新闻产品更新
2023 年 9 月 6 日
Anaconda 助手将生成式 AI 带入云笔记本


新的 Excel 中的 Python 集成允许直接将 Python 代码嵌入工作簿中以处理我们的数据。在本博文中,我们将探索此新集成解锁的最有用和最具创新性的功能之一:使用正则表达式来搜索、替换和验证您的数据。例如,正则表达式允许您在文本中搜索模式(而不是精确的字符串值),或识别和提取要检查和验证的特定部分(例如,文本中的所有 URL)。在 Excel 中,正则表达式是用于高级数据验证的强大工具。我们可以使用正则表达式来确定我们的字符串数据是否与所需的格式或标准匹配,以防止错误并维护数据的完整性。
在本博文中,我们将学习如何使用新的 Excel 中的 Python 集成在 Excel 中使用正则表达式。阅读完本博文后,您将对正则表达式有一个基本的了解,并且您将知道如何在 Excel 中使用它们来在您的工作簿中创建自定义数据搜索和验证逻辑。
注意:要处理本博文中介绍的示例,请安装Excel 中的 Python试用版。
正则表达式(有时也称为RE、regex 或regexp)是用于文本数据操作的强大工具。单个正则表达式包含一个或多个字符序列,也称为搜索模式,用于描述数据中预期的结构。搜索模式随后由字符串搜索算法使用,以检查和查找数据中任何匹配的子序列(子字符串)。因此,正则表达式通常被用作数据验证任务中的工具。正则表达式的典型用例包括验证日期格式、电子邮件地址、电话号码以及任何其他需要特定(正则)模式结构的数据字段。
Microsoft Excel 在搜索或过滤数据时不原生支持正则表达式。因此,只允许精确的文本搜索。在本博文中,我们将学习新的 Excel 中的 Python 集成如何允许在我们的工作簿中直接使用正则表达式创建自定义逻辑函数。
我们将使用一个公开可用的公司员工数据集,以 Excel 表格的形式组织。虽然我们将学习如何使用正则表达式在选定列上实现自定义验证机制,但我们还将发现一些关于使用 Excel 中的 Python 进行高效数据处理的技巧。但在深入实际操作部分之前,让我们先熟悉一下正则表达式,并学习如何在 Python 中使用它们。
从本质上讲,正则表达式是一个字符串,它使用预定义的特殊字符和运算符语法来定义模式。模式是基于各种特征对文本结构和内容的正式描述。这些模式的示例包括:“字符串中允许和/或不允许的字符列表”、“某个字符序列在单词或句子中可以重复多少次”或“给定字符集的长度”。然后,这些模式由regexp 引擎处理和聚合,成为正则表达式的搜索模式。
正则表达式模式使用非常具体的语法来定义,包括特殊字符(也称为元字符)和自定义运算符。例如,表达式 [a-z] 是一个正则表达式,匹配任何单个小写字符,从a 到z。方括号限定一个单个匹配表达式,也称为字符类。尽管每种现代编程语言都提供对正则表达式的原生支持(即无需安装第三方软件包),但这种支持的程度以及用于定义搜索模式的语法可能会有所不同。出于这个原因,在本博文中,我们将考虑 re Python 包支持的 regex 语法,该软件包包含在 Excel 中的 Python 中。
正则表达式语法及其相应的符号列表对于初学者来说非常难,有时即使对于专家用户来说也难以记住。但请放心,我们将详细解释在创建正则表达式时进行高级数据验证筛选器的每一步。此外,我们还创建了一个实用的备忘单,您可以使用它来熟悉正则表达式,或者在需要复习时使用。
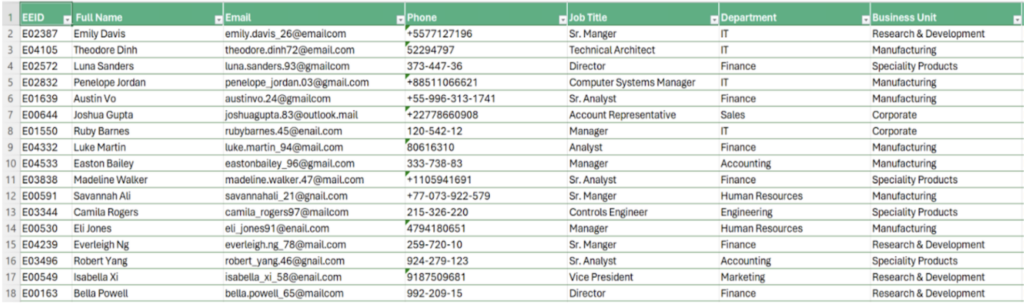
图 1:示例公司员工数据的预览
我们的合成公司员工数据集以 16 列的形式组织,即员工 ID;姓名;电子邮件;电话;职位;部门;业务部门;性别;种族;年龄;入职日期;年薪(以美元计);奖金 %;部门;国家/地区;城市;离职日期。整个数据集包含 1,000 行,因此可以合理地假设我们需要自动化方法来检查和验证我们的数据。
查看从我们的工作簿中提取的数据预览(参见图 1),我们可以立即识别出一些可以从使用正则表达式进行自动化验证中受益的字段:
+1 111 123 4567; +1-111-123-4567; +1.111.123.4567; +11111234567;+1 (111) 1234567 都是有效的电话号码,每个电话号码都具有不同的格式。尽管存在这些差异,我们将看到正则表达式如何使此数据字段的验证变得非常简单。我们的挑战将是定义一个单个正则表达式来捕获所有格式。准备就绪
在深入实施之前,我建议您在工作簿中禁用自动 Excel 公式计算。这将避免在(自动)执行代码时(一次一个条目)在您的数据上出现性能瓶颈,即使是意外的瓶颈。为此,请访问菜单文件 > 选项 > 公式 > 工作簿计算,并将其设置为手动。即使手动计算模式有时会导致与自动模式不同的计算结果,但对于当前的数据而言,此模式是推荐的模式,这样在每张表格行上执行 Python 代码就不会冻结环境。
在 Excel 中使用 Python 时,首先要记住的是,新的集成提供了一个自定义的 xl(“range”, headers) 函数来引用工作簿中的数据。此函数将在整个示例中派上用场,因为它允许我们引用工作簿中的特定(范围)值,并自动转换为 Python 对象,即 DataFrame 或 Series。通过这种方式,我们可以避免逐个单元格进行处理,而是对整个 DataFrame 使用 Python 向量化函数进行操作。虽然这可能看起来是一个很小的差异,但这将对性能产生巨大影响。这种策略允许您将所有数据收集到一个独特的数据结构中,然后将其发送到 Azure 云上的远程沙盒,而不是为小型计算生成大量网络流量。此外,由于单元格按预定义的顺序执行,因此整个执行将按顺序运行,而不是并行运行。虽然在处理少量条目时,这不会产生太大影响,但在处理整个 1000 行数据集时,这会导致性能出现巨大瓶颈。因此,牢记 Python 在 Excel 执行模型中的重要性始终很重要。有关执行模型和其他编程技巧的更多信息,请参阅此 博客文章。
好了!现在是时候编写一些 Python 代码了。首先,让我们定义我们的模式。使用正则表达式匹配 EEID 非常简单:事实上,所有 EEID 都可以通过以下模式捕获:“E\d{5}”,其含义是“大写字母 E 和 5 位数字。” 详细来说,\d 运算符在正则表达式语法中用于表示数字字符,从 0 到 9;而我们表示字符串中必须包含的这些字符的个数(即“量词”)。在本例中,它指的是五位数字。
让我们继续到 R1 单元格,创建一个新的 =PY() 单元格,并编写以下代码
df = xl("A1:A1001", headers=True)
pattern = "E\d{5}"
df.EEID.str.match(pattern)
首先,我们使用 xl() 函数选择整个 EEID 数据列。这将作为 DataFrame 返回,其中包含一个与之同名的列。这是在 xl 函数调用中传递 headers=True 的结果。然后,我们依靠 pandas 字符串函数 match 在多个行上传播模式匹配。请注意,这种方法完全利用了 pandas 内部对数据循环的优化,避免了 Python 中更慢的显式迭代。表达式 df.EEID.str.match(pattern) 的结果是一个 pandas 布尔值序列,即 True 或 False,具体取决于匹配成功或不成功。要查看工作簿中的值,我们可以将 Python 单元格输出切换到“Excel 值”。结果序列中的所有值将被 Excel 自动溢出到 1000 行。如果您愿意,您甚至可以使用条件格式来突出显示这些单元格,以绿色或红色突出显示模式匹配的结果。

图 2:EEID 模式验证。请注意,单元格的输出设置为“Excel 值”。
在验证电子邮件地址时,我们有两个主要目标。首先,我们要识别所有包含无效电子邮件地址的条目。无效的电子邮件地址是指数据中不匹配电子邮件搜索模式的条目。让我们先定义我们的搜索模式,然后我们再解释它。
email_pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
我知道乍一看这可能看起来很吓人,但我保证,如果逐个组件进行分析,它会变得更容易理解。首先,让我们注意到这个正则表达式使用了字符类,它们由方括号标识,即 [ ]。字符类是 regexp 语法的非常方便的功能,用于在更通用的搜索模式中(在本例中为“电子邮件地址模式”)识别多个表达式组。因此,让我们按字符类逐个分析整个模式,从左到右,这样更容易理解。
第一个类(即 [^\s@]+)标识任何不包含空格和 @ 符号的非空(即 + 量词)字符序列。(请参阅备忘单以了解有关 ^、+ 和 \s 运算符的更多详细信息。)这种模式非常通用,因为它允许电子邮件帐户名称尽可能通用,包括任何字母数字或标点符号字符。我们没有关于可能对我们数据中的帐户名称施加的限制的任何指示,因此我们将这种模式保持得非常宽泛,并对变化持开放态度。我们不允许模式中包含的唯一字符是空格(即 \s),因为您无法在帐户名称中使用空格或 @ 符号,因为此字符在电子邮件地址中具有非常特殊的含义。
之后,我们最终期望在我们的电子邮件地址候选字符串中出现一个 @ 符号(即 @),后跟域名-点-域名扩展名的模式。在我们的电子邮件搜索模式中,我们重新使用相同的字符类来匹配域名和扩展名。此外,我们使用反斜杠元字符(即 \.)来转义点字符以进行匹配。
在 S1 Python 单元格中编写的最终代码段将是
df = xl("C1:C1011", headers=True)
email_pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
df["Email Validation"] = df.Email.str.match(pattern)
df["Email Validation"]
为了使结果列的命名更清晰,这次我们将模式匹配的结果作为新的“Email Validation”序列保存到我们的原始 df 数据帧中,然后将其作为单元格输出返回。使用 Excel 条件格式,我们可以立即识别包含无效电子邮件地址的条目。
图 3:无效地址的电子邮件验证结果,使用条件格式。
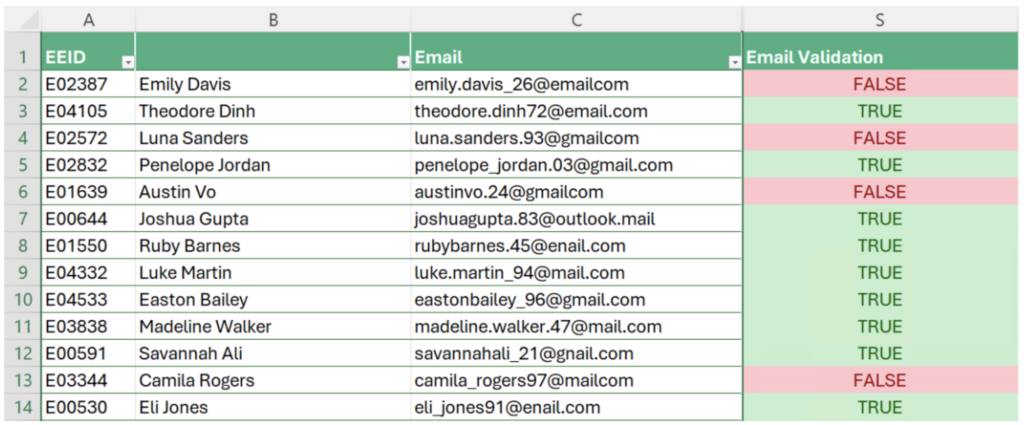
查看结果,我们可以注意到第 13 行的电子邮件地址在域名中缺少一个点,被正确地识别为无效。有趣的是,这种模式无法捕获有效但错误的电子邮件地址。例如,查看第 12 行,Savannah 的电子邮件地址存储为 @gnail.com。因此,我们需要改进我们的验证过程,以包括这些情况。
首先,我们需要识别数据中所有唯一的电子邮件域名,我们再次使用 Python 来实现。让我们在设置为 Python 单元格的 U1 单元格中编写以下代码
df = xl("C1:C1001", headers=True)
pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
df["Email Validation"] = df.Email.str.match(pattern)
emails = df[df["Email Validation"] == True].Email.values
emails = set([e.split("@")[-1] for e in emails])
emails
此代码将选择所有电子邮件,使用我们之前的搜索模式过滤掉所有无效的电子邮件;在 @ 符号字符上拆分条目,并保留最后一个(最右边的)部分。将结果作为 Python 集合返回将保证获取所有唯一值。运行单元格后,您应该获得以下结果
mail.comoutlook.mail
gnail.comenail.comgmail.comemail.com
在我们的数据集中,我们总共有六个唯一的域名,其中一些在mail词语中存在拼写错误,正如预期的那样。因此,我们可以专门化我们之前的搜索模式,以确保所有域名都只匹配正确的域名:
email_pattern = "^([^\s@]+)@((outlook\.mail)|([e|g]?mail\.com))$"
这次,我们将利用 regexp 组(由圆括号标识)来匹配电子邮件地址模式中的所有部分。特别是,第一组匹配帐户名,后跟 @ 符号,然后是域名组。域名实际上被匹配为两个可选子组:前者用于 outlook.mail 域名,后者用于其余三个域名,即mail.com、email.com 和 gmail.com。请注意,如何使用精心设计的类和量词组合,我们可以在单个组表达式中匹配这三个域名,即使用“?”逻辑量词匹配email或gmail或mail词语。如果我们在电子邮件验证代码中使用这个新的电子邮件模式,我们将使用单个 regexp 识别无效和错误的电子邮件地址,从而导致更多条目出现错误。
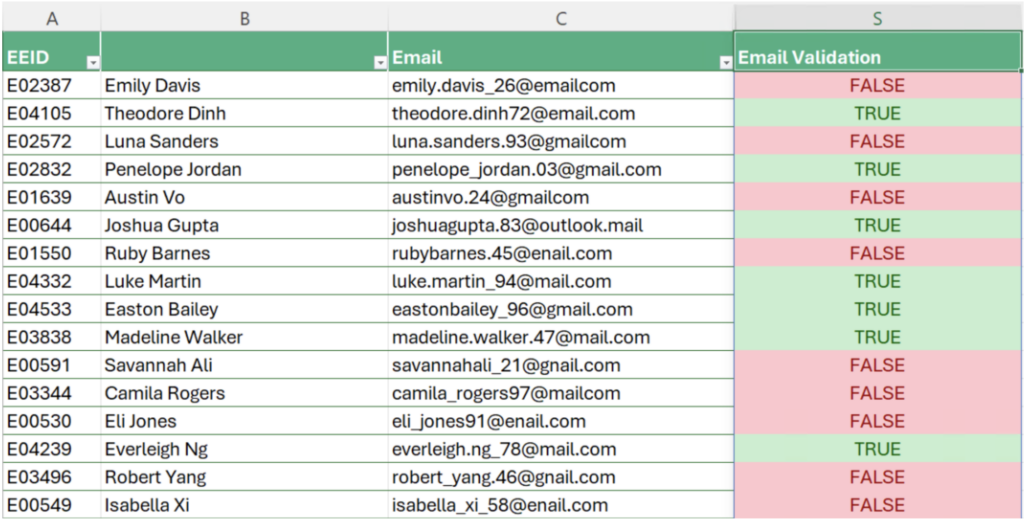
图 3:无效和错误地址的电子邮件验证结果。
处理电话号码的搜索模式很有趣,因为我们可以使用迄今为止使用过的所有 regexp 工具和技巧。首先,让我们列出电话号码的主要组成部分:国家代码;区号和本地号码。与我们处理电子邮件地址验证时所做的一样,我们将通过一次处理一个组,以分而治之的方式构建电话号码的通用搜索模式。
国家代码是电话号码中的可选组件,由一个或多个数字组成,通常以“+”符号开头。所有这些知识以及对我们数据格式的考虑都应纳入正则表达式。匹配国家代码组的一个很好的候选者是
country_code_pattern = "(\+\d{1,3})?"
首先,我们使用反斜杠字符来转义“+”符号的解析(即 \+)。这是为了避免 regexp 引擎将“+”符号解析为量词运算符。然后,我们指示国家代码的数字,这些数字可以由一位到三位数字组成。最后,整个组被标记为可选,使用 ? 逻辑运算符。
区号则用可选的圆括号括起来,由数字组成,其长度可能因国家或地区而异。假设区号可以由一位到四位数字组成:
area_code_pattern = "\(?\d{1,4}\)?"
请注意,使用反斜杠来转义圆括号的匹配,并使用 ? 运算符使其成为可选。
本地号码由数字序列表示,用可选的分隔符(如空格、连字符或句点)隔开
local_number_pattern = "\d{3}[\s.-]?\d{4}"
请注意,在本模式中使用量词与之前的示例有所不同。在本例中,我们指定了期望在每个组中看到的字符的确切长度,即 3 和 4。这些数字由可选的空格、点或连字符隔开,如 [\s.-]? 类捕获的那样。
将这三个组组合成一个单一的搜索模式,并采用字符串的开始(^)和结束 ($) 的分隔符,我们得到了电话号码搜索模式
phone_pattern = "^(\+\d{1,3})?\s?\(?\d{1,4}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"
现在我们需要做的就是将这个模式应用于我们的数据进行测试。让我们在 T1 中创建一个新的 Python 单元格,其中包含以下代码
df = xl("D1:D1011", headers=True)
phone_pattern = "^(\+\d{1,3})?\s?\(?\d{1,4}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"
df["Phone Validation"] = df.Phone.str.match(phone_pattern)
df["Phone Validation"]
图 4 显示了我们数据结果的摘录,使用单元格条件格式突出显示。值得注意的是,正则表达式能够捕获和验证电话号码格式中的多种变化。例如,请查看各种正确号码在乍看之下是如何不同的。
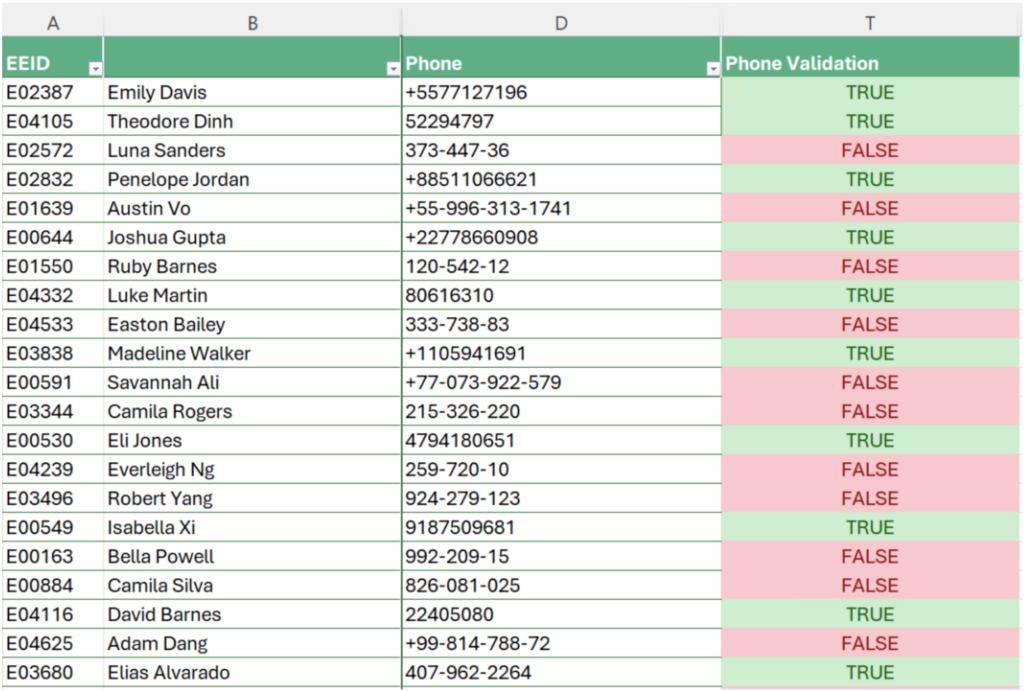
图 4:电话号码验证结果
正则表达式是用于字符串数据验证的极其强大的工具。使用正则表达式,可以检查我们的数据是否符合定义的搜索模式,该模式被定义为特殊运算符和字符序列的组合。在这篇文章中,我们探讨了 Python 在 Excel 集成中如何将这种新功能直接引入到我们的工作簿中,以创建自动数据验证策略。首先,我们介绍了正则表达式的主要概念和运算符,如元字符、字符类和组。然后,我们演示了它们在示例案例中的使用,该示例案例考虑了 1000 个条目的公司员工数据集。使用正则表达式,我们能够识别数据中的拼写错误和不一致,匹配电子邮件地址、员工 ID 和电话号码。包含示例中 Python 代码的 Excel 工作簿的完整版本可在 公开获取。
与我们的专家交谈,找到您人工智能之旅的解决方案。

