅ | |||
| Azure | ✅ | |||
| Domino Data Lab MLOps | ✅ | |||
| ✅ | ||||
| Microsoft Azure | ✅ | |||
| Oracle Cloud Infrastructure (OCI) | ✅ | |||
| Snowpark for Python | ✅ | |||
| 本地部署 (VSphere) | ✅ | |||
| 本地部署(裸机) | ✅ | |||
| 气隙网络 | ✅ | |||
| GPU 和 CPU 支持 | ✅ |
3. 机器学习功能
| 其他供应商 | |||
| 支持 | 支持 | 不支持 | |
| 分类与回归 | ✅ | ||
| 深度学习 | ✅ | ||
| 生成对抗网络 (GANs) | ✅ | ||
| 预训练大型语言模型 (LLMs) | ✅ | ||
| 强化学习 | ✅ | ||
| 支持向量机 (SVMs) | ✅ | ||
| 测试策略(A/B 测试、多臂老虎机、敏感性分析) | ✅ | ||
| 文本到图像模型 | ✅ | ||
| 文本和图像分析与处理 | ✅ | ||
| 时间序列分析 | ✅ |
4. 协作与部署
| 其他供应商 | |||
| 可用 | 可用 | 不可用 | |
| 集中式项目中心 | ✅ | ||
| 一键部署 | ✅ | ||
| 部署 REST API | ✅ | ||
| 部署 Web 应用程序 | ✅ | ||
| 协作和部署的治理控制 | ✅ | ||
| 作业调度器/自动化 | ✅ | ||
| 版本控制 | ✅ | ||
| 可视化和仪表板 | ✅ |
5. 支持
| 其他供应商 | |||
| 可用 | 可用 | 不可用 | |
| 专属支持联系人 | ✅ | ||
| 有保证的正常运行时间 SLA | ✅ | ||
| 访问令牌 | ✅ | ||
| 高级故障排除支持 | ✅ | ||
| Anaconda 软件包管理协助 | ✅ | ||
| 自定义 conda 软件包构建 | ✅ | ||
| 自定义安装程序构建 | ✅ | ||
| 环境管理问题 | ✅ | ||
| 学习:直播和点播 | ✅ | ||
| 高需求期间的仓库访问 | ✅ | ||
| 严重性响应:级别 1 | 12 小时,标准1 小时,高级 | ||
| 严重性响应:级别 2 | 24 小时,标准12 小时,高级 | ||
| 技术支持 | ✅ |
6. 安全和治理
| 其他供应商 | ||||
| 包含 | 包含 | 可以集成 | 不可能集成 | |
| 管理监控(跟踪用户、项目、部署) | ✅ | |||
| 审计日志 | ✅ | |||
| 云原生安全控制 | ✅ | |||
| 灾难恢复 | ✅ | |||
| 端到端加密 | ✅ | |||
| 软件包签名验证 | ✅ | |||
| 发布权限 | ✅ | |||
| 基于角色的用户访问控制 | ✅ | |||
| 扫描常见漏洞和暴露 (CVE) | ✅ | |||
| 安全软件包仓库 | ✅ | |||
| 软件物料清单 (SBOM) | ✅ |
协作与工具
1. Notebooks 和集成开发环境 (IDE)
| 其他供应商 | ||||
| 用途 | 包含 | 包含 | 未包含 | |
| Jupyter Notebook | 创建和共享计算文档 | ✅ | ||
| JupyterLab | 用于 Juypyter 的基于 Web 的界面 | ✅ | ||
| PyCharm | 用于 Python 编程的 IDE | ✅ | ||
| RStudio | 用于 Python 和 R 的 IDE 工具 | ✅ | ||
| Spyder | 用于科学编程的科学 Python 开发环境 | ✅ | ||
| Visual Studio Code (VS Code) | 用于调试、代码片段、代码重构等的源代码编辑器 | ✅ |
2. 数据可视化功能
| 其他供应商 | |||
| 支持 | 支持 | 不支持 | |
| 允许用户选择他们喜欢的绘图库(例如,Bokeh、hvPlot、Matplotlib、Plotly) | ✅ | ||
| 支持完全交互式可视化 | ✅ | ||
| 支持可视化非常大的(即拍字节)数据集 | ✅ | ||
| 支持在 Jupyter 中或作为独立应用程序进行可视化 | ✅ |
3. 数据科学和机器学习库
Anaconda 使您可以访问数千个库。 我们仅列出下面一些最常见的库,以帮助您比较您的选项。
| 其他供应商 | ||||
| 用途 | 可访问 | 可访问 | 不可访问 | |
| Dask | 并行和分布式计算 | ✅ | ||
| Django | 用于设计的 Python Web 框架 | ✅ | ||
| Flask | 模型部署 | ✅ | ||
| Keras | 深度学习框架(TensorFlow 的 API) | ✅ | ||
| Kubeflow | Kubernetes 上的 ML 工作流程 | ✅ | ||
| MLflow | 实验跟踪 | ✅ | ||
| NumPy | 数组上的数学运算 | ✅ | ||
| Pandas | 处理数据集——分析、清理、探索和操作数据 | ✅ | ||
| Prophet | Python 中的时间序列预测 | ✅ | ||
| PyTorch | 开发和训练深度学习模型 | ✅ | ||
| SciPy | 科学和技术计算(基于 NumPy 构建) | ✅ | ||
| Scikit-learn | 用于分类、回归和聚类算法的 ML 库 | ✅ | ||
| TensorFlow | 开发和训练 ML 模型 | ✅ | ||
| Theano | 涉及多维数组的数学表达式(基于 NumPy 构建) | ✅ | ||
| XGBoost | 分布式梯度提升库 | ✅ |
4. 模型部署和管理
| 其他供应商 | |||
| 是 | 是 | 否 | |
| 从 QA 部署 | ✅ | ||
| 部署到生产环境 | ✅ | ||
| 一键部署到预配置的资源 | ✅ | ||
| 在生产环境中优化模型 | ✅ | ||
| 可重复性——回滚到旧模型 | ✅ | ||
| 已部署应用程序的集中管理 | ✅ |
Anaconda 平台使创新成为可能
十多年来,行业领导者一直在使用 Anaconda 平台来构建世界上最具创新性的预测、产品和体验。 数据科学和机器学习团队依靠我们可信赖的软件包和功能来集中管理开源软件访问,并支持一致、可重复的工作流程。
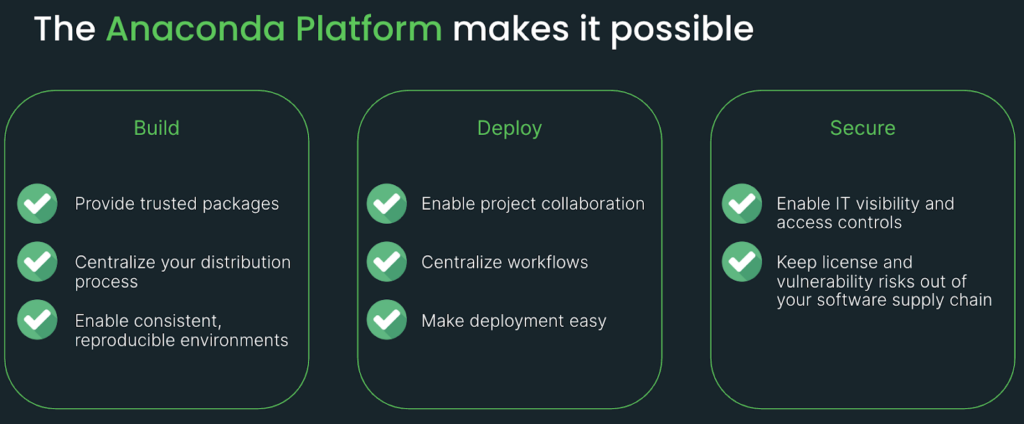
企业从业人员使用我们的平台在用户和团队之间进行协作,集中工作流程以获得更好的可重复性和可扩展性,并一键部署模型到生产环境。
IT 管理员和安全团队选择 Anaconda 是因为它是在 Python 生态系统中唯一可以访问数千个软件包的平台,这些软件包与来自社区软件包提供商的软件包不同,它们是私有托管的、从源代码构建的并且没有恶意软件包。
最后,您可以将 Anaconda 部署在云端或本地——具有私有云、托管托管和气隙网络选项——这使 Anaconda 成为在高度监管的行业和/或处理敏感或受保护数据的人员的首选平台。 有了 Anaconda,安心从幻想变为现实。
准备好了解更多关于 Anaconda 如何帮助您的团队更快地构建和部署安全 Python 解决方案的信息了吗? 与我们的一位专家预约时间,讨论您组织的需求。