Python 在 Excel 中
2024 年 2 月 6 日

许多类型的专业人士使用不同的技能分析数据。Microsoft Excel 用户使用 Excel 数据透视表分析数据,而数据科学家使用统计和机器学习模型。
尽管存在这种多样性,但 Excel 用户、数据科学家和统计学家都拥有一个普遍的数据分析技能:可视化分析数据。
这是由五部分组成的博客系列中的第一篇,向您介绍使用 Python 在 Microsoft Excel 中可视化分析数据。
在本博客系列结束时,您将掌握可视化分析数值数据、分类数据和时间序列数据的基本技能。这些技能对任何专业人士来说都是有价值的,无论其角色或行业如何。
本系列中的每篇文章都附带一个 Microsoft Excel 工作簿供下载,您可以使用它来提升您的技能。本篇文章的工作簿可供在此处下载。
为方便起见,以下是本系列中所有博客文章的链接
关于本博客系列,需要注意以下几点:
最常见的数据分析场景之一是从一列数字中提取见解。这些数字可以是任何东西 - 订单数量、销售额、患者年龄等。
如果该列很小(例如,10 个单独的值),那么查看原始数字并通过回答以下问题来提取见解就相对容易
但是,一列数据很少小到允许这样做。作为人类,我们从一列数字中提取见解的能力会随着列的大小急剧下降。
这就是汇总一列数字发挥作用的地方。Microsoft Excel 函数(如MIN()、MAX()、STDEV.S() 和AVERAGE())通常用于汇总数值数据并提供见解。
虽然上述函数(以及 Python 等价物)无疑是有帮助的,但它们只讲述了故事的一部分。这就是可视化分析数字列发挥作用的地方(双关语意!)。
本篇文章将使用 2014 年美国 50 个州、哥伦比亚特区和波多黎各的人口数据来向您介绍如何可视化分析数字列。
注意 - 本博客文章附带的Excel 工作簿包含一个原始数据工作表,其中包含数据集,可用于代替使用 Anaconda 工具箱导入数据。
此数据集可从 Anaconda 工具箱加载项轻松访问。工具箱位于公式下方的 Excel 功能区中的加载项。

图 01 - 查找 Anaconda 工具箱
登录工具箱后,您将看到以下内容
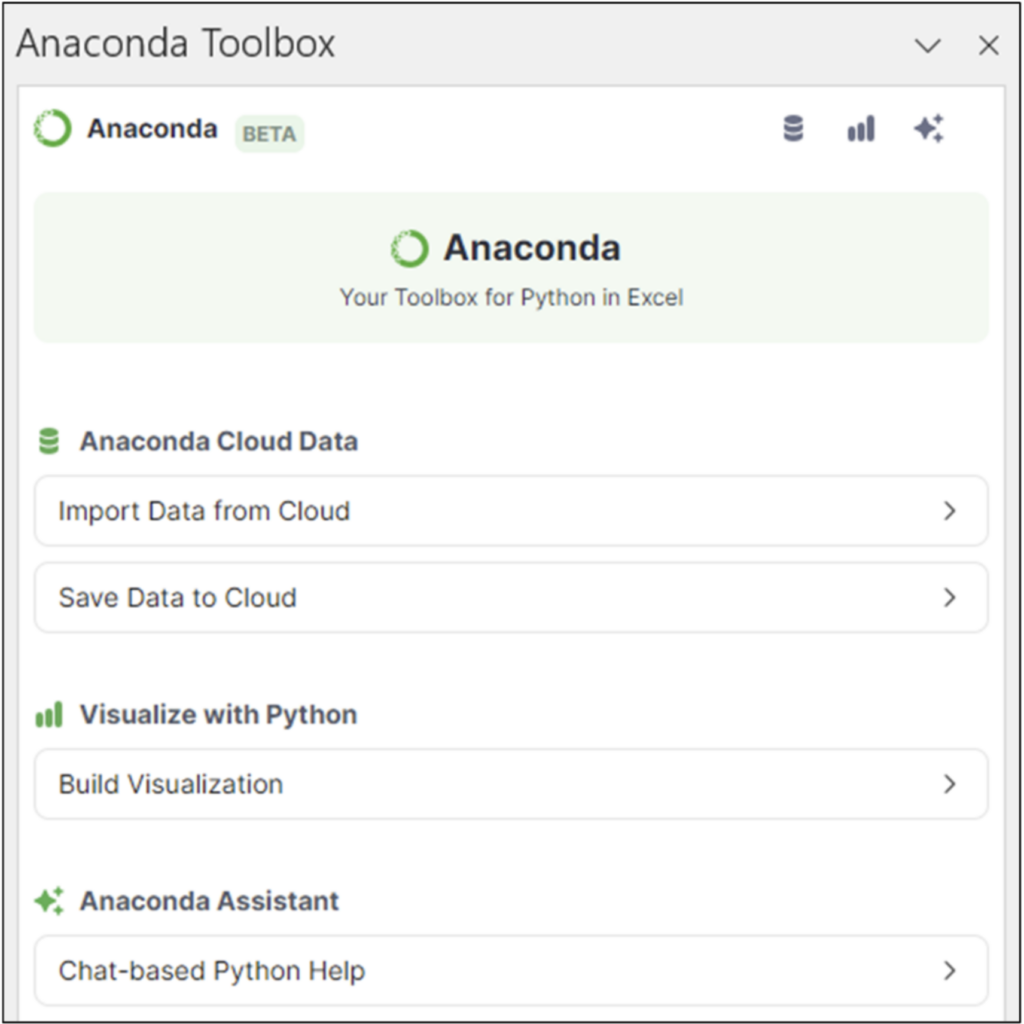
图 02 - Anaconda 工具箱用户体验
除了获取数据集外,工具箱还提供许多其他功能。这些功能将成为 Anaconda 未来内容(例如,博客和课程)的重点。
Anaconda 提供许多免费数据集,可以导入您的 Excel 工作簿中。在工具箱中单击从云端导入数据将显示您已导入的数据
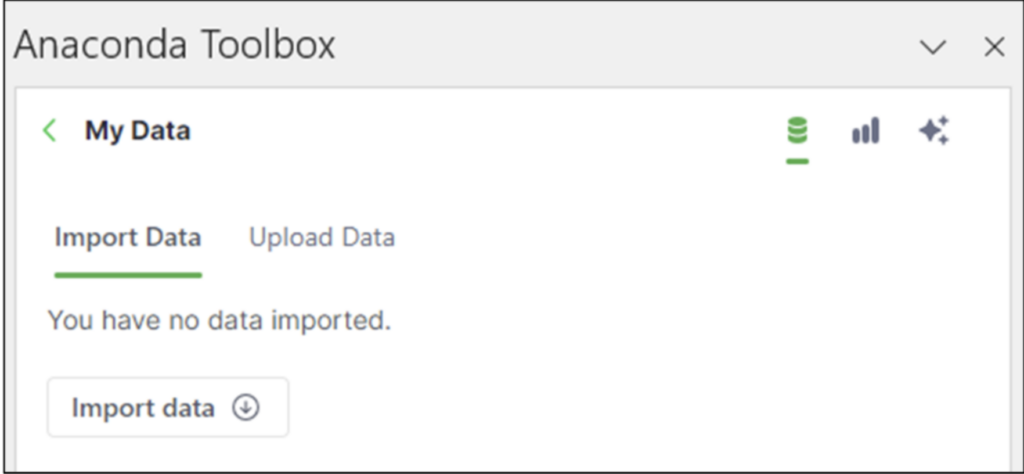
图 03 - 现有数据导入
单击导入数据按钮将提供以下选项
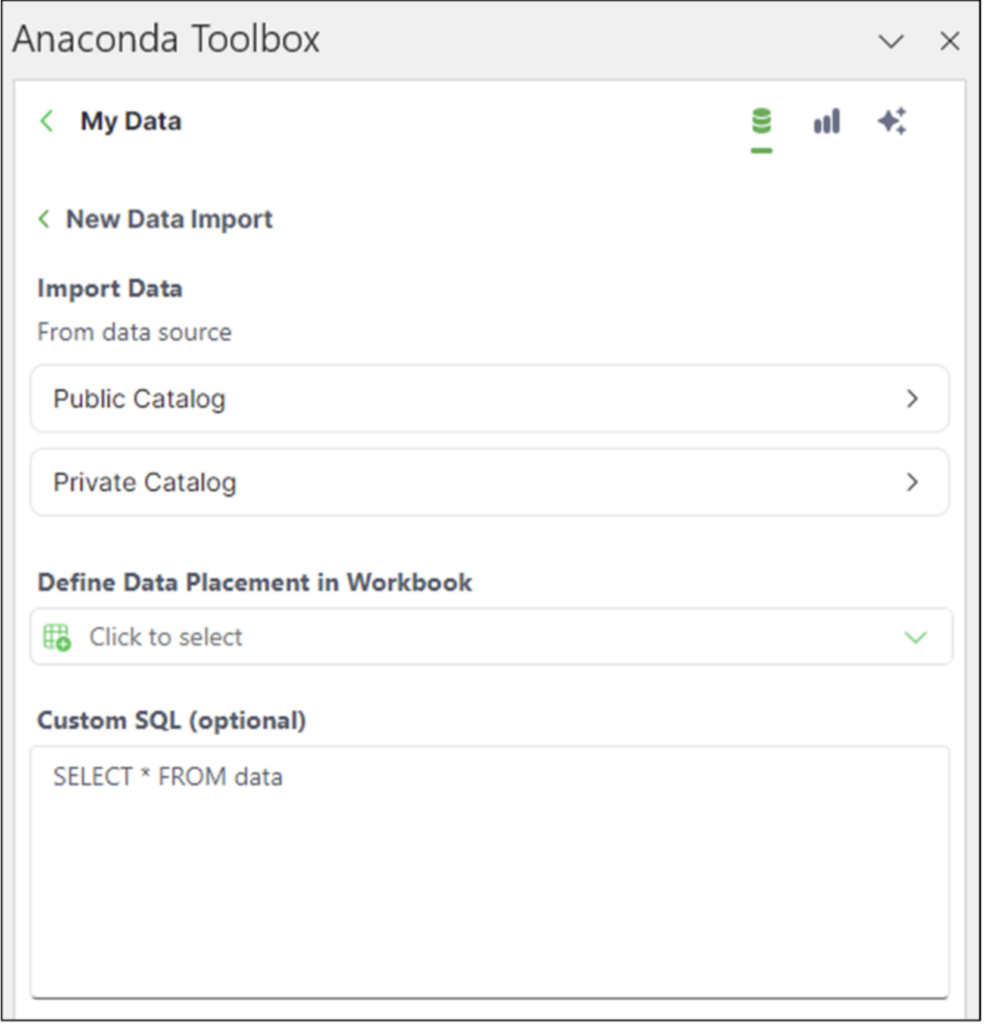
图 04 - 导入数据选项
本博客文章中使用的数据集位于公共目录中。单击此选项将列出公开可用的数据集
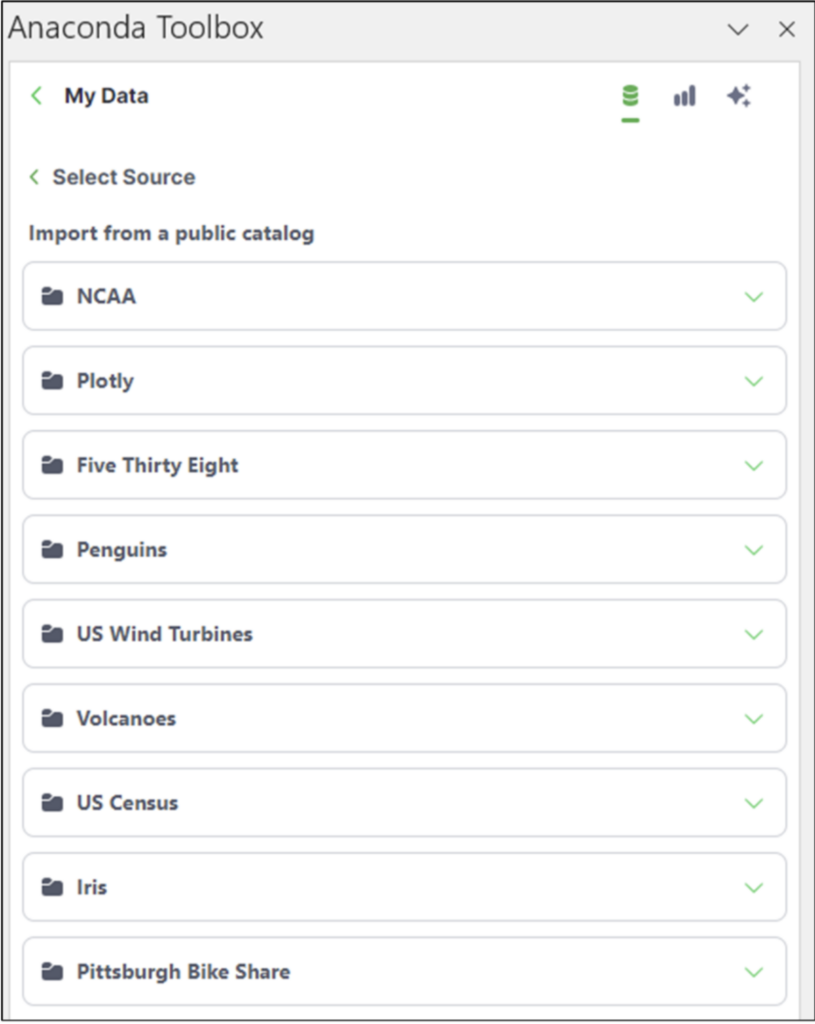
图 05 - 公开可用的数据集
2014_us_states_population 数据集位于Plotly 文件夹中。单击该文件夹将列出Plotly 数据集
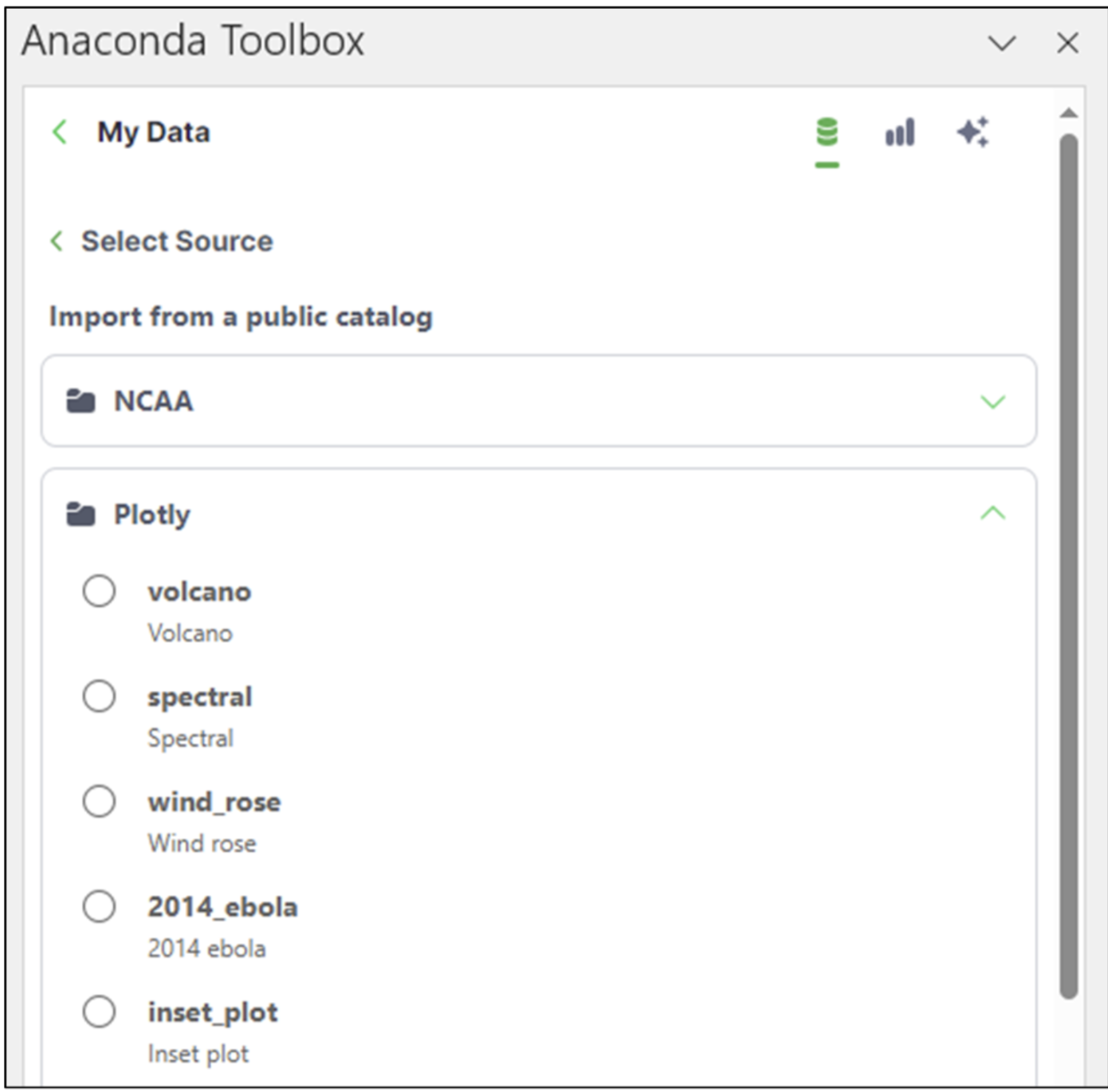
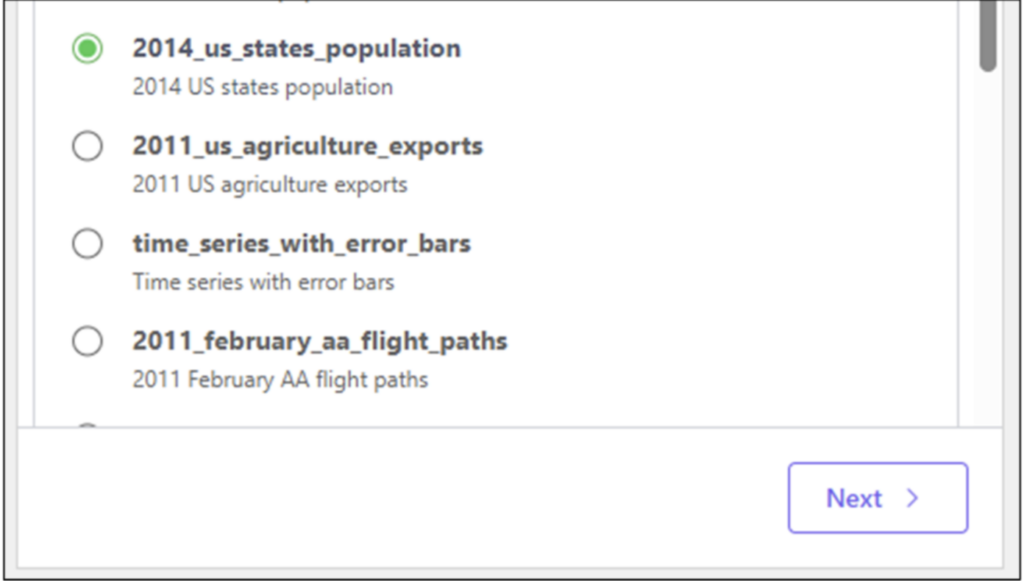
图 06 - 2014_us_states_population 数据集
向下滚动列表,找到2014_us_states_population 数据集,选择它,然后单击下一步按钮。在工具箱中,选择US State Pop 2014 工作表
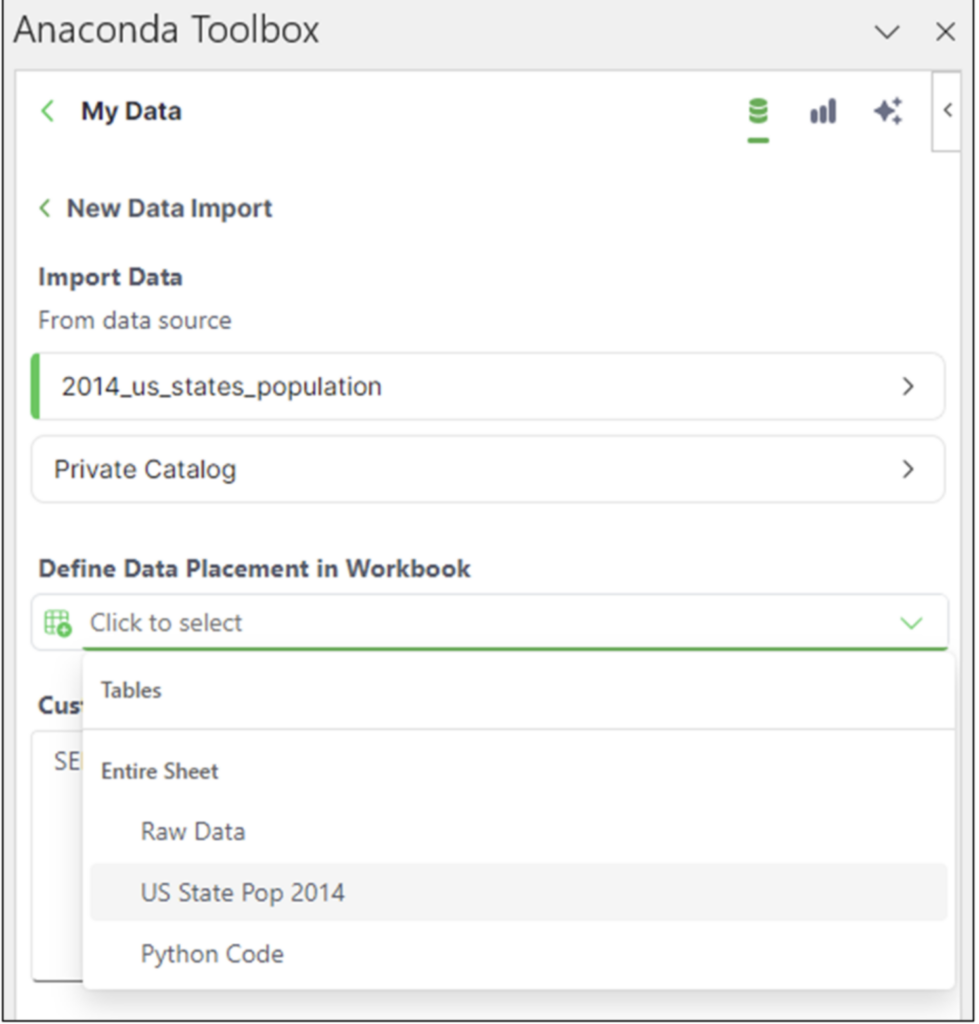
图 07 - 选择要导入数据的目标位置
选择工作表后,单击导入按钮。数据将加载到选定的工作表中
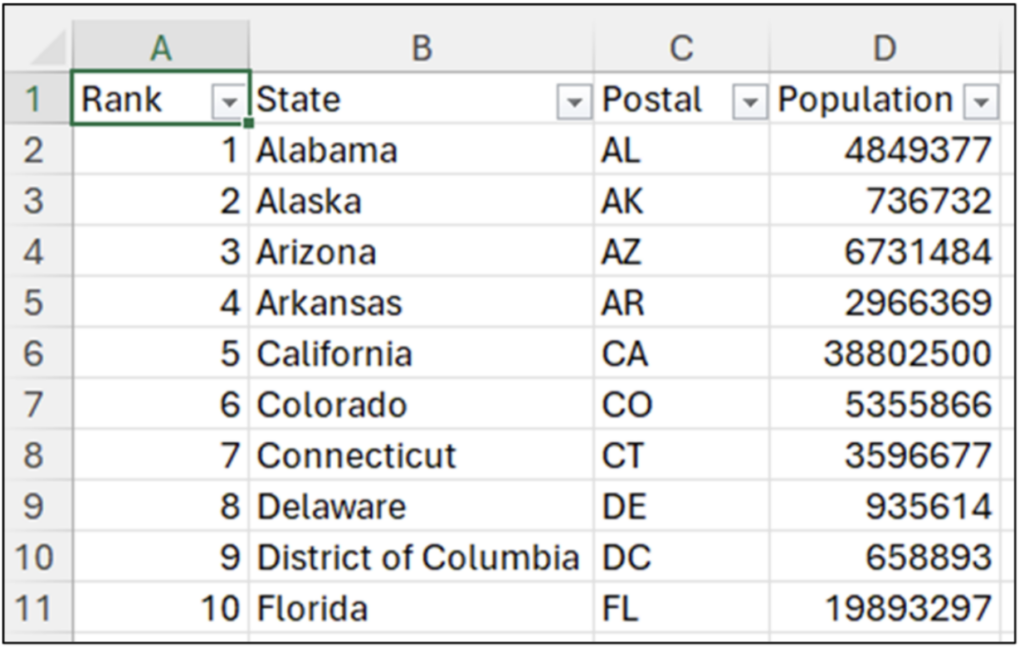
图 08 - 导入的美国各州人口数据
数据集人口列的平均值约为 620 万。平均值是在给定数字列的情况下计算典型值的一种方法。
虽然平均值无疑是有用的,但它并不能让我们完全了解数据的分布情况。我们想知道的是数据是如何分布的。
以下问题与数据的分布方式有关
回答这些问题的一种方法是对各个值进行统计。使用 Excel,您可以使用排序的数据透视表快速完成统计
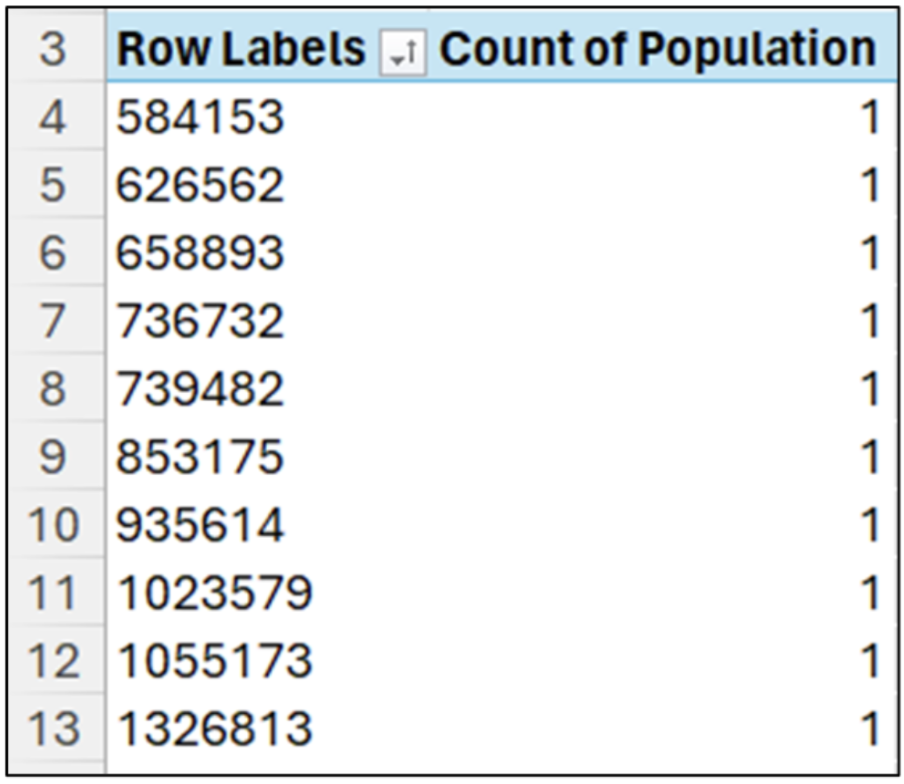
图 09 - 对人口列的值进行统计
对数值数据进行统计意味着找到每个唯一值在该列中出现的次数。
就人口列而言,每个值都是唯一的(即,每个值只出现一次)。我们已经在图 09 中看到,有许多值远远小于 620 万。
向下滚动统计列表显示,超过一半的值小于平均值(即,52 个值中的 34 个值)。

图 10 - 52 个人口值中有 34 个小于平均值
对人口列的值进行统计已经向我们展示了两件事
修复第二件事相对容易。
随着数字列的大小增加,您通常会看到更多唯一值。与其统计各个值,更常见的是使用分箱来定义要统计的值范围。
统计的是每个分箱内有多少列值。Excel 数据透视表分组提供了一种对数字列实现分箱的方法。
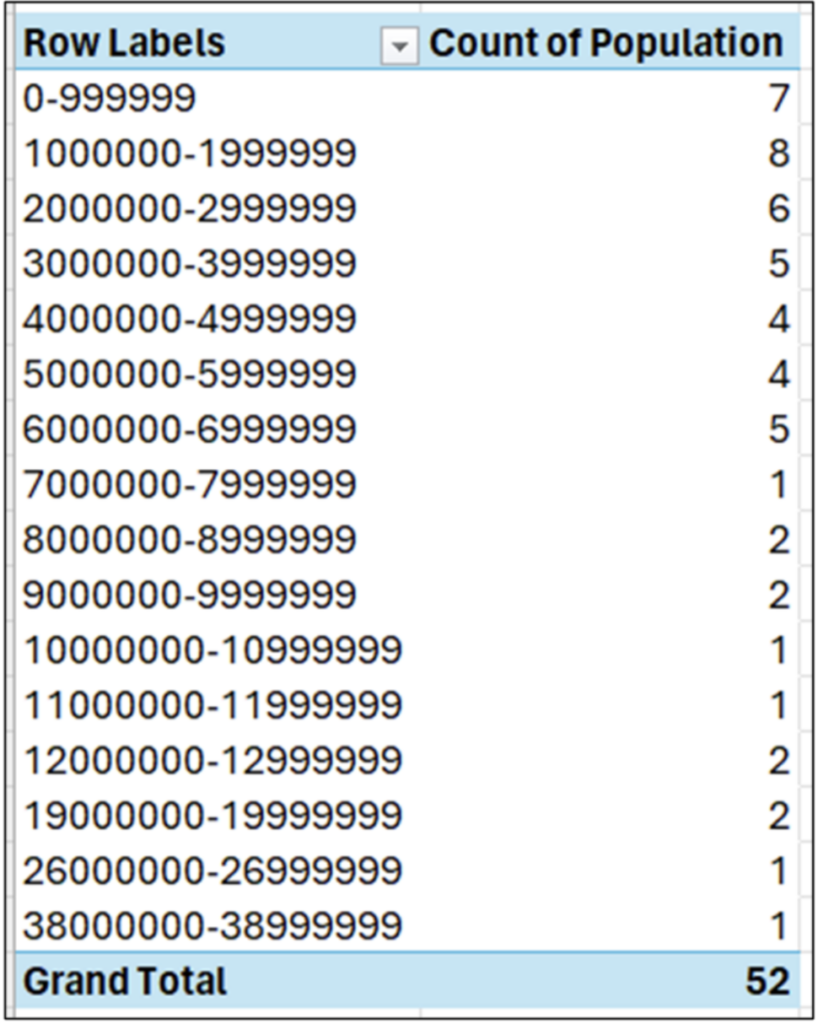
图 11 - 对人口列进行分箱
图 11 说明了分箱的力量。例如,我们可以快速看到,一半的数据(即 52 个值中的 26 个值)小于 400 万 - 明显小于 620 万的平均值。
虽然分箱很有用,但我们仍然使用表格来分析数字的分布情况。虽然表格无疑很有用,但它们不是检测数据模式的最佳选择。
人类更善于使用可视化来检测模式。
直方图可视化分组的数值数据。直方图是用于直观分析数字列的默认方法。如果你曾经上过统计学课程,你肯定见过直方图。
微软了解可视化数据分析对任何专业人士的价值,并通过默认包含对 Python 强大数据可视化库的访问来简化 Excel 用户的操作。
在 Excel 功能区中,访问公式选项可以查看默认包含哪些 Python 库。
图 12 - 查看默认包含的 Python 库
Python 预览初始化选项显示了许多库。
图 13 - 默认 Python 库
在本系列博文中,我们将使用 *seaborn* 和 *matplotlib.pyplot* 库进行数据可视化。
*seaborn* 库已成为 Python 数据可视化的首选,因为它易于使用。
使用 *seaborn*,你可以快速创建强大的数据可视化,而这些可视化使用 Excel 的开箱即用功能难以或无法创建。
虽然 Microsoft Excel 支持创建直方图,但其功能有限。此外,使用 *seaborn* 通常比使用 Excel GUI 界面更快。
第一步是从 Excel 的“开始”功能区打开 Excel Labs Python 编辑器。

图 14 - 访问 Excel Labs Python 编辑器
注意 - 如果没有 Python 编辑器,所有代码都可以在公式栏中通过 *PY()* 函数输入。
在本博文中,我们将使用 Python 代码工作表来编写代码,因为它提供了比传统 Excel 公式栏更丰富的编码体验。
图 15 - 使用 Python 代码工作表进行编码
在 Excel Labs 加载项中,单击 *在 B1 中添加 Python 单元格* 将打开 Python 编辑器。输入以下代码将美国州人口数据集加载为 *pandas* DataFrame。
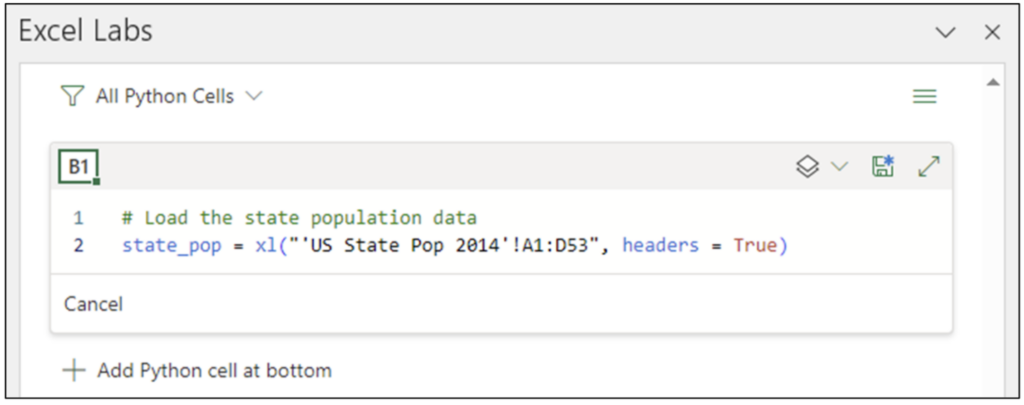
图 16 - 加载美国州人口数据
注意 - 如果你使用的是来自 *'US State Pop 2014'* 的 *'Raw Data'* 工作表,请确保更改上面的代码为 *'Raw Data.'*。
单击 Python 编辑器中的磁盘图标将执行代码。
图 17 - 执行 Python 代码
执行代码后,你可以检查 Python 编辑器中的 *Python 输出* 以查看 DataFrame 的预览。
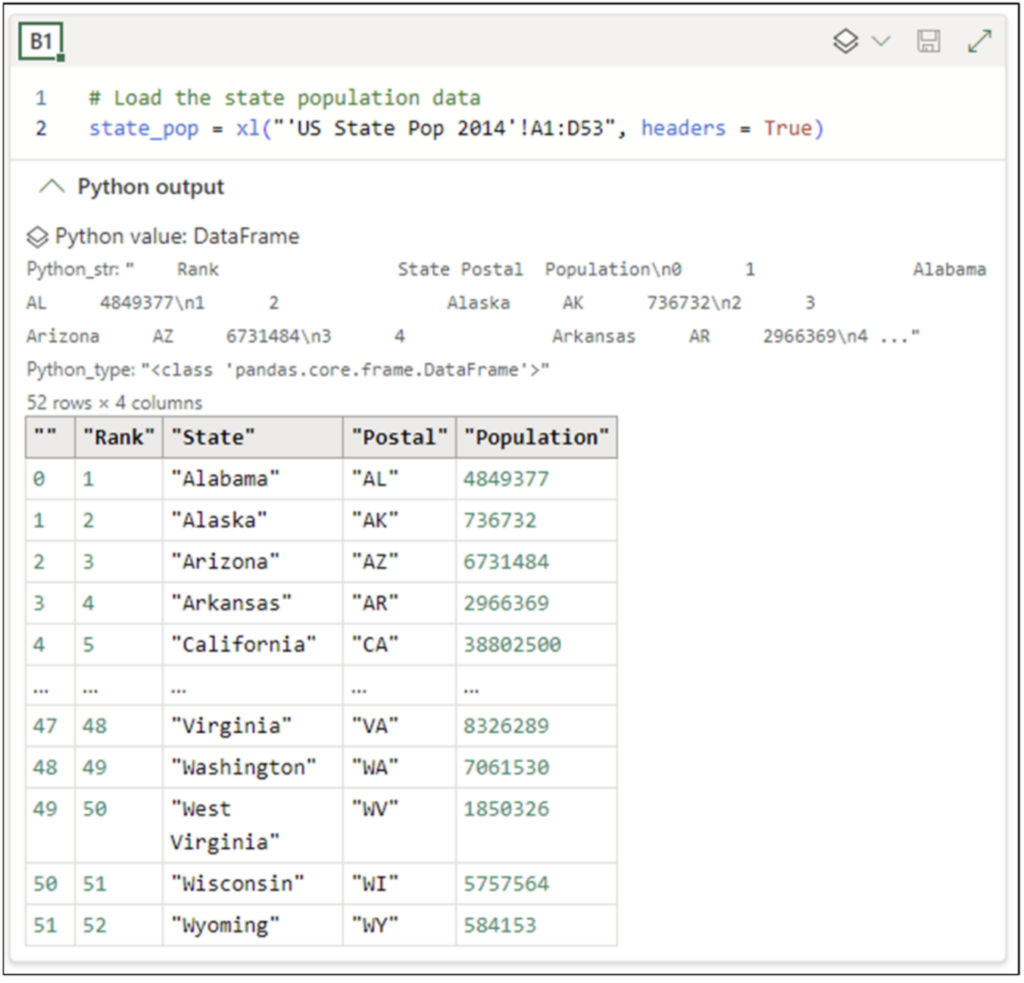
图 18 - 加载的 DataFrame 的预览
在 Python 编辑器中,单击 *在底部添加 Python 单元格* 将打开一个新的 Python 编辑器窗口,用于单元格 B2。以下 Python 代码演示了如何创建 *人口* 列的直方图。
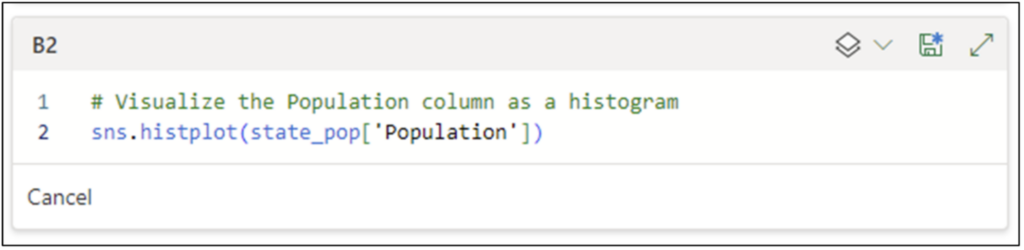
图 19 - 用于创建直方图的 Python 代码
上面的代码使用 *seaborn* 库中的 *histplot()* 函数。可以通过 Microsoft 默认提供的 *sns 别名* 访问该函数。
在运行单元格 B2 中的 Python 代码之前,应通过单击向下箭头将输出更改为 *转换为 Excel 值*。
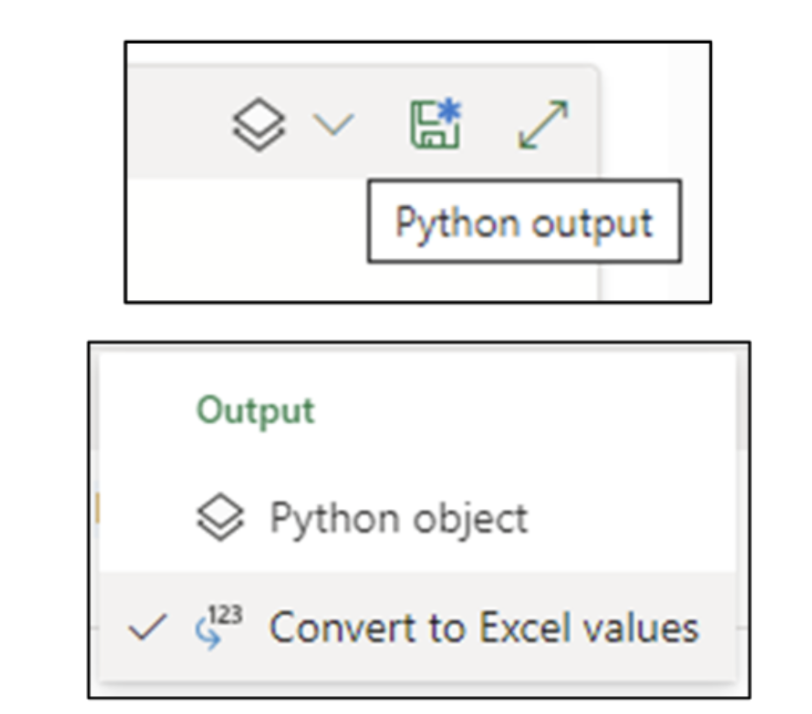
图 20 - 将 Python 单元格输出更改为 Excel 值
执行单元格 B2 中的 Python 代码将在单元格内生成一个直方图。扩展单元格的大小可以清楚地看到直方图。
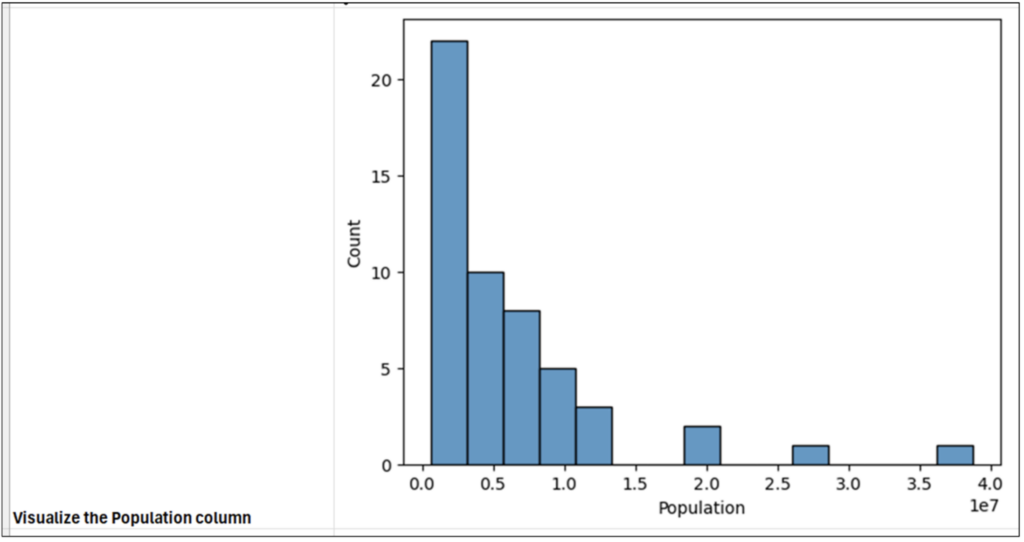
图 21 - 你的第一个直方图
不幸的是,使用 *histplot()* 函数默认生成的直方图存在一些问题。因此,让我们编写一些代码来改进我们的直方图。
虽然图 21 中所示的直方图在技术上没有任何错误,但可以通过以下两种方法进行改进。
将以下代码添加到单元格 B2 将使 x 轴的值从科学计数法转换为整数。该代码使用 *pyplot* 库中的 *ticklabel_format()* 函数,使用 *plt 别名*。
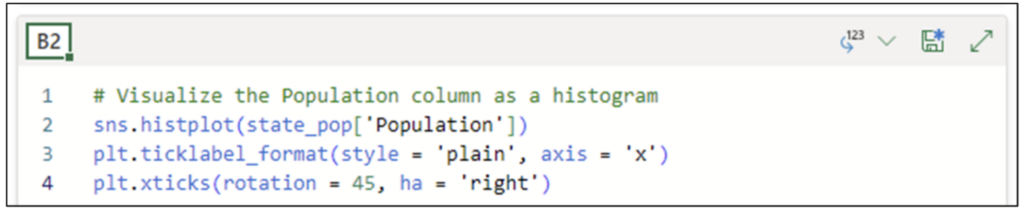
图 22 - 将 x 轴更改为整数
执行 B2 中的代码将生成以下更新的直方图。
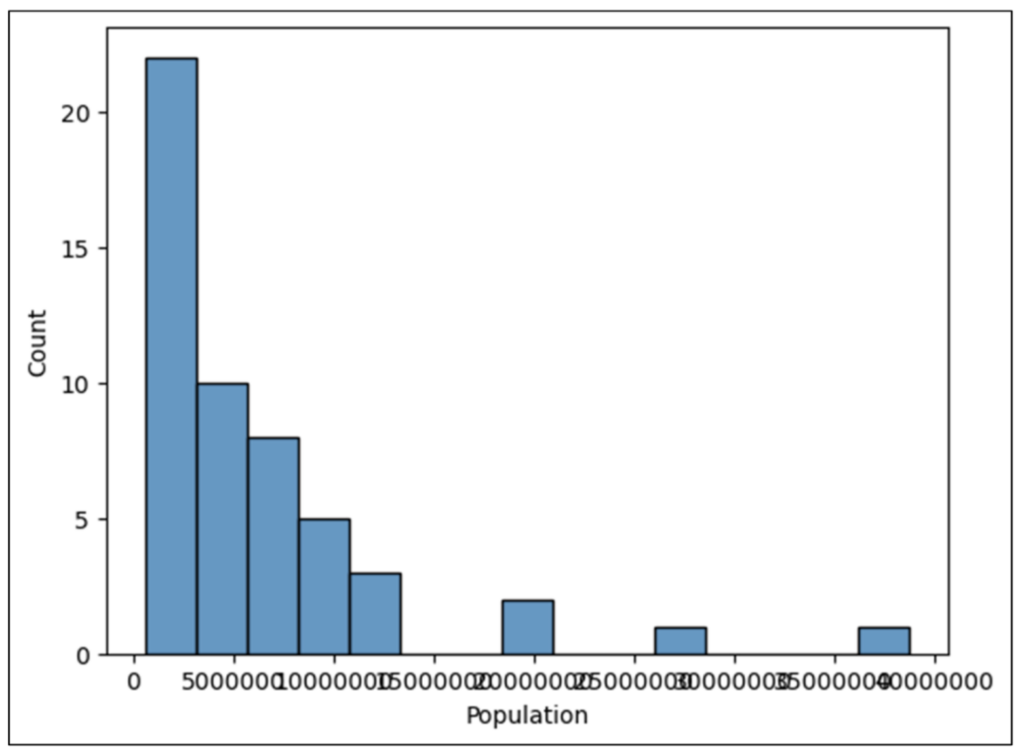
图 23 - 更新的直方图
不幸的是,整数的大小使 x 轴无法读取。添加代码使用 *pyplot* 的 *xticks()* 函数将使 x 轴标签向右旋转 45 度。
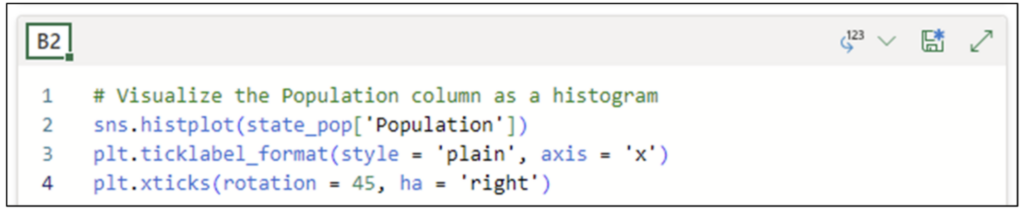
图 24 - 用于旋转 x 轴标签的代码
运行图 24 中的代码将生成以下直方图。
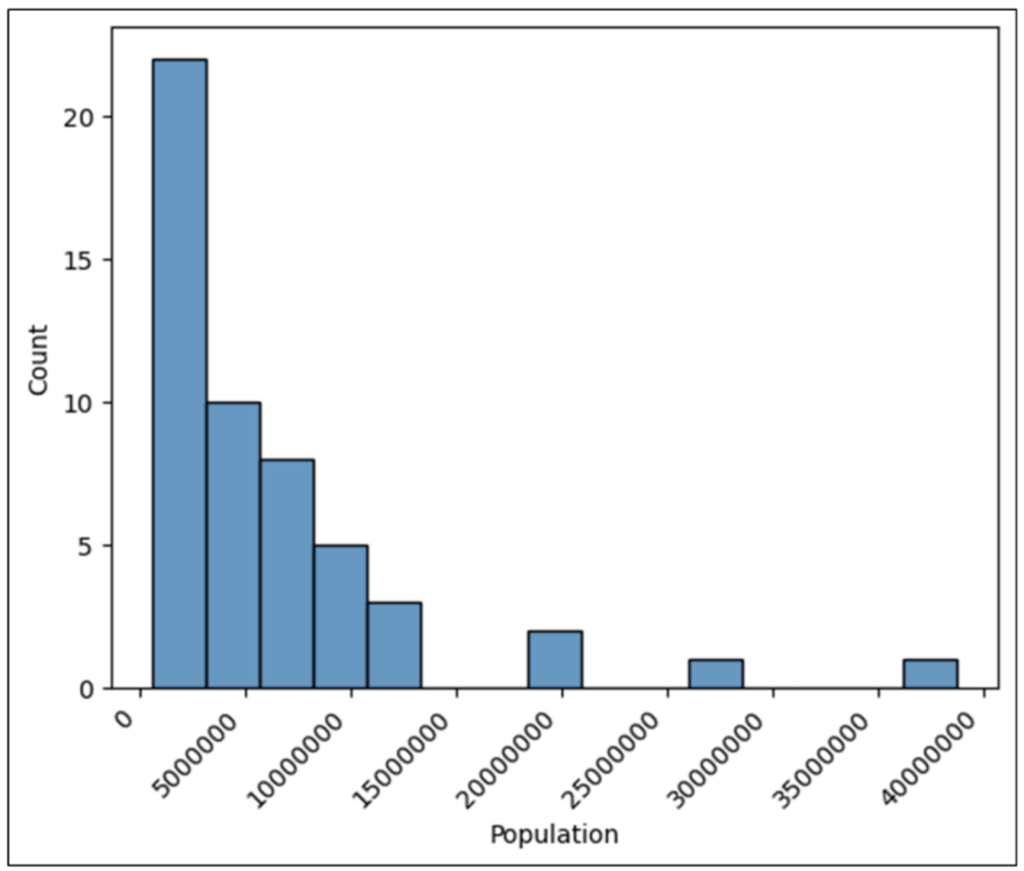
图 25 - 带有旋转标签的直方图
对直方图的最后改进是添加一条与人口列值的平均值相对应的垂直线。使用 *pyplot* 的 *axvline()* 函数将该线添加到直方图中。
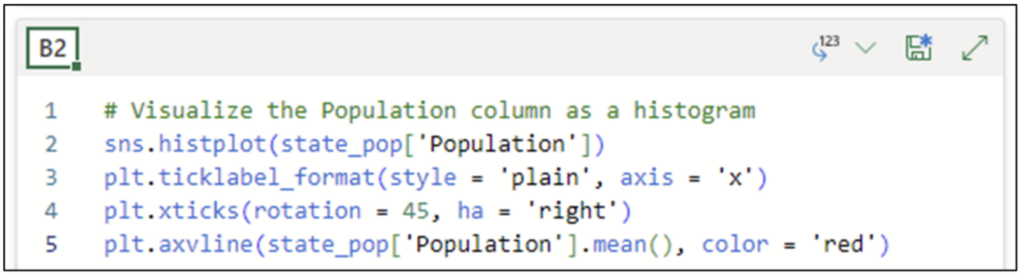
图 26 - 在直方图中添加平均值线
图 26 中的代码使用 *mean()* 方法。此方法计算一列数字的算术平均值。将平均值视为计算平均值的另一种名称。
执行图 26 中的代码将生成最终版本的直方图,该直方图将用于分析。
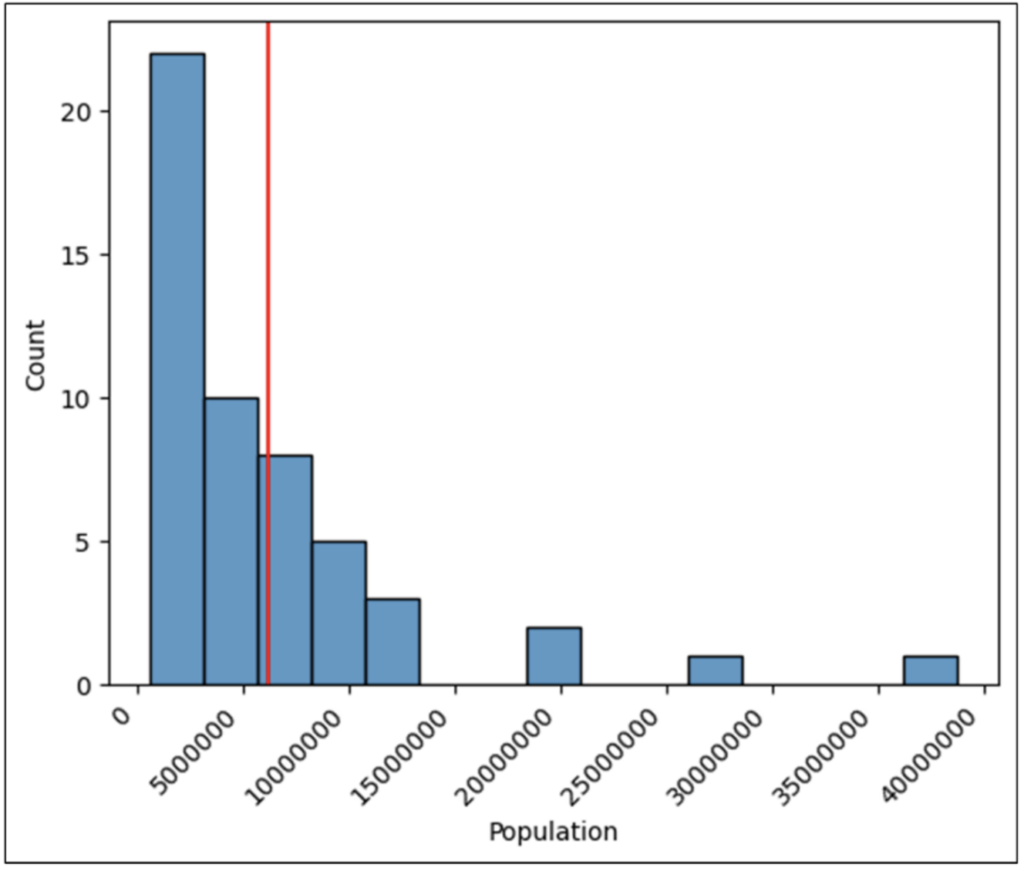
图 27 - 用于分析的最终直方图
分析直方图时,您正在检查可视化以了解以下特征。
以下小节将使用最终版本的直方图来解决每个特征。
直方图的 **范围** 是从最高值到最低值所描绘的值范围。
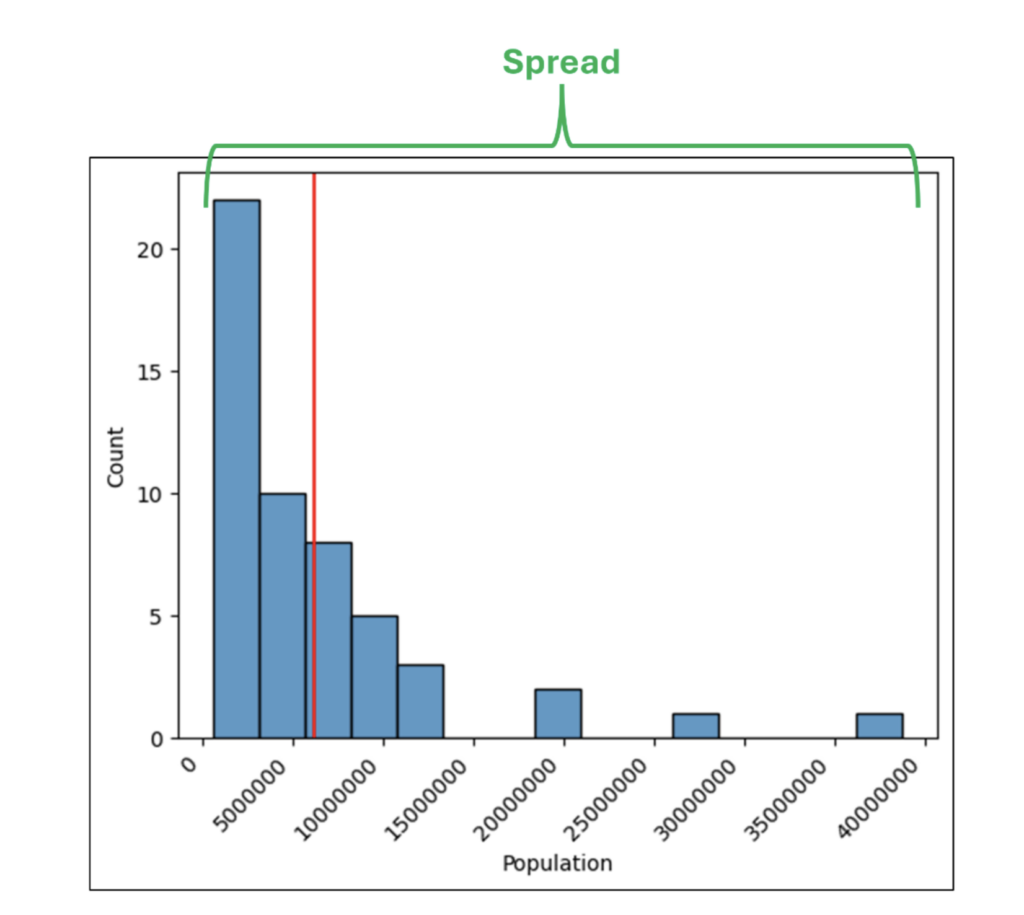
图 28 - 人口直方图的范围
直方图的范围提供了对数值数据分布的初步见解。
通过检查图 28 中的范围,我们可以看到美国各州的人口从不到 100 万到大约 3800 万不等。
检查范围还告诉我们,人口超过 1500 万的美国州很少,并且分布中存在很多间隙(例如,没有美国州的人口在 3000 万到 3500 万之间)。
检查直方图的范围有助于回答以下问题。
回答上述问题通常需要领域专业知识/知识。
直方图的 **中心** 代表一组数值数据的典型值(例如,DataFrame 中的一列)。
统计学家将这种典型值的理念称为位置度量或集中趋势。
最常用的位置度量是平均值(即平均值),尽管也会使用其他度量(例如,中位数)。
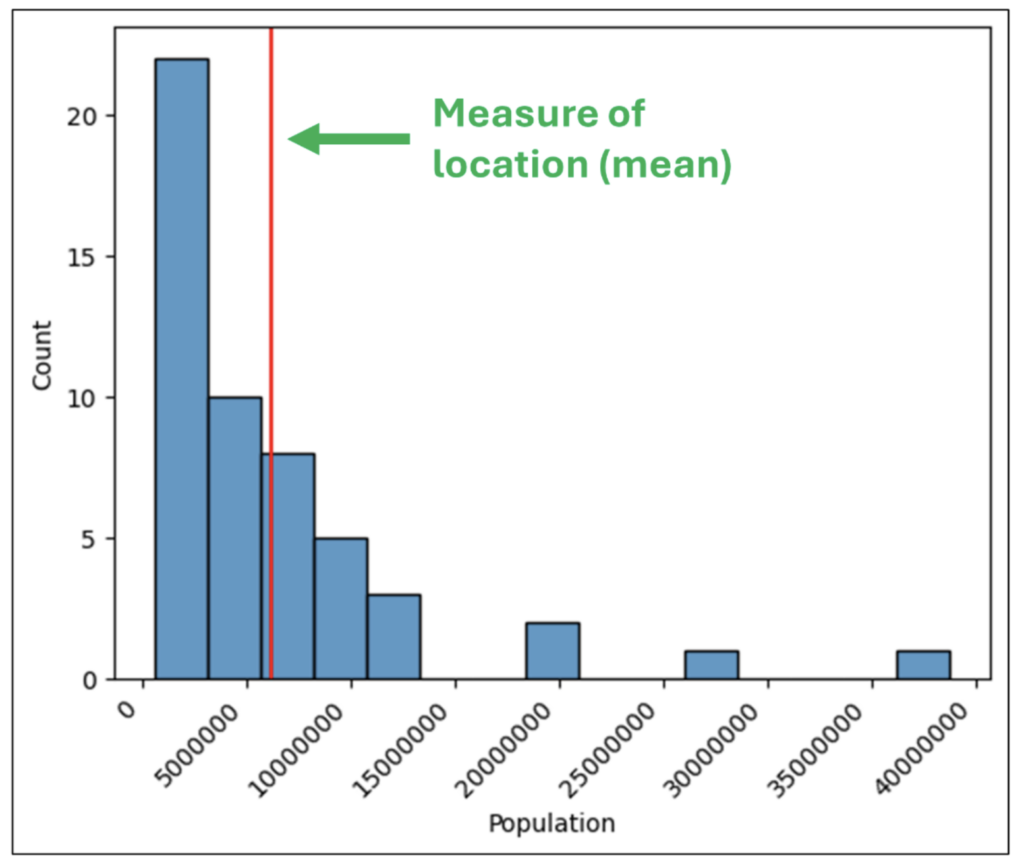
图 29 - 直方图的中心
检查图 29 中描绘的形状表明,大多数值都集中在直方图的左侧,并且低于平均值。
换句话说,平均值并不代表数据的典型值(例如,因为像加利福尼亚州这样的几个大州会抬高平均值)。
此外,通过检查图 29 中描绘的形状,我们可以得出结论,大多数美国州的人口偏向于较小,我们需要一种更好的方法来代表典型值(例如,中位数)。
直方图的 **形状** 代表了直方图范围内的值的密度。
检查直方图的形状有助于回答以下问题。
让我们将上述问题应用到直方图中。
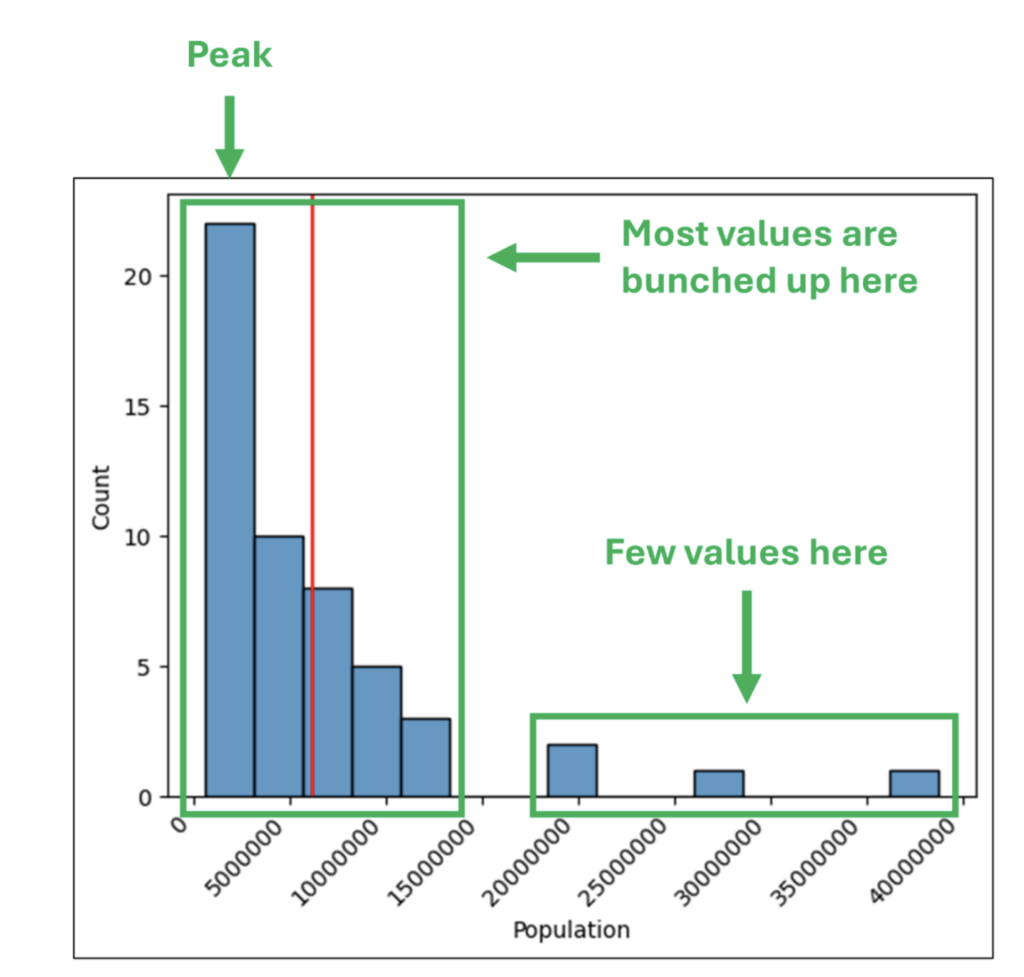
图 30 - 直方图的形状
图 30 中描绘的形状说明了美国各州的人口大多较小,少数州的人口不成比例地多。
例如,佛罗里达州、德克萨斯州和加利福尼亚州的人口总和占美国总人口的 26.6%。
直方图的形状不仅告诉我们很多关于数值数据分布的信息,而且还为我们提供了进一步调查的线索。
考虑到数据集的性质,一项潜在的调查可能是评估内陆州是否主要人口较少。
直方图的形状主要由所用 bin 的大小决定。
通常,减小 bin 的大小会导致更多通常不太高的条形,而增大 bin 的大小会导致更少的条形,但这些条形更高。
*binwidth* 参数可用于控制直方图中 bin 的大小(即宽度)。以下代码使用 1,000,000 的 *binwidth*。

图 31 - 将 binwidth 更改为 1,000,000
以下是生成的直方图。
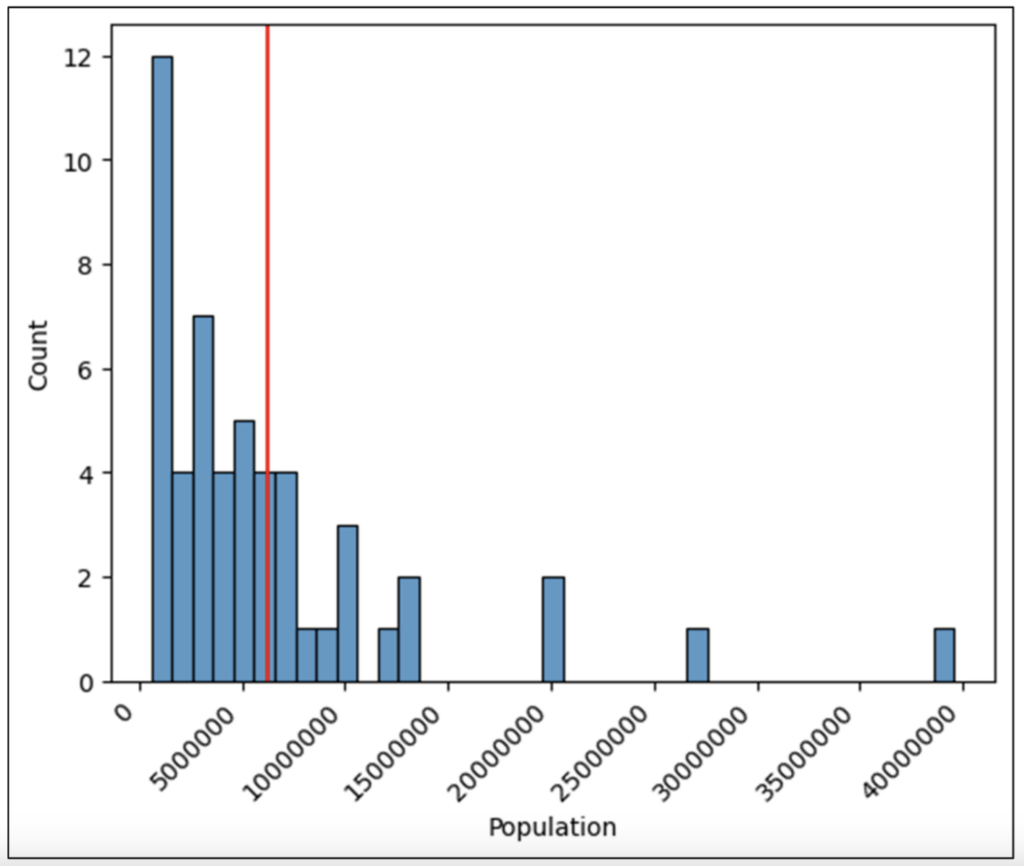
图 32 - bin 大小为 1,000,000 的直方图
对于任何给定的数据集,关于 bin 应该有多大都没有明确的规则。通常根据主题专业知识尝试几种 bin 大小。
如果你有兴趣了解一些关于确定直方图 bin 大小的经验规则,请查看这篇文章。
直方图是直观分析数值数据最基本的方法,但并非在所有情况下都是最好的方法。
以下是一个示例 - 您希望比较按产品线划分的销售订单金额的分布。
本系列的下一篇文章将教你如何使用箱线图进行此类分析。如果你喜欢本系列博客,请查看我的自定进度认证课程,Anaconda 认证:使用 Excel 中的 Python 进行数据分析。
下次再见,保持健康,快乐的数据侦探!
与我们的专家之一交谈,为您的 AI 之旅找到解决方案。

